Command Palette
Search for a command to run...
Tsinghua University Uses Interpretable Machine Learning to Optimize Photoanode Catalysts to Help Photolysis of Water to Produce Hydrogen

Solar photoelectrochemical (PEC) decomposition of water is a method of efficiently converting solar energy into hydrogen energy and is a promising way to produce renewable energy. However, due to the influence of electrode properties and electrode defects, the efficiency of PEC reaction is low and requires the assistance of suitable co-catalysts. The PEC system composed of electrolytic cell, photoelectrode and co-catalyst is very complex, with many parameters and high cost for system optimization. To this end, Zhu Hongwei's research group at Tsinghua University used machine learning to analyze the BiVO4 The photoanode system was optimized. Machine learning can find the relationship between the photoanode, co-catalyst, and electrolytic cell based on previous experimental data. At the same time, explainable machine learning can identify the parameters that are most important for reaction performance and provide guidance for system optimization.
Author | Xuecai
Editor | Sanyang
Solar photoelectrochemical (PEC) water splitting is a method for efficiently converting solar energy into hydrogen and oxygen and is a promising way to produce renewable energy.
PEC water splitting requires a photoelectrode, which acts as the anode or cathode of the electrolytic cell, and a counter electrode, which acts as the cathode or anode of the electrolytic cell. The photoelectrode absorbs solar energy to drive the oxidation or reduction reaction of water, and the corresponding reduction or oxidation reaction simultaneously occurs on the counter electrode. To promote the separation of photogenerated carriers, a power source or photovoltaic cell is also required to provide bias for PEC.
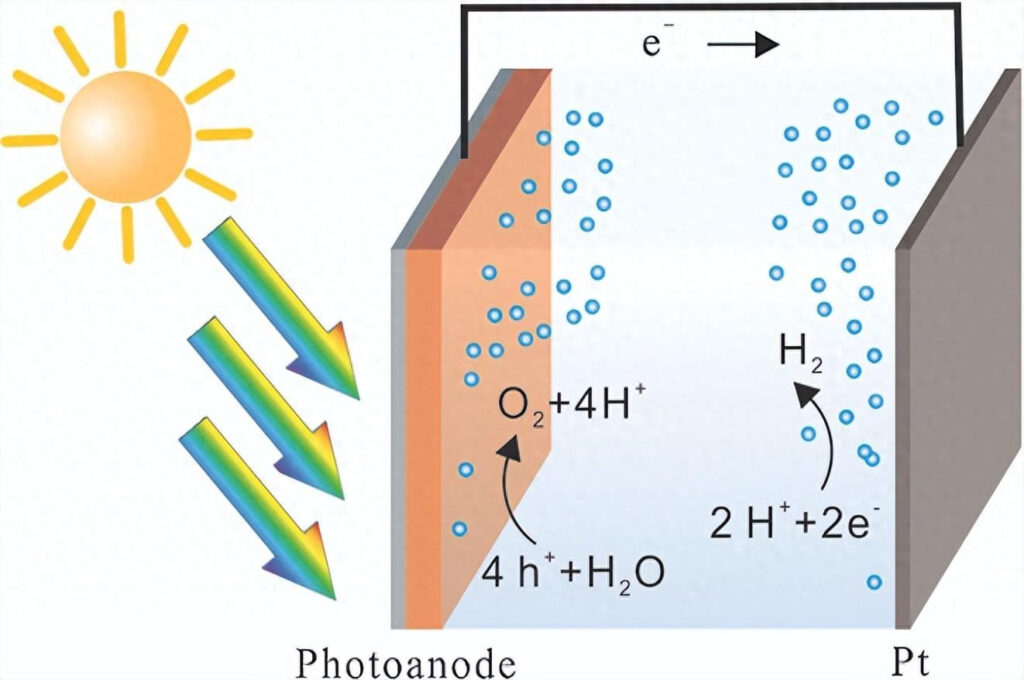
The efficiency of PEC water splitting is limited by defects in the photoelectrode, such as carrier recombination and instability at low bias.A suitable co-catalyst can promote the separation of photocarriers., forming a heterojunction with the photoelectrode and promoting light absorption, reducing surface energy to accelerate the reaction, inhibiting chemical corrosion of the electrode, accelerating electron transmission, etc., thereby improving the reaction efficiency.
