Command Palette
Search for a command to run...
30 Scholars Jointly Published a Nature Review, Reviewing 10 Years and Deconstructing How AI Reshaped the Scientific Research Paradigm

Scientific discovery is a complex process involving several interrelated stages, including hypothesis formation, experimental design, data collection and analysis. In recent years, the integration of AI and basic scientific research has become increasingly profound. With the help of AI, scientists have been able to accelerate the progress of scientific research and promote the implementation of scientific research results.
The authoritative journal "Nature" published a paper by Hanchen Wang, a postdoctoral fellow at the School of Computer Science and Gene Technology at Stanford University, Tianfan Fu from the Department of Computer Science and Engineering at Georgia Institute of Technology, and Yuanqi Du from the Department of Computer Science at Cornell University, and 30 others.This paper reviews the role of AI in basic scientific research over the past decade and points out the remaining challenges and shortcomings.
This paper summarizes the papers.
Read the full paper:https://www.nature.com/articles/s41586-023-06221-2

Case study on the integration of AI and basic scientific research Image source: Original paper, translated into Chinese by HyperAI
01 AI-assisted scientific research data collection and organization
As the scale and complexity of data collected by experimental platforms continue to increase, real-time processing and high-performance computing (HPC) are necessary to selectively store and analyze the rapidly generated data.
Data selection
Taking particle collision experiments as an example, more than 100 TB of data is generated per second, which poses a great challenge to existing data transmission and storage technologies. In these physical experiments, metadata exceeding 99.99% must be detected in real time and irrelevant data must be discarded.Technologies such as deep learning and automatic encoder closing can help identify abnormal events in similar scientific research and greatly reduce the pressure of data transmission and processing.
Currently, these technologies have been widely used in fields such as physics, neuroscience, earth science, oceanography and astronomy.
Data Annotation
Pseudo-labelling and label propagation algorithms are of great significance in replacing tedious data labeling. They enable the model to automatically label massive data with only a small amount of accurately labeled data.
Data Generation
Through automatic data augmentation and deep generative models, additional synthetic data points can be generated to expand the training data.Experiments have shown that generative adversarial networks (GANs) can synthesize realistic images in many fields.These range from particle collision events, pathological sections, chest X-rays, magnetic resonance contrast, three-dimensional (3D) material microstructures, protein functions to gene sequences.
Data Optimization
AI can significantly improve image resolution, reduce noise, and eliminate errors when measuring roundness, thereby maintaining high accuracy consistency across sites.Application examples include visualizing regions of space and time such as black holes, capturing physical particle collisions, improving the resolution of living cell images, and better detecting cell types in different biological environments.
02 Learning meaningful representations of scientific data
Deep learning can extract and optimize meaningful representations of scientific data at various levels of abstraction. High-quality representations should retain as much information about the data as possible while remaining concise and accessible. Here are three new strategies that meet these requirements:Geometric priors, self-supervised learning, and language modelling.
Geometric priors
Geometry and structure are crucial to scientific research. Symmetry is an important concept in geometry, and important structural properties are stable in spatial directions and do not change. In scientific image analysis, integrating geometric priors into learned representations has been proven to be effective.
Geometric Deep Learning
Graph neural networks have become the main method for deep learning on datasets with underlying geometric and relational structures. Depending on the scientific questions, researchers have developed various graph representations to capture complex systems.
