Command Palette
Search for a command to run...
Sim Computing: DSA AI Compiler Build Based on TVM

Hello everyone, I am Dan Xiaoqiang from Shim Computing. Today, I and three colleagues will share with you how to support NPU on TVM.
The essential problem that the DSA compiler solves is that different models need to be deployed on hardware, and optimization methods at various abstract levels are used to make the models fill the chip as much as possible, that is, to compress the bubbles. As for how to schedule, the scheduling triangle described by Halide is the essence of this problem.
What are the main problems that the DSA compiler needs to solve? First, we abstract a DSA architecture. As shown in the figure, Habana, Ascend and IPU are all instantiations of this abstract architecture. In general, each core in the computing core has vector, scalar and tensor computing units. From the perspective of instruction operations and data granularity, many DSAs may tend to use relatively coarse-grained instructions, such as two-dimensional and three-dimensional vector and tensor instructions, and many hardware use fine-grained instructions, such as one-dimensional SIMD and VLIW. Some of the dependencies between instructions are exposed through explicit interfaces for software control, and some are controlled by the hardware itself. The memory is multi-level memory, mostly scratchpad memory. There are parallelisms of various granularities and dimensions, such as stream parallelism, cluster parallelism, multi-core parallelism, and pipeline parallelism between different computing components.
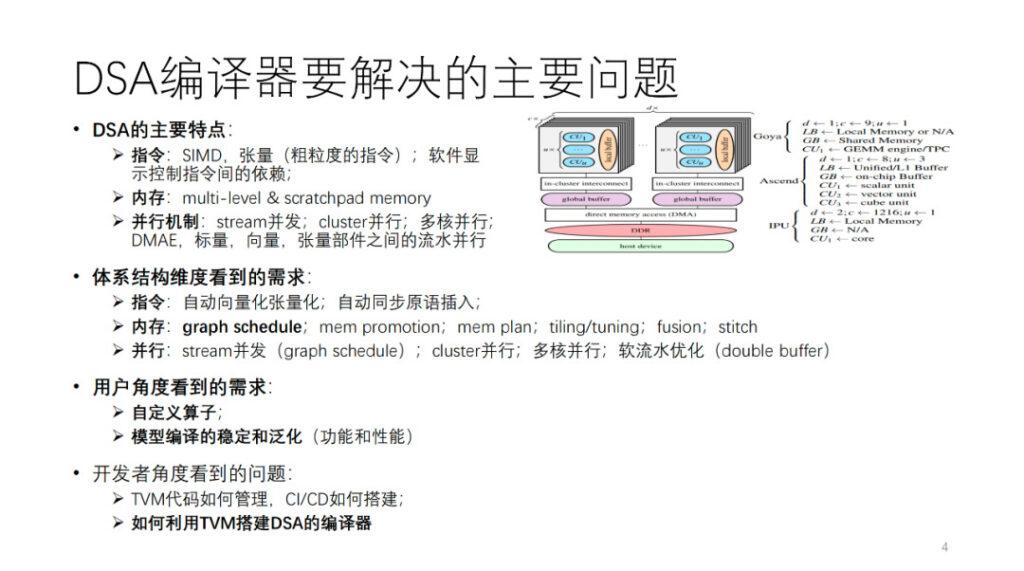
To support this type of architecture, from the perspective of compiler developers, different requirements are put forward for the AI compiler from several aspects of the above-mentioned architecture. We will expand on this part later.
From the user's perspective, first of all, we need a stable and generalized compiler that can compile successfully as many models or operators as possible. In addition, users hope that the compiler can provide a programmable interface to customize algorithms and operators to ensure that some key algorithm innovations can be carried out independently. Finally, teams like ours or friendly companies will also pay attention to: how to use TVM to build an AI compiler, such as how to manage self-developed and open source TVM code, how to build an efficient CI, etc. This is what we are going to share today, and my colleague will talk about the compilation optimization part below.
Wang Chengke from Shim Computing: DSA Compilation Optimization Process
This part is shared on site by Wang Chengke, a computing engineer at Shim.
First, let me introduce the overall process of Shim's compilation practice.
In response to the architectural features mentioned above, we built a self-developed optimization pass based on the TVM data structure and reused TVM to form a new model implementation: tensorturbo.
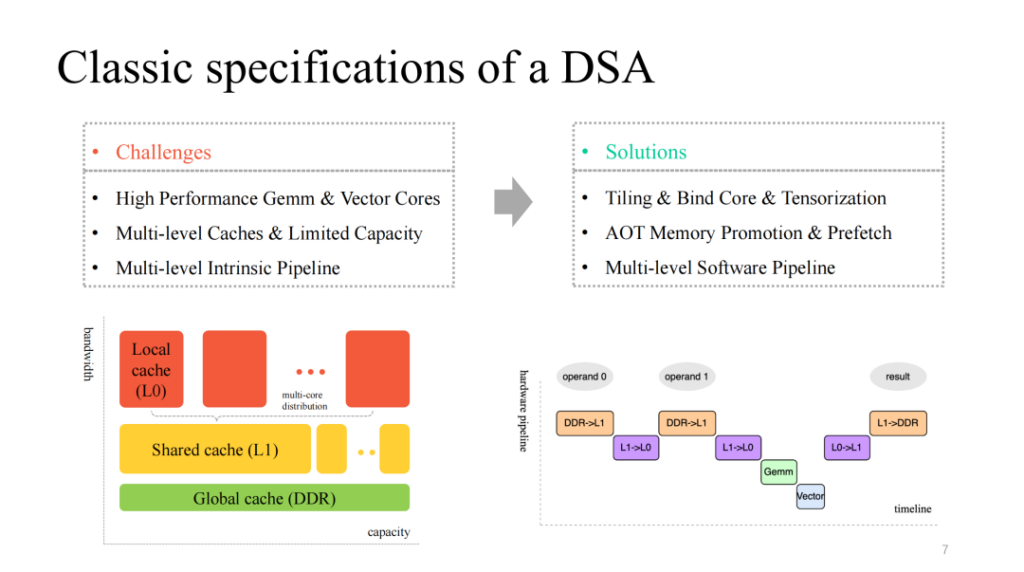
We see a relatively classic DSA architecture, which generally provides some efficient, customized matrix and vector layer multi-core computing cores, has a multi-layer cache mechanism to match it, and also provides multi-module execution units that can run in parallel. Correspondingly, we need to deal with the following issues:
- Split data calculations, efficiently bind cores, and efficiently vectorize customized instructions;
- Finely manage the limited on-chip cache and pre-fetch data accordingly at different cache levels;
- Optimize the multi-stage pipeline executed by multiple modules, and strive to obtain a better acceleration ratio.