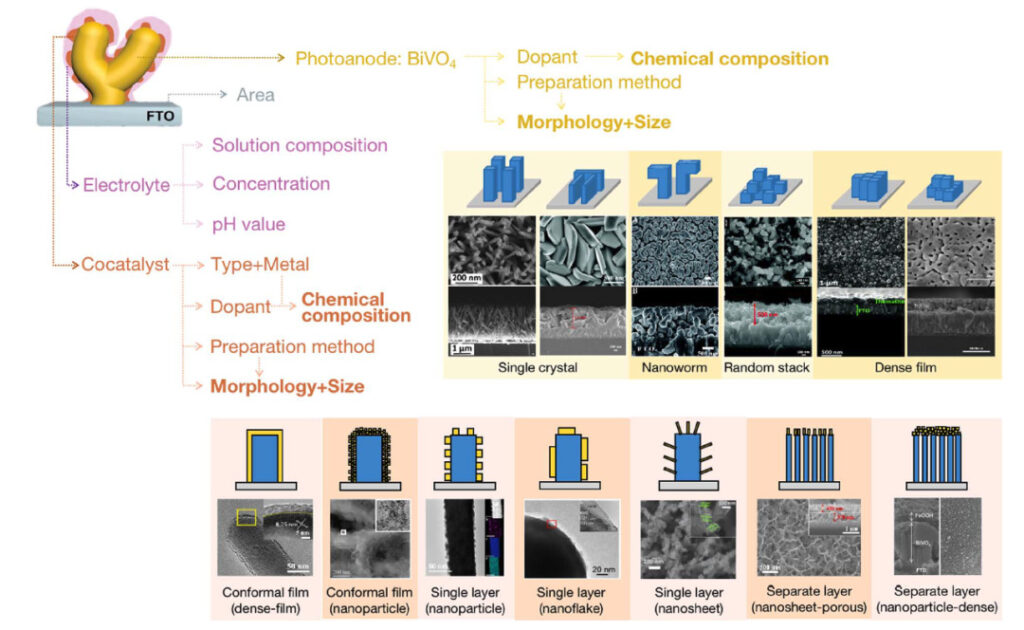
Researchers have discovered a variety of co-catalysts that can promote PEC reactions, including metals, metal oxides, metal-free co-catalysts, dual catalysts, etc. The efficiency of these co-catalysts is affected by their physical and chemical properties, such as chemical composition, morphology, crystal form, etc. In addition, the reaction conditions of the electrolytic cell, such as electrode type, electrolyte concentration, pH, etc., will also affect the efficiency of the co-catalyst.
The reaction system is very complex. How to optimize the parameters of a given photoelectrode and select the appropriate co-catalyst requires a lot of trial and error experiments.In particular, the optimal thickness of the co-catalyst is difficult to select, as it is affected by both the electrode and the co-catalyst. However, if there is enough data, machine learning can quickly achieve this process.
Based on this,Zhu Hongwei's research group at Tsinghua University used machine learning (ML) to optimize BiVO4 Co-catalysts for photoanodesFirst, the basic influencing factors and mechanisms of photoanode catalytic systems were discussed. Then, a database was created based on the experimental data of previous studies and a machine learning model was trained.Find BiVO4 Relationship between photoanode, co-catalyst and electrolytic cellFinally, based on the interpretability of machine learning models,Find the features most closely associated with reaction efficiency, to guide BiVO4 Selection of photoanode co-catalysts. This result has been published in "Journal of Materials Chemistry A".

This result has been published in Journal of Materials Chemistry A.
Paper link:
https://pubs.rsc.org/en/content/articlelanding/2023/TA/D3TA04148D
Experimental procedures
Dataset Literature research
The input of the machine learning model is 12 reaction influencing factors and electrode area, and the output is the increase in photocurrent density at 1.23 V (vs RHE).
From 84 papers, 112 BiVO groups were found4 Experimental data of photoanode catalytic water splitting, composition data setIt is worth noting that BiVO4 The morphology of photoanode was simplified into 4 categories, including single crystal, nanoworm, random stacking and dense film, while the morphology of co-catalyst was simplified into 3 categories, including homogeneous film, monolayer film and separation film.