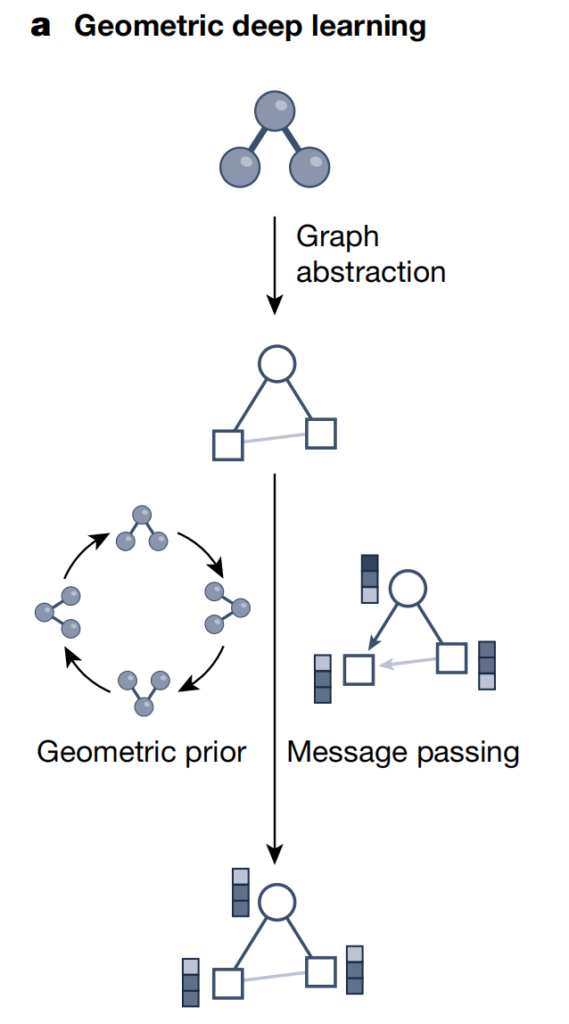
As shown in the figure above, geometric deep learning uses graph structures and neural information transfer strategies to integrate the geometric, structural, and symmetry information of scientific data such as molecules/materials. This method exchanges neural information along the edges in the graph structure to generate potential representations (embedded vectors) while considering other geometric priors (such as invariance and arithmetic progression constraints). Therefore,Geometric deep learning can incorporate complex structural information into deep learning models, thereby better understanding and processing underlying geometric data sets.
Self-supervised learning
Self-supervised learning enables the model to understand the general features of the dataset without relying on explicit labels. It can be used as a key preprocessing step to learn transferable features from large-scale unlabeled data before fine-tuning the model to perform downstream tasks. Such a pre-trained model with a broad understanding of scientific research fields is a general purpose predictor.It can be adapted to a variety of tasks, thereby improving efficiency and surpassing purely supervised methods.
As shown in the figure above, effectively representing different samples such as satellite images requires capturing both their similarities and differences. Self-supervised learning strategies such as contrastive learning can achieve this goal by generating enhanced peer data, aligning positive data, and separating negative data pairs. This iterative process strengthens the embedding, resulting in informative latent representations and better performance in downstream prediction tasks.
Language Modeling
Masked-language modelling is a popular method for self-supervised learning of natural language and biological sequences (see the figure below).

Natural language processing and biological sequence processing influence each other.During training, the goal is to predict the next token in the sequence, while in mask-based training, the self-supervised task is to use the bidirectional sequence context to recover the masked tokens in the sequence. Protein language models can encode amino acid sequences, capture structural and functional properties, and assess the evolutionary fitness of viral variants. When dealing with biochemical sequences, chemical language models can effectively explore the vast chemical space.
As shown in the figure above, masked language modeling can effectively capture the semantics of sequence data, such as natural language and biological sequences. This method feeds the masked elements in the input into the Transformer module, which includes preprocessing steps such as position encoding. The gray line represents the self-attention mechanism, and the color depth reflects the size of the attention weight. It combines the representation of the non-masked input to accurately predict the masked input. This method produces high-quality sequence representations by repeating this automatic completion process in many elements of the input.
Transformer Architecture
Transformer unifies graph neural networks and language models, dominates natural language processing, and has been successfully applied to fields such as seismic signal detection, DNA and protein sequence modeling, modeling the effects of sequence variation on biological functions, and symbolic regression.
Neural Operators
By learning a mapping between function spaces, the neural operator is discretized invariant and can work on any input discretization and converge to a limiting value as the grid is refined. Once a neural operator is trained, it can be evaluated at any resolution without retraining.