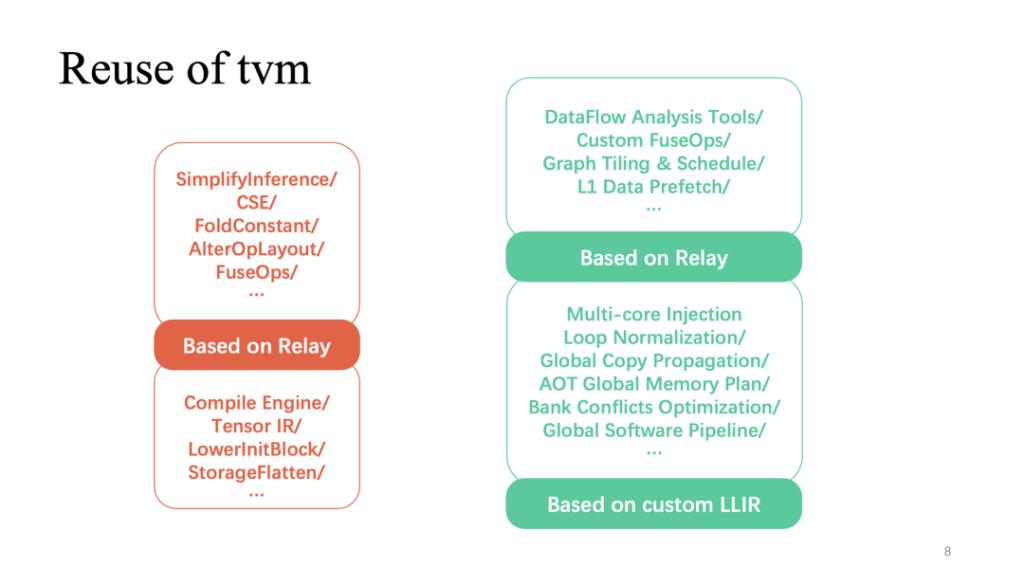
The red part (above) shows the part of the whole process that reuses TVM more frequently. The common layer-related optimizations implemented on the relay can be directly reused. In addition, the operator implementation based on TensorIR and custom LLIR is also highly reused. Customized optimizations related to hardware features, as we just mentioned, require more self-developed work.
First, let’s look at a self-developed work on layers.
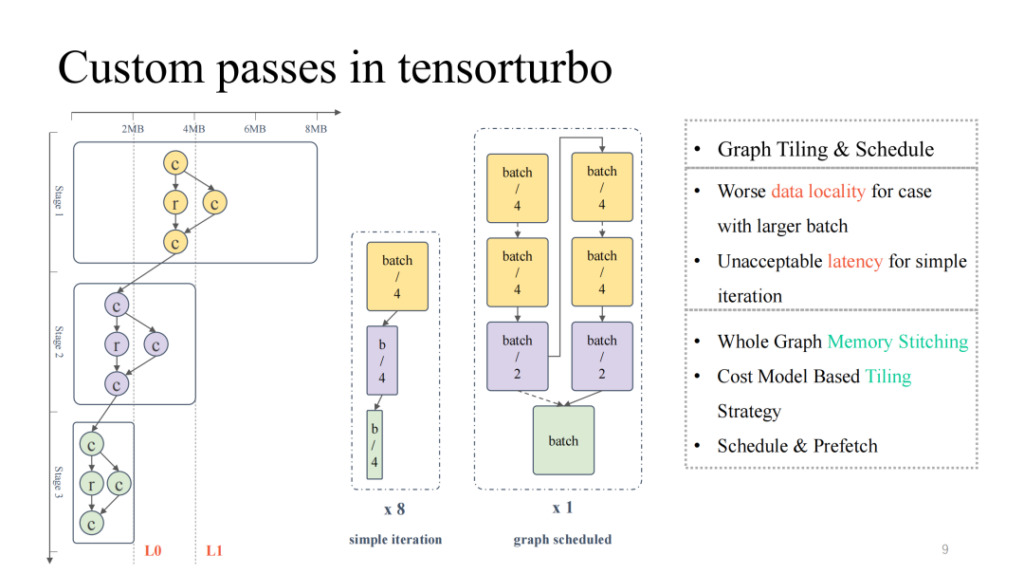
Focusing on the typical computational flow chart on the far left, we can see that from top to bottom, the overall cache occupancy and computation occupancy are decreasing, presenting an inverted pyramid state. For the first half, when the model scale is large, we need to focus on solving the problem of on-chip cache residency; and for the second half, when the model scale is small, we need to deal with the problem of low computational unit utilization. If we simply adjust the model scale, such as adjusting the batch size, a smaller batch size can result in lower latency, and the corresponding throughput will be reduced; similarly, a larger batch size will result in higher latency, but it may increase overall throughput.