The output of the model, i.e. the enhancement of photocurrent density by the co-catalyst, is classified into three levels: low (0), medium (1), and high (2).
Data processing Screening and Dimensionality Reduction
After data collection is completed, the data is preprocessed, including the following 7 steps:
1.Data cleaning. Data cleaning is the process of correcting, repairing and clearing data. 25 sets of data were excluded due to unrepresentativeness;
2.Data Interpolation. The data provided by many studies are quite limited, and there is a lack of continuity between the data of different studies. Therefore, the researchers supplemented the missing co-catalyst thickness through multiple difference chain equations (MICE) based on the reaction conditions, photoanode morphology and size;
3.Data Partition. 70% of the dataset was divided into a training set for the machine learning model and 30% for testing. Due to the limited amount of data, the researchers used K-Fold cross-validation to verify the accuracy of the model;

4.Data Conversion. This process converts the dataset into a set that is readable by the model. After converting the categorical data into numerical data using One-Hot Encoding, the input variable has 109 dimensions;
5.Data Normalization. When the range of numerical data is inconsistent, it is necessary to convert the data to the same range through normalization so that different input variables have the same weight in the set. This study uses StandardScaler for data normalization;
6.Data Balance. In this study, the data distribution of different output categories is obviously unbalanced, among which 0 accounts for about 34%, 1 accounts for about 52%, and 2 accounts for about 14%. Oversampling and undersampling methods are commonly used to reprocess samples. The former is to add data to a small sample set, and the latter is to delete data from a large sample set. This study uses the SMOTE oversampling algorithm for data balancing;
7.Dimensionality ReductionData dimensionality reduction is to reduce the dimension of data while retaining data information as much as possible, so as to simplify the model and avoid overfitting. Common methods of data dimensionality reduction include feature selection and feature extraction.
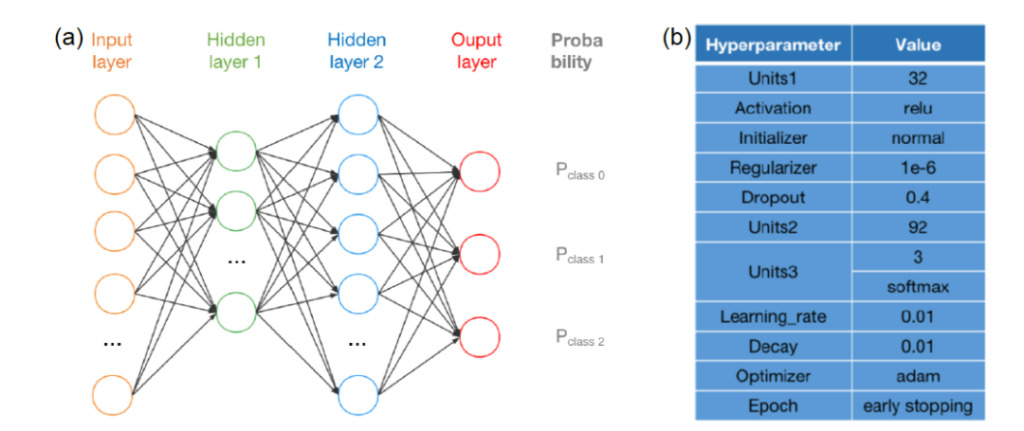
Model building Neural Network + Tree Model
The neural network used in this study consists of two hidden layersThe number of neurons in the first layer is between 8 and 96, and the number of neurons in the second layer is between 0 and 96. The hyperparameter combination of the model is automatically optimized through random search and Bayesian optimization.
In addition, the researchers also compared the performance of four tree model algorithms, including the parallel Bagging algorithm and Random Forest (RF) algorithm, the serial AdaBoost algorithm and the Gradient Boosting algorithm.
The evaluation criteria of the model include accuracy, precision, confusion matrix, F1 score, recall curve and AUC.