03 Generate AI-based scientific hypotheses
AI can generate hypotheses by identifying candidate symbolic expressions from noisy observations. They can help design objects, learn the Bayesian posterior probability of hypotheses, and use it to generate hypotheses that are compatible with scientific data and knowledge.
Black-box predictor of scientific hypotheses
Weakly supervised learning can be used to train models where noisy, limited, or imprecise supervision is used as the training signal.
AI methods have been trained with high-fidelity simulations and have been used to effectively screen large-scale molecular libraries. In genomics, the Transformer architecture is trained to predict gene expression values using DNA sequences, thereby identifying gene mutations. In protein folding, AlphaFold2 can predict the 3D atomic coordinates of proteins from amino acid sequences. In particle physics, identifying the charm quarks inherent in protons involves screening all possible structures and fitting all potential structures to experimental data.
In addition to forward problems, AI is also increasingly being used to solve inverse problems.
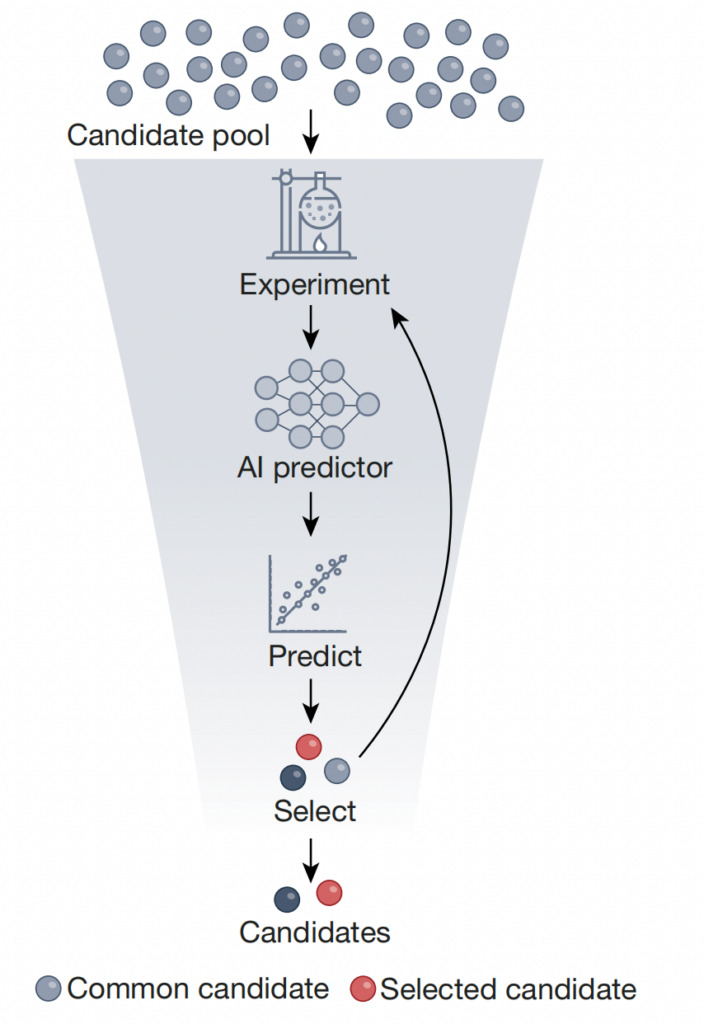
As shown in the figure above, high-throughput screening refers to the use of AI predictors trained on experimentally generated datasets to screen out a small number of target objects with ideal characteristics.This reduces the total size of the candidate library by several orders of magnitude.This approach can use self-supervised learning to pre-train the predictor on a large number of unscreened objects, and then fine-tune the predictor on a dataset of labeled readouts of screened objects. Laboratory evaluation and uncertainty quantification can complement this approach, thereby streamlining the screening process, making it more cost-effective and time-efficient, and ultimately accelerating the identification of candidate compounds, materials, and biomolecules.
Exploring combinatorial hypothesis spaces
Compared to traditional methods that rely on manually designed rules, AI strategies can be used to evaluate the reward of each search and identify search directions with higher value.