Then we can use graph scheduling to solve this problem. First, allow a relatively large batch size input to ensure that the utilization of the whole process is relatively high. Then do a storage analysis of the entire graph, add segmentation and scheduling strategies, so that the results of the first half of the model can be better cached on the chip, while achieving a higher utilization of the computing core. In practice, it can achieve good results in both latency and throughput (for details, please pay attention to OSDI 23 Shim's article: Effectively Scheduling Computational Graphs of Deep Neural Networks toward Their Domain-Specific Accelerators, which will be available in June).
The following is another acceleration work of soft water flow.
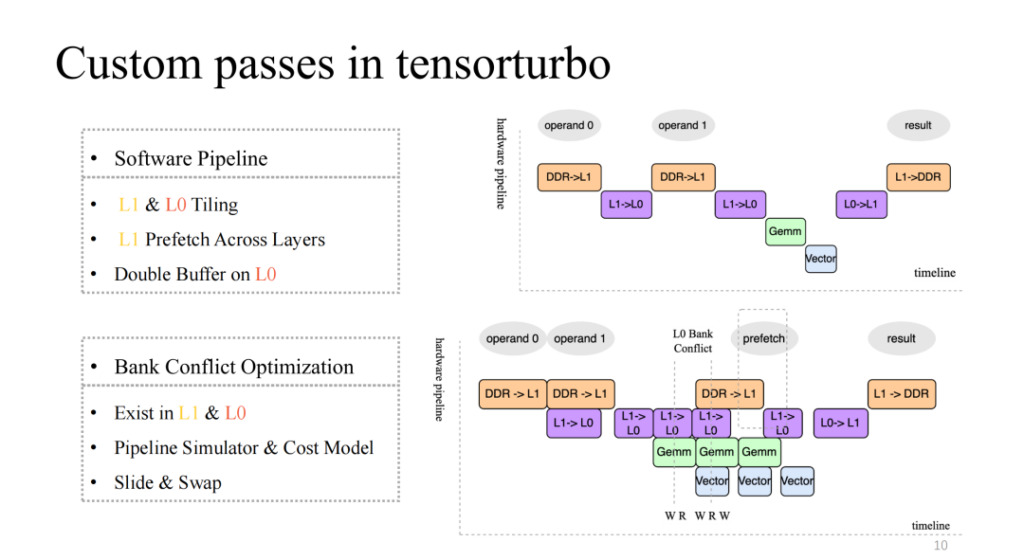
Pay attention to the upper right picture, which implements a relatively native four-stage pipeline, but it is obviously not an efficient pipeline. Generally, an efficient pipeline should be one in which the four execution units can be synchronized and parallelized after several iterations. This requires some work, including segmentation on L1 and L0, cross-layer data prefetching on L1, and double buffer operation on the L0 level. Through these works, we can achieve a pipeline with relatively high acceleration as shown in the lower right picture.
This will also introduce a new problem. For example, when the number of concurrent reads and writes to the cache by multiple execution units is higher than the number of concurrent reads and writes supported by the current cache, competition will occur. This problem will cause the memory access efficiency to drop exponentially, which is the Bank Conflict problem. In response to this, we will statically simulate the pipeline during compilation, extract conflicting objects, and combine the cost model to exchange and translate the allocated addresses, which can greatly reduce the impact of this problem.
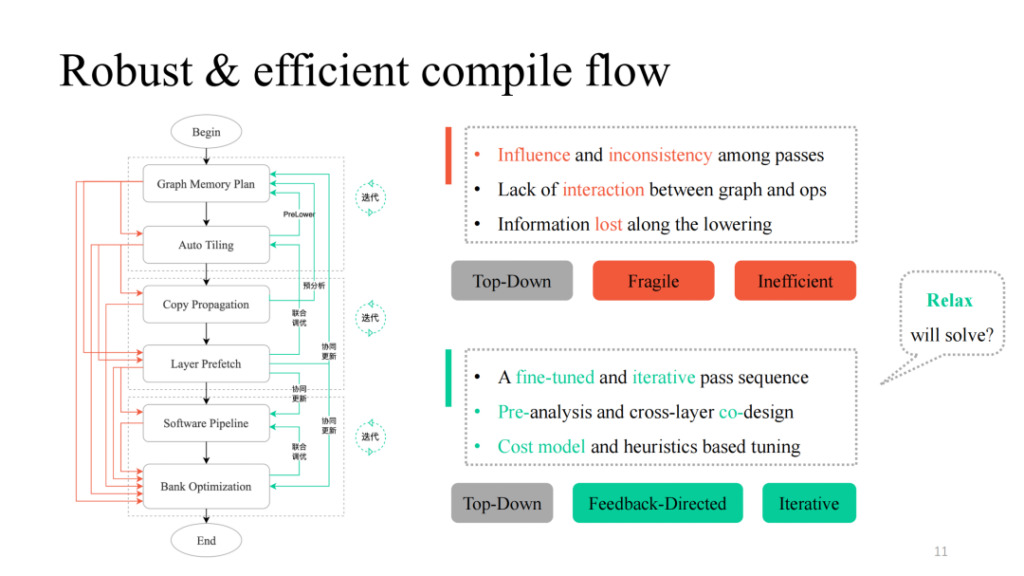
With various passes, we can combine them in a simple top-down way. Following the black process in the left figure, we get a functionally feasible compilation pipeline. However, many problems were found in practice, including the mutual influence between passes mentioned by Siyuan, the lack of interaction logic, and the lack of communication logic between layers and operators. You can see the process indicated by the red part in the left figure. In practice, it is found that each path or their combination will cause compilation failure. How to make it more robust? Shim provides a feedback path in each pass that may fail, introduces interaction logic between layers and operators, performs pre-analysis and prelower operations, and introduces some iterative tuning mechanisms in key parts, and finally obtains an overall pipeline implementation with high generalization and strong tuning capabilities.