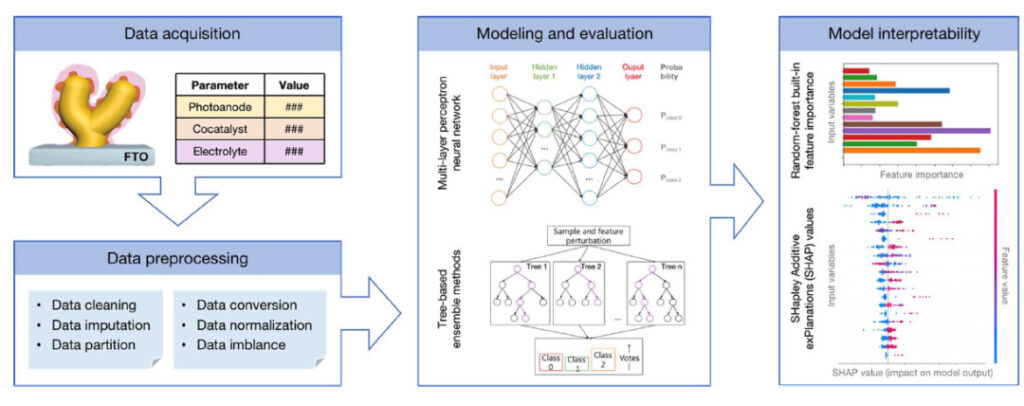
Explainability SHAP
Interpretable models help people understand the decision-making process of machine learning models. There are two main techniques to improve model interpretability:Intrinsic Interpretability and Post-hoc Interpretability.
The former can be achieved through self-explanatory models, such as linear regression, logistic regression, and decision trees. This method has strong interpretability but low accuracy. The latter uses surrogate models to explain existing models, such as ensemble methods, support vector machines, and neural networks.
also,The SHAP (Shapley Additive Explanation) method can use the Shapley value in game theory to calculate the feature importance in the model, providing inspiration for the design of co-catalysts.
Experimental Results
Performance comparison Random Forest Model is Best
After optimizing the model’s hyperparameters through cross-validation, the researchers compared the performance of the neural network and tree model algorithms.Among them, the random forest algorithm has the best generalization ability, with a test accuracy of 70.37% and an AUC of 0.784 .
It is noteworthy that the random forest model can accurately identify low- and medium-performance promoters and will not mistake them for high-performance.This shows that the random forest model can accurately capture the characteristics of high-performance co-catalysts.
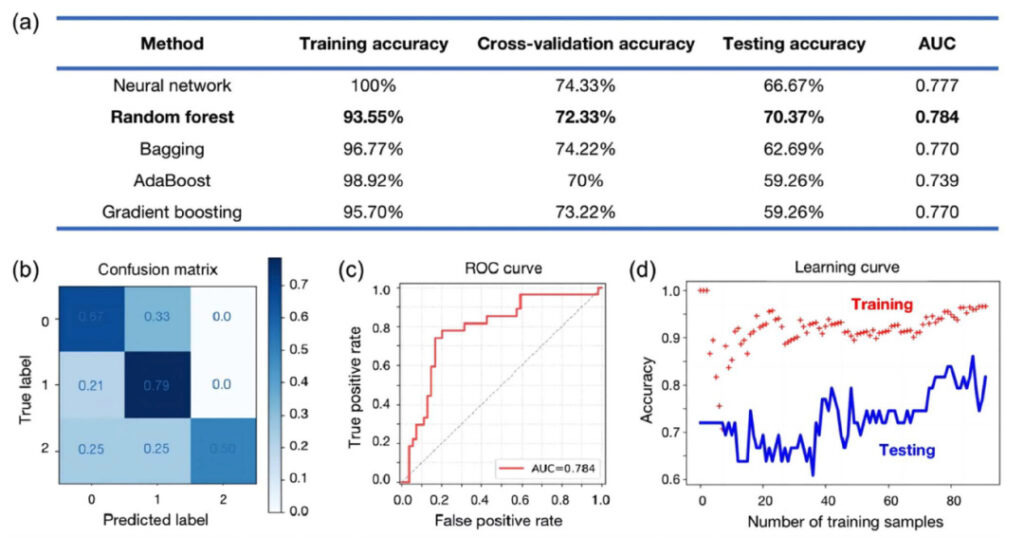
a: Accuracy, cross-validation accuracy, test accuracy and AUC of different models;
b: Confusion matrix of random forest model;
c: ROC curve of random forest model;
d: Learning curve of the random forest model.
The researchers then grouped low and medium performance into one category and high performance into another, converting the model into a binary output.The accuracy of random forest is 96.30% and AUC is 0.79 .
Feature Importance Type of co-catalyst
Performing feature importance analysis on the fitted random forest model can improve the interpretability of the model.The importance of the intrinsic characteristics of the PEC electrolyzer can be evaluated through the Gini importance or Mean Decrease Impurity.
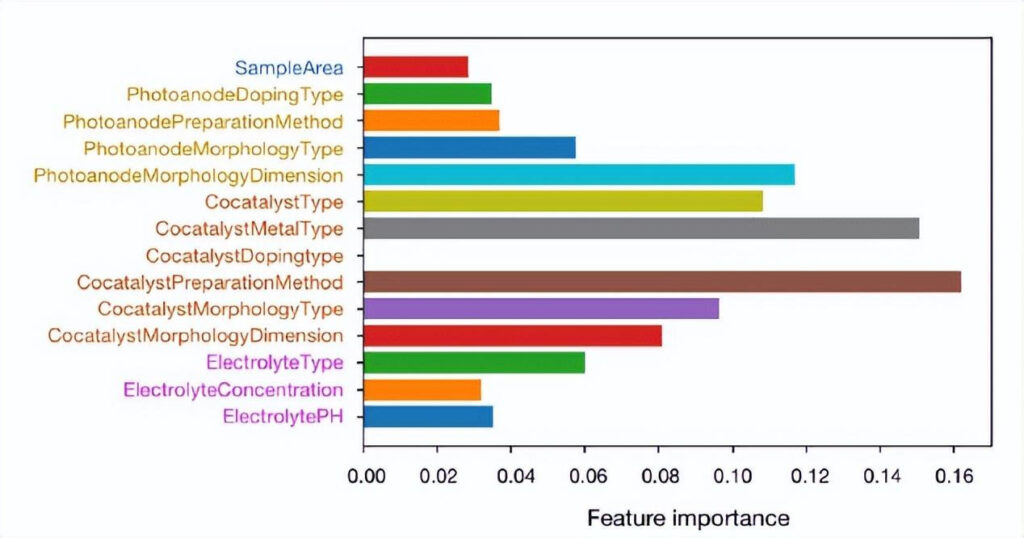
The parameters related to the co-catalyst have the greatest impact on the predictions of the random forest model.In particular, the type of promoter and the type of metal of the promoterThe second most important factor is the preparation method of the co-catalyst, which also affects the morphology and size of the co-catalyst. In addition, the size of the photoanode will also significantly affect the output of the random forest model. Therefore,When optimizing the PEC photoanode,The co-catalyst should be the main indicator, while the photoanode size should be optimized.
SHAP analysis Thickness of promoter
The researchers also used SHAP to calculate the feature importance of the binary output random forest model.

in,The thickness of the promoter is the most important input featureAs the thickness decreases, the SHAP value increases, and the impact on the model performance increases. When the thickness of the co-catalyst is between 5-10 nm, the SHAP value is positive, indicating that a decrease in thickness is likely to improve the model performance.
When the electrolyte concentration exceeds 0.5 M, SHAP is positive.This indicates that high-concentration electrolyte is beneficial to the improvement of PEC photoelectrode performance..
The results also showed that potassium borate buffer is the most ideal electrolyte, cobalt-containing catalysts are beneficial to the performance improvement, and metal hydroxides are beneficial to the performance improvement.

c: Effect of promoter thickness on SHAP value;
d: Effect of photoanode thickness on SHAP value;
e: Effect of electrolyte concentration on SHAP value.
In summary, BiVO4 Cobalt-based hydroxides with a thickness between 5 and 10 nm on single crystals may have good PEC water splitting performance in potassium borate electrolytes with concentrations higher than 0.5 M.