For optimization problems, evolutionary algorithms can be used to solve symbolic regression tasksCombinatorial optimization is also applicable to tasks such as discovering molecules with desirable drug properties, where each step in molecular design is a discrete decision process. In addition, reinforcement learning methods have been successfully applied to a variety of optimization problems, such as maximizing protein expression, planning hydropower in the Amazon, and exploring particle accelerator parameter space.
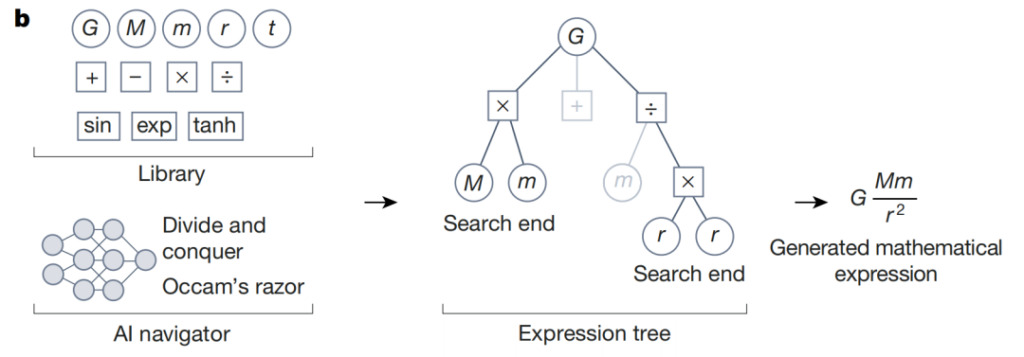
As shown in the figure above, during symbolic regression, AI navigator uses the rewards predicted by the reinforcement learning agent and design criteria such as Occam's razor to focus on the most promising elements of the candidate hypotheses. The following example illustrates the reasoning process for the mathematical expression of Newton's law of gravity. Low-scoring search paths are shown as gray branches in the symbolic expression tree. Guided by the actions associated with the highest predicted reward,This iterative process converges to a mathematical expression that is consistent with the data and meets the other design criteria.
Optimizing differentiable hypothesis spaces
Differentiable spaces are suitable for gradient-based methods, which can effectively find local optimal solutions.To enable gradient-based optimization, two approaches are commonly used:
* Use models like VAEs to map discrete candidate hypotheses into a latent differentiable space;
* Relax the discrete assumption into a differentiable object that can be optimized in a differentiable space (this relaxation can take different forms, such as replacing discrete variables with continuous variables, or using a soft version of the original constraints).
In astrophysics, VAEs have been used to estimate gravitational wave detector parameters based on pre-trained black hole waveform models. This method is 6 orders of magnitude faster than traditional methods. In materials science, thermodynamic rules are combined with autoencoders to design an interpretable latent space to identify crystal structure maps.
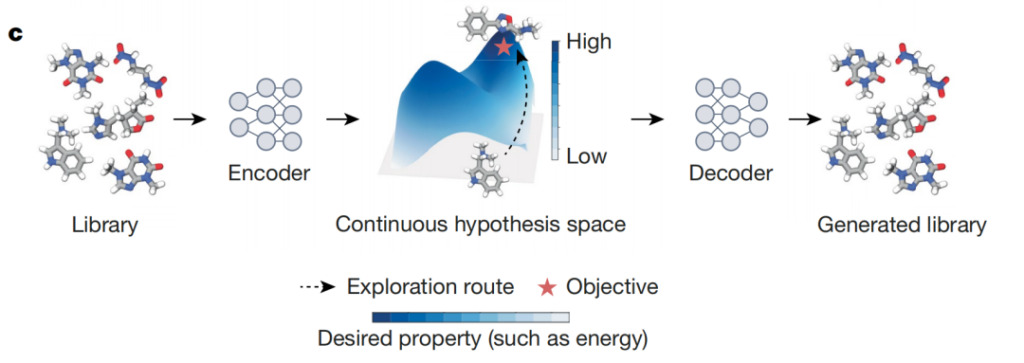
As shown in the figure above, AI differentiators are autoencoder models that map discrete objects (such as compounds) to points in a differentiable continuous latent space. This space allows the optimization of target objects, such as selecting compounds that maximize specific biochemical endpoints from a large chemical library. The ideal blueprint describes the learned latent space, and darker colors indicate areas where objects with higher prediction scores are concentrated. Using this latent space, AI differentiators can efficiently identify objects that maximize the expected properties marked with red stars.
