Command Palette
Search for a command to run...
"Whale Face Recognition" Is Now online. The University of Hawaii Uses 50,000 Images to Train the Recognition Model With an Average Accuracy of 0.869

Contents at a glance:Facial recognition can lock human identity, and this technology is extended to whales, so there is "dorsal fin recognition". "Dorsal fin recognition" uses image recognition technology to identify whale species through dorsal fins. Traditional image recognition relies on convolutional neural network (CNN) models, which require a large number of training images and can only recognize certain single species. Recently, researchers at the University of Hawaii trained a multi-species image recognition model that performed well in whale applications.
Keywords:Image Recognition Cetaceans ArcFace
Author: daserney
Editor: Huanhuan, Sanyang
This article was first published on HyperAI WeChat public platform~
Cetaceans are flagship animals and indicator organisms of the marine ecosystem, and have extremely high research value for protecting the marine ecological environment.Traditional animal identification requires on-site photographing of animals and recording the time and location of individual appearances. It involves many steps and the process is complicated.Among them, image matching - identifying the same individual in different images - is particularly time-consuming.
A 2014 study by Tyne et al. estimated that during a one-year catch-and-release survey of spotted dolphins (Stenella longirostris),Image matching took more than 1,100 hours of manual labor and accounted for nearly a third of the total project cost..
Recently, researchers including Philip T. Patton from the University of Hawai'i used more than 50,000 photos (including 24 species of cetaceans and 39 catalogs) to train a multi-species image recognition model based on face recognition ArcFace Classification Head.The model achieved an average precision (MAP) of 0.869 on the test set, with MAP scores exceeding 0.95 for 10 categories.
The research has been published in the journal Methods in Ecology and Evolution, titled “A deep learning approach to photo-identification demonstrates high performance on two dozen cetacean species.”

The research results have been published in Methods in Ecology and Evolution.
Paper address:
https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.14167
Dataset: 25 species, 39 catalogs
Data Introduction
Happywhale and Kaggle collaborated with researchers around the world to assemble a large-scale, multi-species cetacean dataset. The dataset was collected for a Kaggle competition that required teams to identify individual cetaceans from dorsal fin/side profile images.The dataset contains 41 catalogues of 25 species, each catalogue contains one species, and some species in the catalogues appear repeatedly.
The study removed two competition catalogs because one of them had only 26 low-quality images for training and testing, and the other catalog lacked a test set.The final dataset contains 50,796 training images and 27,944 test images, of which the 50,796 training images contain 15,546 identities.Among these identities, 9,240 (59%) have only one training image, and 14,210 (91%) have less than 5 training images.
Dataset and code address:
https://github.com/knshnb/kaggle-happywhale-1st-place
Training Data
To address the problem of complex image backgrounds, some contestants trained image cropping models that can automatically detect cetaceans in images and draw bounding boxes around them.This pipeline includes 4 whale detectors using different algorithms including YOLOv5 and Detic.The diversity of detectors increases the robustness of the model and enables data augmentation on experimental data.

Figure 1: Images from 9 categories in the competition set and bounding boxes generated by 4 whale detectors
The probabilities of the crops generated by each bounding box are: 0.60 for red, 0.15 for olive green, 0.15 for orange, and 0.05 for blue. After cropping, the researchers resized each image to 1024 x 1024 pixels to be compatible with the EfficientNet-B7 backbone.
After resizing, apply data augmentation techniques such as affine transformation, resizing and cropping, grayscale, Gaussian blur, etc.Avoid ModelsSerious overfitting.
Data augmentation refers to the transformation or expansion of original data during the training process to increase the diversity and quantity of training samples, thereby improving the generalization ability and robustness of the model.
Model training: species and individual identification
The following figure shows the training process of the model, as shown in the orange part.The researchers divided the image recognition model into three parts: backbone, neck and head.