PEC water splitting: a more promising hydrogen production solution
As the global population grows, the world's demand for energy continues to increase.Seeking renewable energy has become an urgent issueSolar energy is a renewable, carbon-free energy source, accounting for more than 99% of global renewable energy. However, to completely replace fossil energy, large-scale energy storage equipment is needed to solve the intermittent problem of solar energy. Batteries may be able to meet short-term energy storage needs.But the only option for long-term and seasonal storage is fuel..
Inspired by the process by which plants use light energy to extract electrons from water and store them in high-energy chemical bonds, researchers are beginning to harness the sun's energy to split water and store the energy in the product, hydrogen.
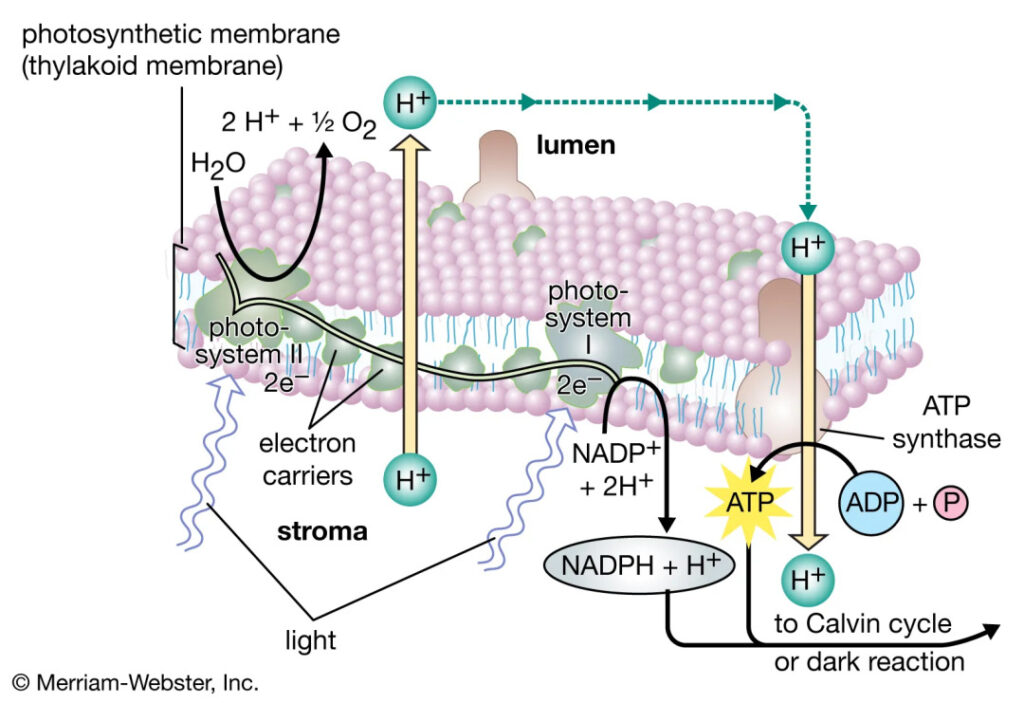
Hydrogen has a high energy density (MJ/kg) and no carbon emissions. It can be directly used in the hydrogen economy or synthesized into carbon fuels through the Fischer–Tropsch reaction, matching existing energy facilities.
Currently, the most effective solar energy conversion device is photovoltaic (PV), which converts solar energy into electricity and then produces hydrogen through water electrolysis.But this approach is too expensive to compete with fossil fuels..
PEC water splitting offers cheap hydrogen production optionHowever, due to the slow carrier transport speed, high recombination rate, easy corrosion of electrodes and high water quality requirements in this reaction, the water splitting efficiency of PEC is low and the maintenance cost is high.
With the help of AI, researchers can optimize the combination of PEC photoanode and co-catalyst, greatly improving the design efficiency of PEC electrodes. At the same time, explainable AI can identify the most important electrode features for the reaction, provide a reference for electrode optimization, and provide a new solution to resolve the global energy crisis.
Reference Links:
[1]https://onlinelibrary.wiley.com/doi/10.1002/aenm.201700555
[2]https://onlinelibrary.wiley.com/doi/10.1002/aenm.201802877
[3]https://www.britannica.com/science/photosynthesis