04 AI-driven experiments and simulations
Computer simulations can replace costly laboratory experiments and provide more efficient and flexible testing possibilities.Deep learning can identify and refine hypotheses for efficient testing and enables computer simulations to link observations to hypotheses.
Efficiently evaluate scientific hypotheses
AI systems provide experimental design and optimization tools.These tools can augment traditional scientific methods, reduce the number of experiments required and save resources.
Specifically, AI systems can assist in two key steps of experimental testing: planning and guidance. AI planning provides a systematic approach to designing experiments, optimizing efficiency, and exploring unknown areas. At the same time, AI guidance directs the experimental process toward high-yield hypotheses, allowing the system to learn from previous observations and adjust the experimental process. These AI methods can be model-based (using simulations and prior knowledge) or model-free methods based solely on machine learning algorithms.
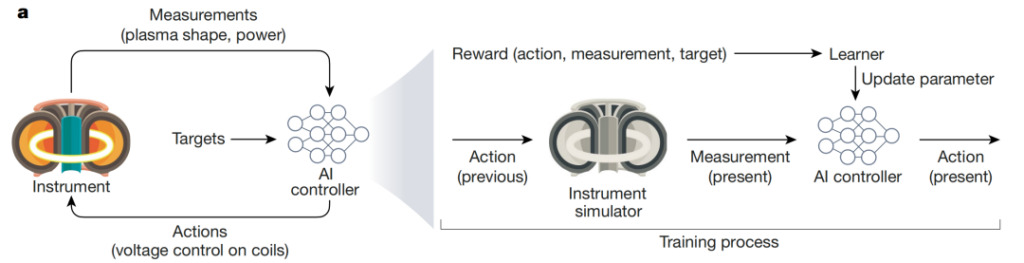
The figure above shows the use of AI to control complex and dynamic nuclear fusion processes: Degrave et al. developed an AI controller that can regulate nuclear fusion through magnetic fields in a tokamak reactor. The AI agent receives real-time measurements of electrical voltage levels and plasma configuration and takes actions to control the magnetic field to achieve experimental goals (such as maintaining normal power supply). The controller is trained through simulation and updates model parameters using a reward function.
Deriving observables from hypotheses using simulations
Existing computer simulation technology relies heavily on human understanding and cognition of the underlying mechanisms of the system. AI systems can enhance computer simulation by more accurately and efficiently adapting to the key parameters of complex systems, solving differential equations that can control complex systems, and modeling the states of complex systems.
Take molecular force fields as an example. Although they are interpretable, they are limited in the representation of various functions, and their generation requires strong inductive bias and rich scientific knowledge. In order to improve the accuracy of molecular simulations, AI-based neural potentials that adapt to expensive and precise quantum mechanical data have been developed to replace traditional force fields.