We also noticed that the transformation of data structure and related design ideas in the above work have many similarities with the current TVM Unity design. We also expect Relax to bring more possibilities.
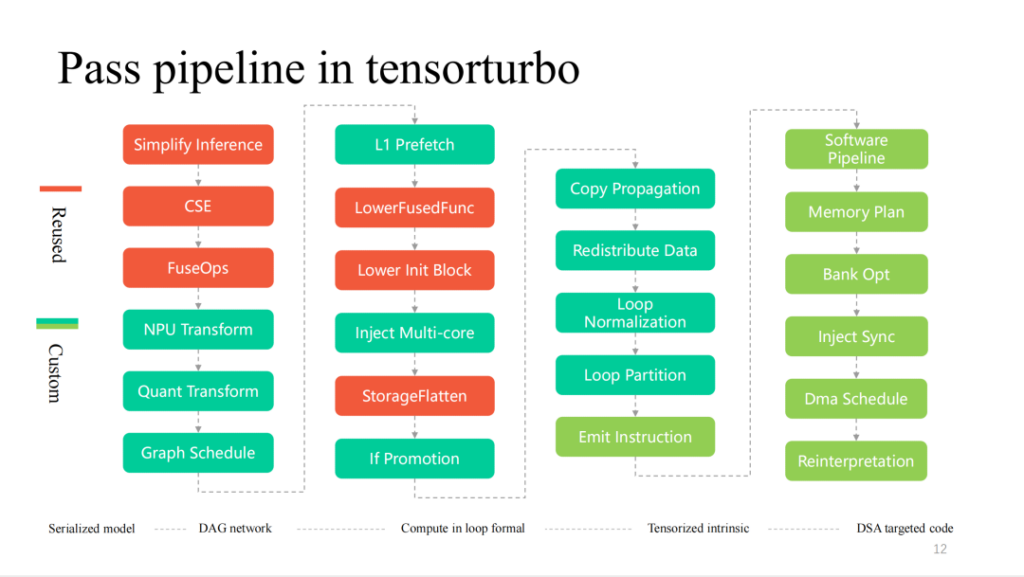
Here are more detailed passes in the compilation process of Xim. From left to right, it is a layer-by-layer process. The red part is highly reused by TVM. The closer to the hardware features, the more customized passes there will be.
The following is a detailed introduction to some of the modules.
Sim Computing Liu Fei: Vectorization and Tensorization of DSA
This part is shared on site by Liu Fei, a computing engineer at Shim.
This chapter will introduce the vectorization and tensorization work of Shim. From the perspective of instruction granularity, the coarser the instruction granularity, the closer it is to the multi-layer loop expression of Tensor IR, so the vectorization and tensorization are easier. On the contrary, the finer the instruction granularity, the greater the difficulty. Our NPU instructions support one-dimensional/two-dimensional/three-dimensional tensor data calculations. Shim also considered the native TVM tensorize process, but considering that Compute Tensorize has limited complex expression capabilities, it is more difficult to tensorize complex expressions such as if condition, and after tensorization vectorization, it cannot be scheduled.
In addition, TensorIR Tensorize was under development at the time and could not meet development needs, so Shim provided its own set of instruction vectorization processes, which we call instruction emission. Under this process, we support about 120 Tensor instructions, including instructions of various dimensions.

Our instruction flow is roughly divided into three modules:
- Optimization before launch. The transformation of the cycle axis provides more launch conditions and possibilities for command launch;
- Instruction emission module. Analyze the results and information of the loop and select an optimal instruction generation method;
- The module after the instruction is issued. It processes the specified issue after the processing fails to ensure correct execution on the CPU.
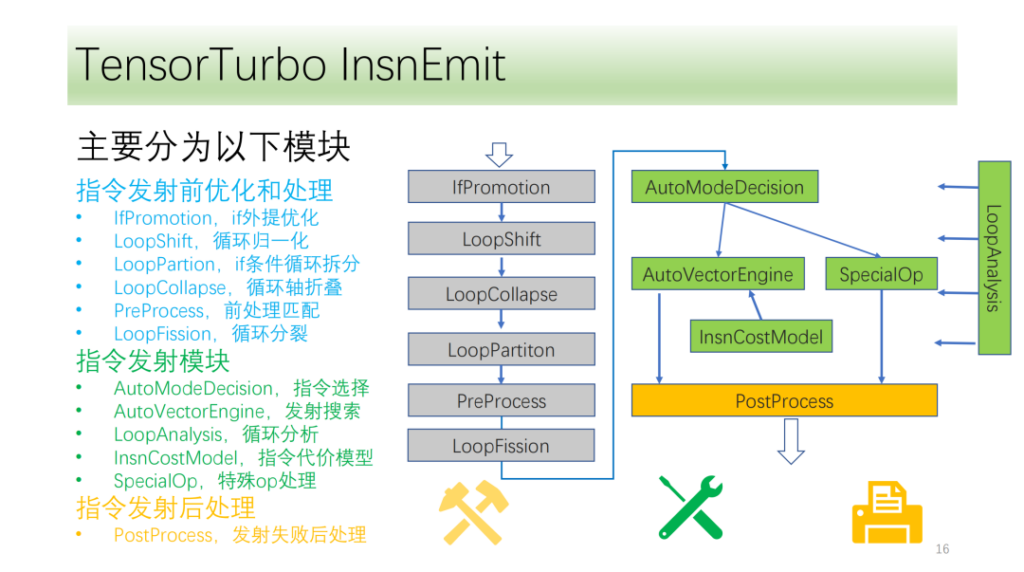
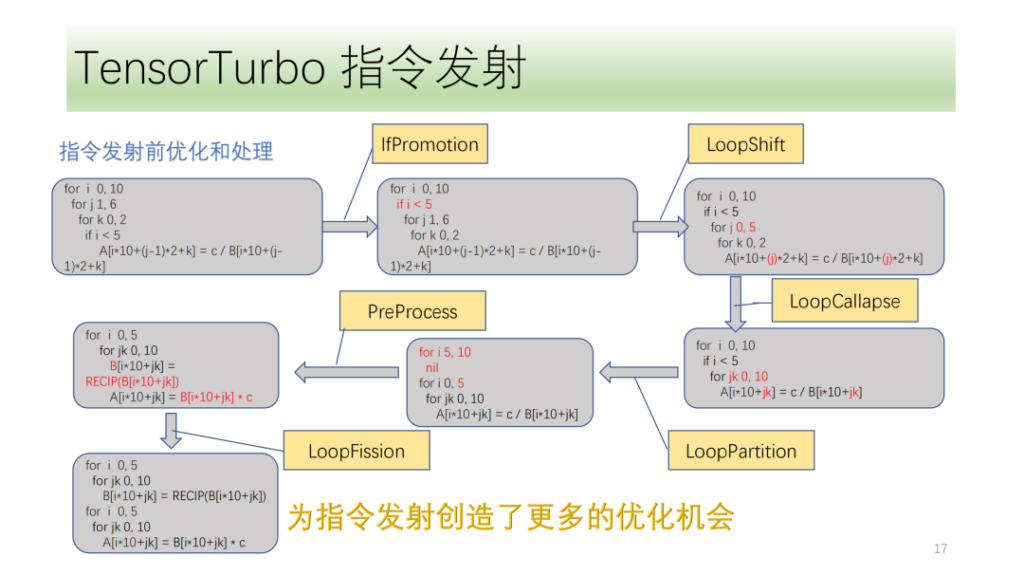
Below isOptimization and processing module before command issuance,They are all composed of a set of optimization passes, among which IfPromotion is to remove if statements that hinder the emission of loop axes as much as possible, PreProcess is to split operators that have no corresponding instructions, LoopShift is to normalize the loop axis boundaries, LoopCallapse is to merge consecutive loop axes as much as possible, LoopPartition is to split the loop axes related to if, and LoopFission is to split multiple store statements in the loop.
From this example, we can see that initially the IR cannot emit any instructions. After optimization, it can finally emit two Tensor instructions and all loop axes can emit instructions.
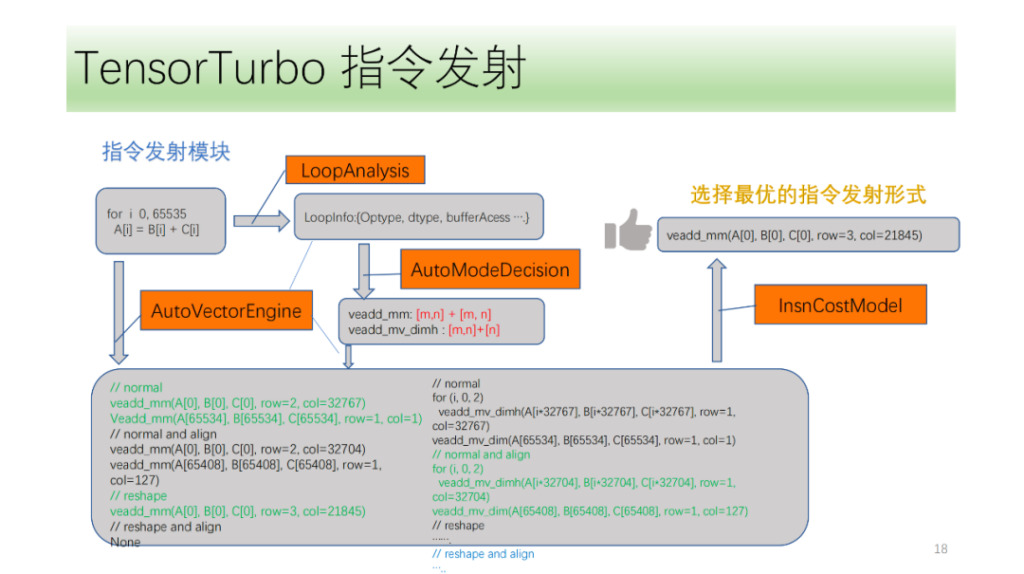
Then there is the instruction emission module. First, the instruction emission module will cyclically analyze the structure in the loop and obtain information such as Optype, dtype, bufferAcess, etc. After having this information, the instruction recognition will identify which instructions the loop axis may emit. Because one IR structure may correspond to multiple NPU instructions, we will identify all possible instructions to be emitted, and the VectorEngine search engine will search for the possibility of each instruction emission based on a series of information such as alignment and reshape of the instruction. Finally, CostModel will calculate and find the optimal emission form for emission.
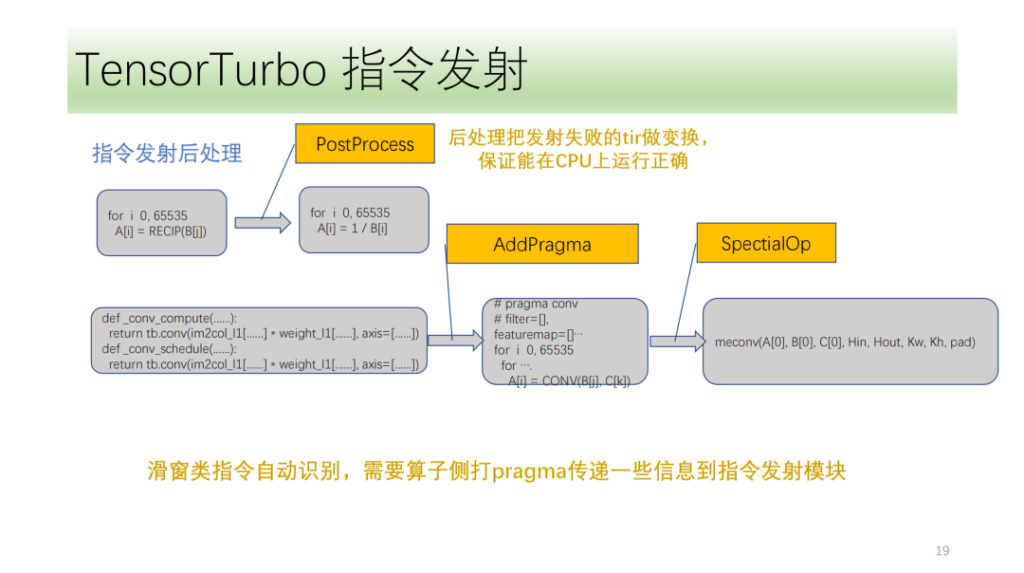
The last one is the instruction post-transmission processing module. It mainly processes the TIR of instruction transmission failure to ensure that it can run correctly on the CPU. There are also some special instructions that Shim needs to mark at the front end of the algorithm. The instruction transmission module uses these marks and its own IR analysis to correctly transmit the corresponding instructions.
The above is the entire DSA tensorization and vectorization process of Shim. We have also explored some directions, such as the microkernel solution, which is also a hotly discussed direction recently. Its basic idea is to divide a calculation process into two layers, one layer is spliced in the form of a combined microkernel, and the other is searched. Finally, the results of the two layers are spliced together to select the best result. The advantage of this is that it fully utilizes hardware resources while reducing the complexity of the search and improving the search efficiency.
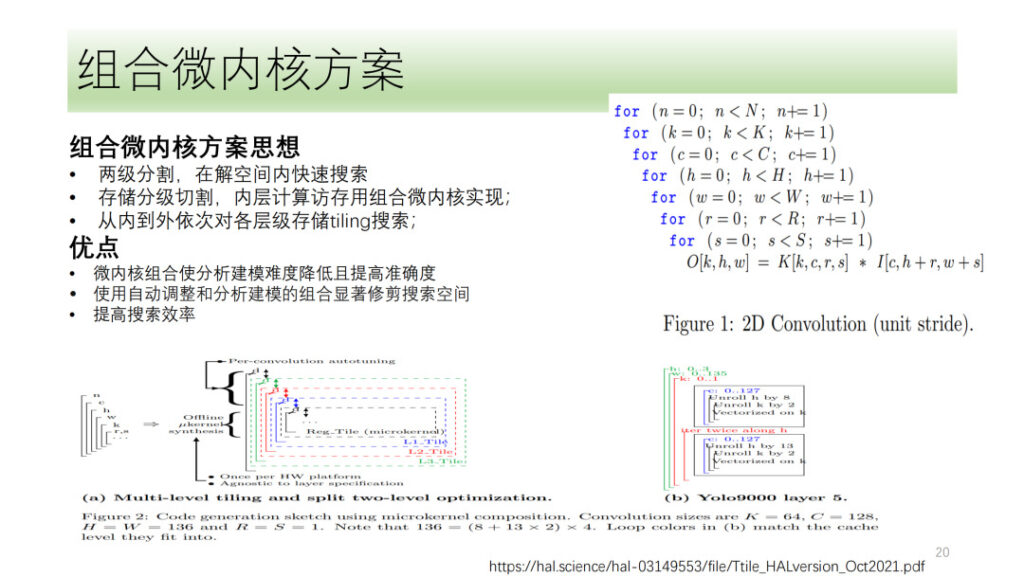

Shim has also explored the microkernel, but considering that the microkernel solution has not significantly improved performance compared to current solutions, Shim is still in the exploratory stage in the direction of microkernel.
Yuan Sheng, Shim Computing: Custom Operators for DSA
This part is shared on site by Shim computing engineer Yuan Sheng.
First of all, we know that operator development currently encounters four major problems:
- There are many neural network operators that need to be supported. After classification, there are more than 100 basic operators.
- As the hardware architecture is constantly iterating, the corresponding instructions and logic involved in the operators need to be changed;
- Performance considerations: Operator fusion (local memory, shared memory) and the graph computing information transmission (segmentation, etc.) I mentioned earlier;
- Operators need to be open to users, and users can only enter the software to customize operators.
I mainly divide it into the following three aspects. The first is the graph operator, which is based on the relay api and cuts it into basic language operators.
Take the following figure as an example:
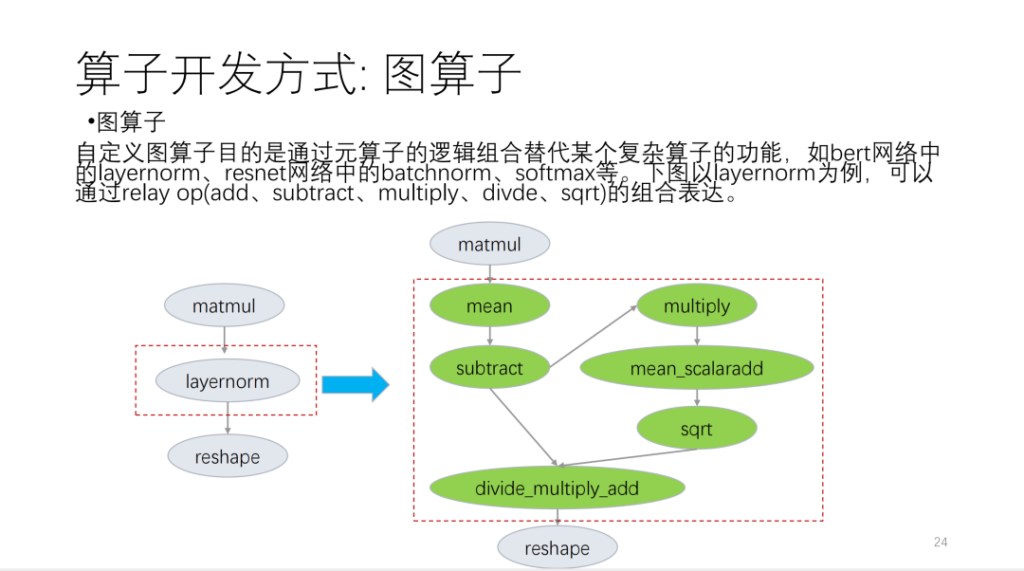
The second is the meta-operator. The so-called meta-operator is based on TVM Topi and uses compute/schedule to describe the operator algorithm logic and loop transformation related logic. When we develop operators, we will find that many operator schedules can be reused. Based on this situation, Xim provides a set of templates similar to schedules. Now, we divide operators into many categories. Based on these categories, new operators will reuse a large number of schedule templates.
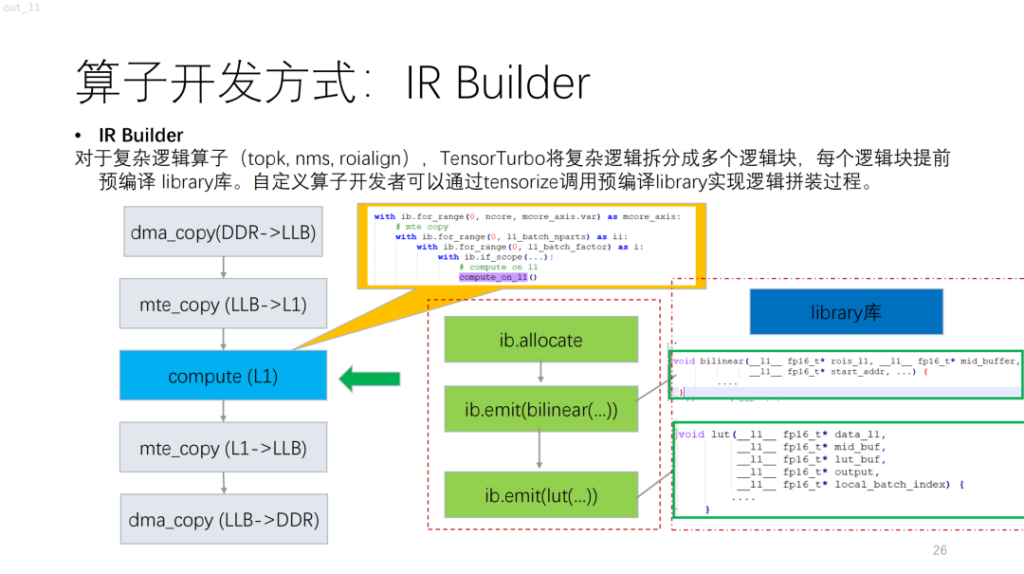
Next is a more complex operator. Based on NPU, you will find that algorithms with control flow such as topk and nms have a lot of scalar calculations, which are currently difficult to describe using compute/schedule. To solve this problem, Xim provides a library-like library. It is equivalent to compiling complex logic in the library first, and then outputting the logic of the entire operator by combining it with the IR Builder.
The next step is the operator segmentation. For NPU, compared to GPU and CPU, each TVM instruction will operate on a continuous memory block and will have a memory size limit. At the same time, in this case, the search space is not large. Based on these problems, Shim provided a solution. First, there will be a candidate set, and the feasible solutions are placed in the candidate set. Secondly, the feasibility is explained, mainly considering the performance requirements and NPU instruction limitations. Finally, the cost function will be introduced, which will take into account the characteristics of the operator and the characteristics of the computing units that may be used.
The next challenge for operator development is the fusion of operators. Currently, we are facing two explosive problems. The first is that we don’t know how to combine our own operators with other operators. The second is that we can see that there are many memory levels in the NPU, and there is an explosive fusion of memory levels. The HIMU LLB will have a fusion combination of shared memory and local memory. Based on this situation, we also provide an automatic generation framework. First, according to the scheduling information given by the layer, the data movement operation is inserted, and then the schedule information is refined according to the master op and salve op in the schedule. Finally, a post-processing is performed based on the limitations of the current instructions.

Finally, we mainly show the operators supported by SYM. There are about 124 ONNX operators, and currently about 112 are supported, accounting for 90.3%. At the same time, SYM has a set of random tests that can test large prime numbers, fusion combinations, and some pattern fusion combinations.
Summarize
This part is shared on site by Shim computing engineer Dan Xiaoqiang.
This is the CI built by Xim based on TVM. More than 200 models and a lot of unit tests are run on it. If MR does not grab CI resources, it takes more than 40 minutes to submit a code. The amount of calculation is very large, and more than 20 self-developed computing cards and some CPU machines are hung up.
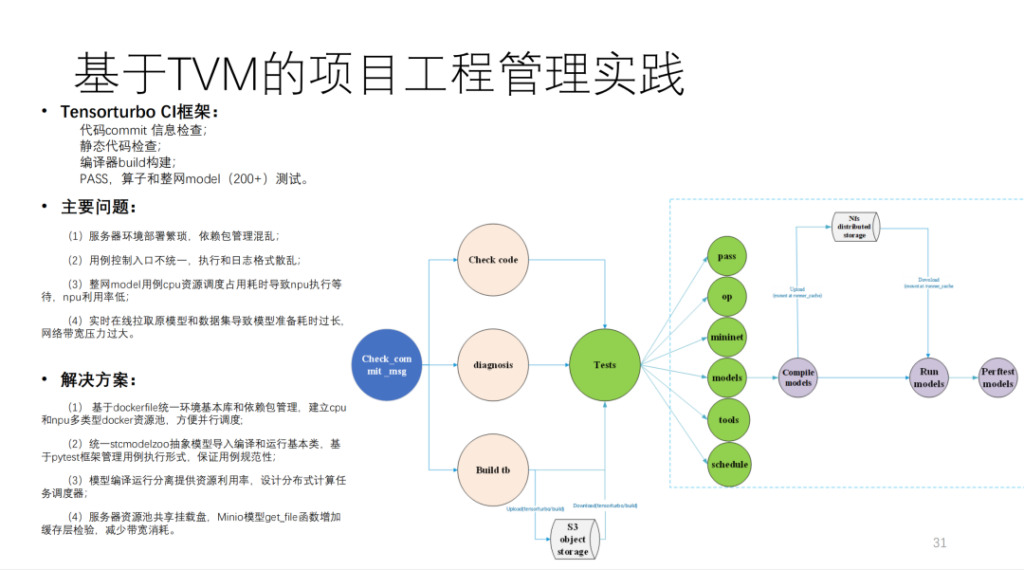
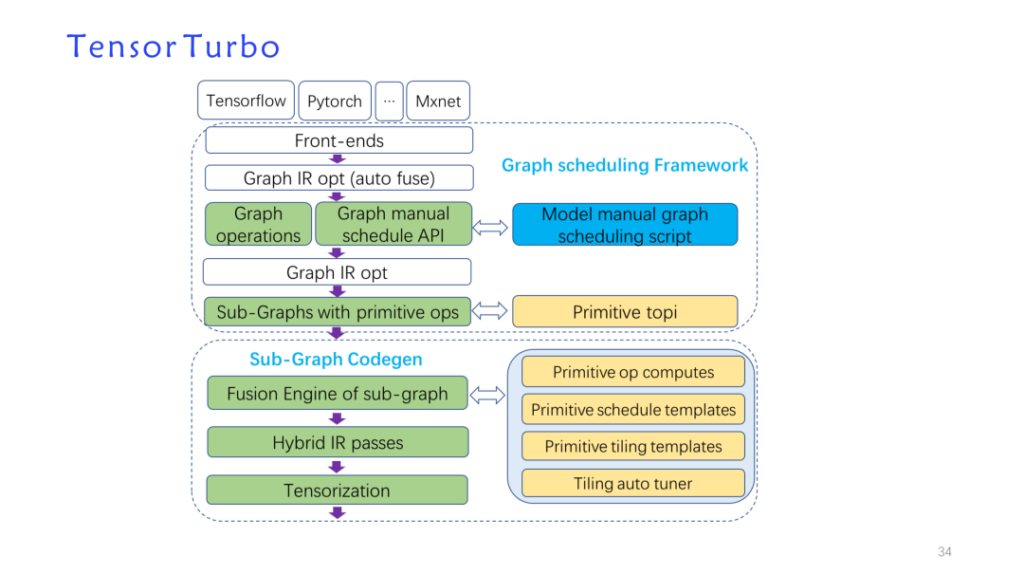
To summarize, this is the architecture diagram of Shim, as shown below:
From the results, the performance has been greatly improved. In addition, if the automatic generation is compared with another handwriting model team, it can basically reach their 90% or above.

This is the situation of the Xim code. The left side shows how to manage TVM and self-developed code. TVM is used as a data structure in third_party. Xim has its own source and python things. If we need to make changes to TVM, we can modify TVM in the patch folder. There are three principles here:
- Most of them use self-developed passes and also develop custom modules;
- Patch will limit the modification of TVM source code and upstream it in time if possible;
- Regularly synchronize with the TVM community and update the latest code to the repository.
The entire amount of code is also shown in the figure above.
Summarize:
- We support the first and second generation chips of HIMU end-to-end based on TVM;
- Implement all compilation optimization requirements based on relay and tir;
- Completed automatic generation of 100+ vector tensor instructions based on tir;
- Implemented a custom operator solution based on TVM;
- The first generation of the model supports 160+, and the second generation has enabled 20+;
- The model performance is close to handwriting.
Q&A
Q1: I am interested in the fusion operator. How does it combine with TVM's TIR?
A1: For the right figure, for the same operator level, first, if the operator has two inputs and one output, then there are 27 operator forms. Second, when various operators are connected, the scope may be one of the three, so we do not assume a fixed pattern. So how to implement it on TVM? First, according to the layer scheduling, determine where the front and back add and the intermediate scope are. The layer is a very complex process. The output result is to determine which cache the operator exists in and how much available cache there is. With this scheduling result, we automatically fuse operator generation at the operator layer. For example, we automatically insert data migration operations based on scope information to complete the construction of the data flow.
The mechanism in schedule info is very similar to that of TVM native. The size used by each member scope needs to be considered during the fusion process. So this is TVM native stuff. We just use a special framework to integrate it here and make it automatic.
do schedule On this basis, the schedule required by the developer is made, and there may also be some post-processing.

Q2: Can you share more details about CostModel? Is the cost function designed based on operator-level features or hardware-level features?
A1: The general idea is here. First, a candidate set is generated. The generation process is related to the NPL structure. Then there is a pruning process, taking into account instruction restrictions and subsequent optimizations, multi-core, double buffer, etc. Finally, there is a cost function to sort them.
We know that the essence of the optimization routine is how to hide data movement in calculations. It is nothing more than simulating the operation according to this standard and finally calculating the cost.
Q3: In addition to the default fusion rules supported by TVM, has TVM generated new fusion rules, such as unique fusion customized for different hardware in the computing layer?
A3: There are actually two levels of fusion: first, buffer fusion, and second, loop fusion. TVM fusion is actually for the latter. Xim basically follows the TVM fusion pattern you mentioned, but with some restrictions.