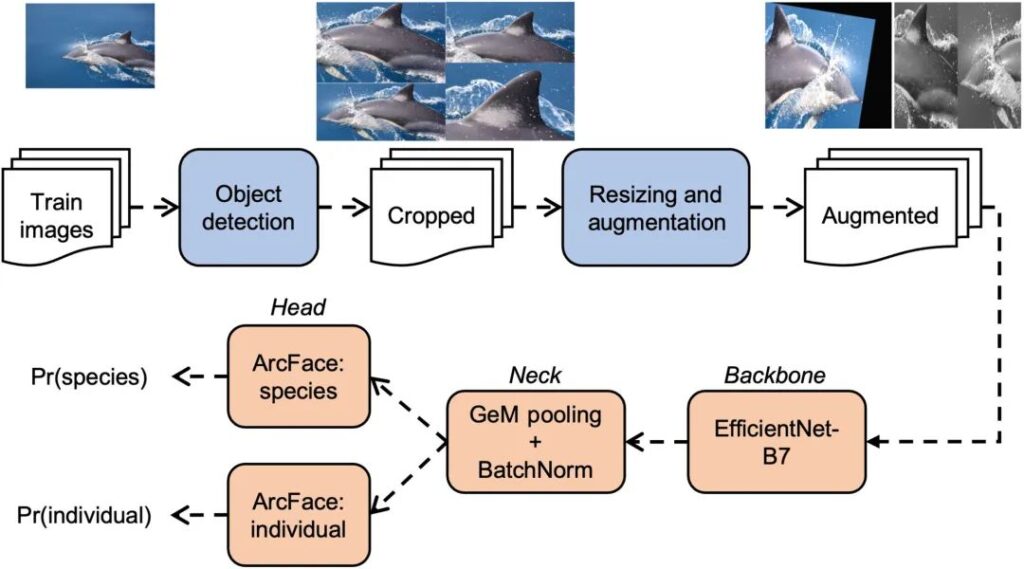
Figure 2: Multi-species image recognition model training pipeline
The first row in the figure shows the preprocessing steps (taking the image of the common dolphin Delphinus delphis as an example).Crops are generated by 4 object detection models, and the data augmentation step generates two example images.
The bottom row shows the training steps for the image classification network.From backbone to neck to head.
The image first goes through the network into the backbone.A series of studies over the past decade have produced dozens of popular backbones, including ResNet, DenseNet, Xception, and MobileNet.EfficientNet-B7 performs best in the cetacean application.
Backbone takes an image and processes it through a series of convolutional and pooling layers to produce a simplified 3D representation of the image. Neck reduces this output to a one-dimensional vector, also known as a eigenvector.
Both head models convert feature vectors into class probabilities, namely Pr(species) or Pr(individual).Used for species identification and individual identification respectively.These classification heads are called sub-centered ArcFace with dynamic margins and are generally applicable to multi-species image recognition scenarios.
Experimental results: Average accuracy 0.869
We obtained an average precision (MAP) of 0.869 for predictions on 21,192 images in the test set (39 catalogs of 24 species).As shown in the figure below, the average precision varies across species and is independent of the number of training or test images.
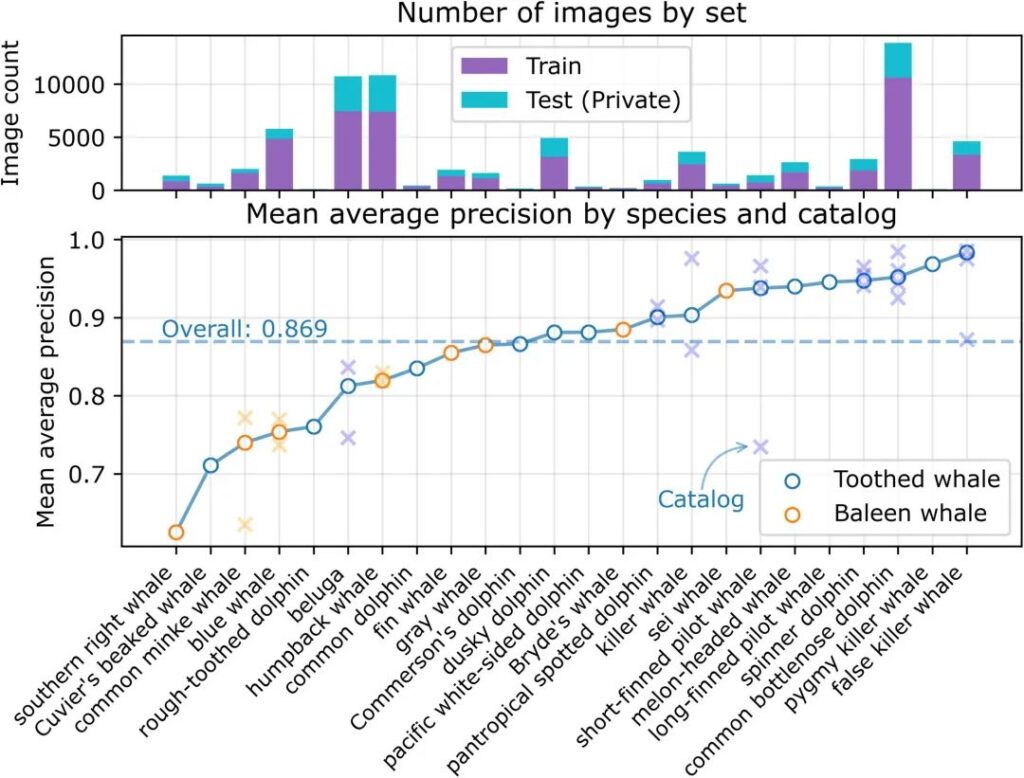
Figure 3: Average precision on the test set
The top panel shows the number of images of each species by purpose (i.e., training or testing). Species with multiple catalogs are indicated with an x.
The figure shows that the model performs better in identifying toothed whales, but performs worse in identifying baleen whales.Only two baleen whale species scored above average.
There are also differences in model performance for multi-catalog species.For example, the MAP scores of common minke whales (Balaenoptera acutorostrata) were 0.79 and 0.60 between catalogs. Other species such as beluga whales (Delphinapterus leucas) and killer whales also showed large differences in performance between catalogs.
Although the researchers did not find a reason to explain this directory-level performance difference,But they found that some qualitative indicators such as blurriness, uniqueness, label confusion, distance, contrast, and splash may affect the accuracy score of an image.
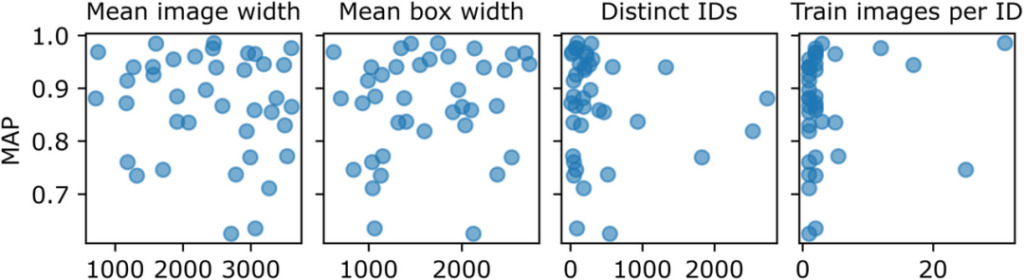
Figure 4: Variables that may affect directory-level performance differences
Each point in the figure represents a directory in the competition dataset, and pixels represent the image and bounding box width. Distinct IDs represents the number of different individuals in the training set. However,There is no clear correlation between the catalog-level MAP and the average image width, average bounding box width, number of training images, number of different individuals, and number of training images per individual.
In summary, the researchers proposed that when using this model for prediction, the average accuracy of 10 catalogs representing 7 species was higher than 0.95, and the performance was better than the traditional prediction model, which further shows that the use of this model can correctly identify individuals.In addition, the researchers also summarized 7 points about whale research during the experiment:
- Dorsal fin identification performed best.
- Directories with fewer distinct individual features performed poorly.
- Image quality is important.
- Identifying animals by color can be difficult.
- Species whose features are far from the training set will score poorly.
- Preprocessing remains a hurdle.
- Variations in animal marking may affect model performance.
Happywhale: a citizen science platform for cetacean research
Happywhale, mentioned in the dataset introduction of this article, is a public science platform for sharing whale images.Its goal is to unlock large datasets and facilitate fast photo ID matching.and creating scientific research engagement for the public.
Happywhale official website address:
Happywhale was founded in August 2015. Its co-founder Ted Cheeseman is a naturalist who grew up in Monterey Bay, California. He has loved whale watching since he was a child and has traveled to Antarctica and South Georgia Island many times.He has more than 20 years of experience in Antarctic exploration and polar tourism management.

Ted Cheeseman, co-founder of Happywhale
In 2015, Ted left Cheesemans' Ecology Safaris (an eco-tourism company founded in 1980 by Ted's parents, who are also naturalists) after 21 years of work, and joined the Happywhale project. Collect scientific data to further our understanding and conservation of whales.
In just a few years,Happywhale.com has become one of the largest contributors to the field of cetacean research.In addition to the huge number of whale identification images, they also provide many insights into understanding whale migration patterns.
Reference Links:
[1] https://baijiahao.baidu.com/s?id=1703893583395168492
[2]https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0086132
[3]https://phys.org/news/2023-07-individual-whale-dolphin-id-facial.html#google_vignette
[4]https://happywhale.com/about
This article was first published on HyperAI WeChat public platform~