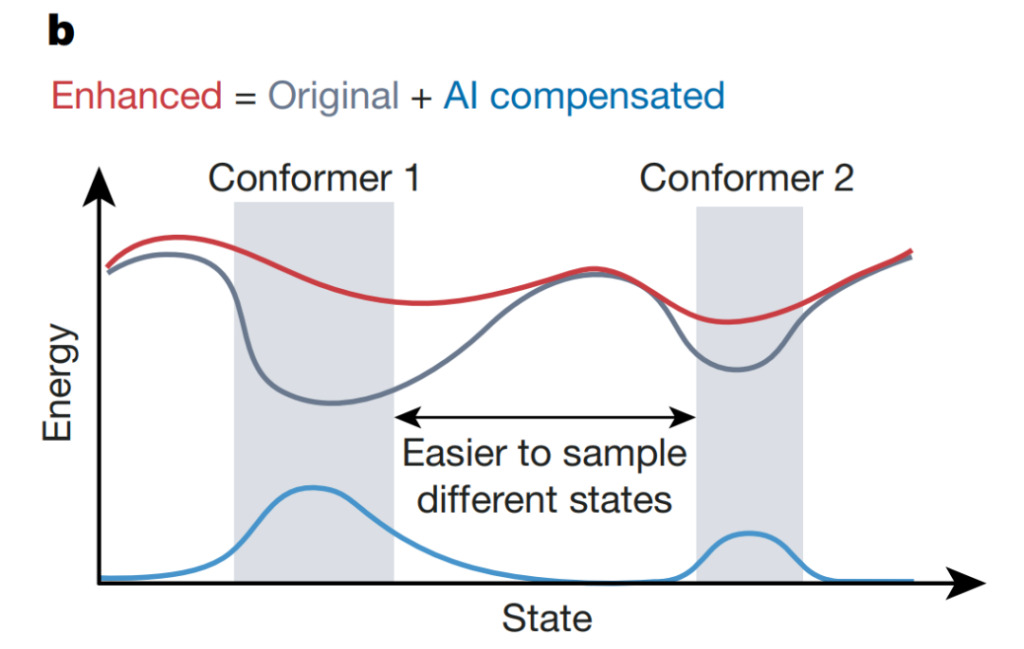
In computational simulations of complex systems, AI systems can accelerate the detection of abnormal events, such as transitions between protein conformational structures. As shown in the figure above, Wang et al. used a neural network-based uncertainty evaluator to guide the increase of potential energy that compensates for the original potential energy, allowing the system to escape from local minima (gray) and explore the configuration space faster. This approach can improve the efficiency and accuracy of simulations, thereby deepening the understanding of complex biological phenomena.
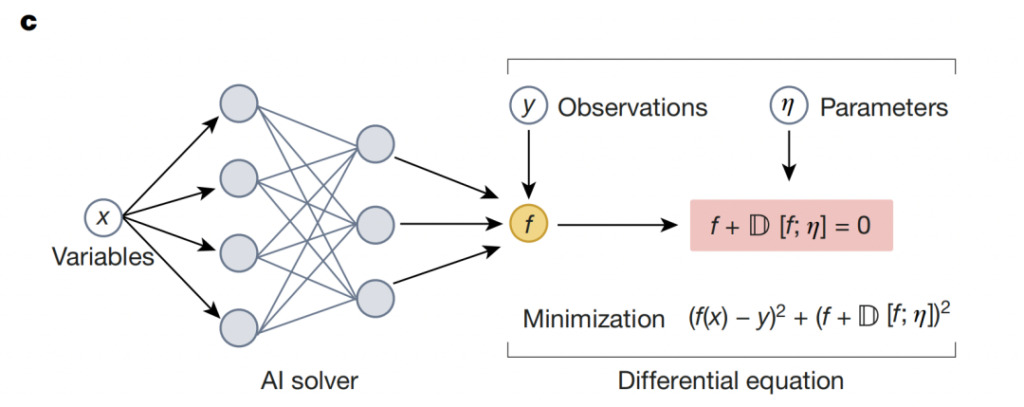
Neural solvers combine physics with the flexibility of deep learning:Building Neural Networks Based on Domain Knowledge
05 AI for Science: A Long Way to Go
AI systems contribute to scientific understanding, and have been shown to be able to study processes and objects that are difficult to visualize or detect, and to systematically come up with new ideas by building models from data and combining data with simulation and scalable computing. However, there are security and privacy issues to be addressed in the use of AI.This process still requires mature technology deployment.
To use AI responsibly in scientific research, researchers need to measure the uncertainty, error, and utility of AI systems. As AI systems continue to develop, AI is expected to open the door to scientific discoveries that were previously out of reach, but there is still a long way to go in terms of supporting theories, methods, software, and hardware infrastructure.
References:








