Command Palette
Search for a command to run...
Siyuan Feng: Apache TVM and the Development of Machine Learning Compilation

This article was first published on HyperAI WeChat official account~
Good afternoon, welcome to Meet TVM 2023. As Apache TVM PMC,Let me share with you about the development of TVM and the future Unity framework of TVM.
Apache TVM Evolution
First of all, why is there MLC (Machine Learning Compilation)? With the continuous expansion of AI models, more requirements will emerge in actual production applications. The first layer of AI applications (as shown in the figure) of many applications are shared, including ResNet, BERT, Stable Diffusion and other models.

The second scenario is different. Developers need to deploy these models in different scenarios. The first is cloud computing and high-performance computing, which require GPU acceleration. With the acceleration of the AI field, the most important task is to bring it into thousands of households, that is, Personal PCs, Mobile phones and Edge devices.
However, different scenarios have different requirements, including reducing costs and improving performance. For example, Out of the Box needs to ensure that users can use it immediately after opening a web page or downloading an application. The mobile phone needs to save power. Edge needs to run on hardware without an OS. Sometimes, the technology needs to run on low-power, low-computing chips. These are the difficulties everyone encounters in different applications. How to solve them?
There is a consensus in the MLC field, namely, Muli-Level IR Design.The core has three layers, the first layer is Graph-Level IR, the middle layer is Tensor-Level IR, and the next layer is Hardware-Level IR. These layers are necessary because the model is a Graph, the middle layer is Tensor-Level IR, and the core of MLC is to optimize Tensor Computing. The two layers of Hardware-Level IR and Hardware are bound to each other, which means that TVM will not involve the layer of directly generating assembly instructions, because there will be some more detailed optimization techniques in the middle, which is left to the manufacturer or compiler to solve.

ML Compiler was designed with the following goals in mind:
- Dependency Minimization
First, minimize dependency deployment.The reason why AI applications have not really landed yet is because the threshold for deployment is too high. More people have run ChatGPT than Stable Diffusion not because Stable Diffusion is not powerful enough, but because ChatGPT provides an out-of-the-box environment. In my opinion, with Stable Diffusion, you need to download a model from GitHub first, then open a GPU server to deploy it, but ChatGPT is out-of-the-box. The key point of out-of-the-box is to minimize dependencies and it can be used by everyone and in all environments.
- Various Hardware Support
The second point is that it can support different hardware.Diversified hardware deployment is not the most important issue in the early stages of development, but with the development of AI chips at home and abroad, it will become more and more important, especially given the current domestic environment and the status quo of domestic chip companies, which requires us to have good support for all types of hardware.
- Compilation Optimization
The third point is general compilation optimization.By compiling the previous layers of IR, performance can be optimized, including improving operating efficiency and reducing memory usage.
Nowadays, most people regard compiling and optimizing as the most important point, but for the entire community, the first two points are critical, because this is from the perspective of the compiler, and these two points are breakthroughs from zero to one, and optimizing performance is often the icing on the cake.
Back to the topic of the speech,I divide the development of TVM into four stages:This is just my personal opinion.
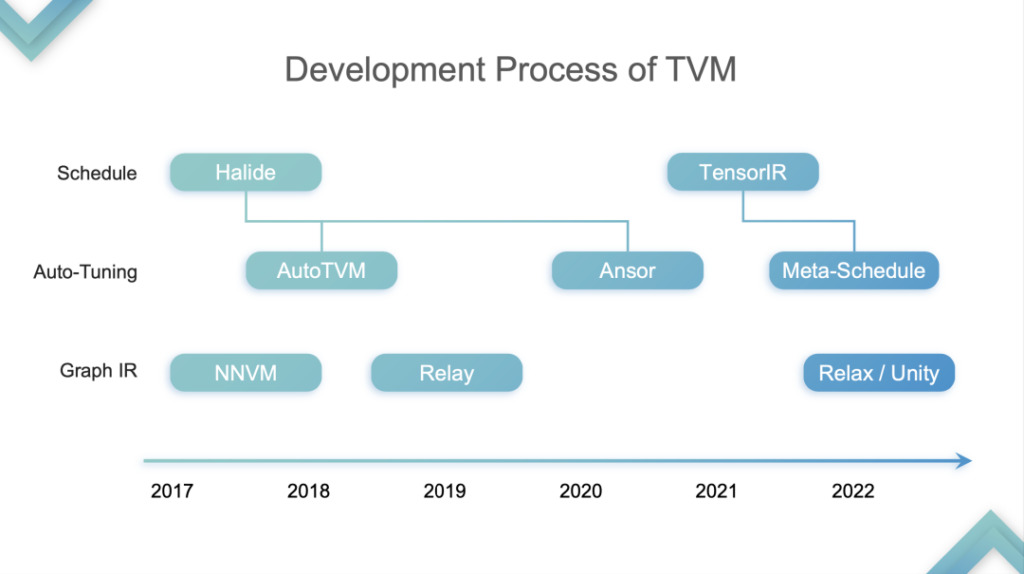
TensorIR Abstraction
Stage 1:At this stage, TVM optimizes and accelerates inference on CPU and GPU, and GPU specifically refers to the hardware part of SIMT. At this stage, many cloud computing vendors began to use TVM because they found that they could accelerate on both CPU and GPU. Why? I mentioned earlier that CPU and GPU do not have Tensorization Support. TVM's first generation TE Schedule is based on Halide and does not have good Tensorization Support. Therefore, TVM's subsequent development is based on the technical route of Halide development, including Auto TVM and Ansor, which are not friendly to Tensorization support.
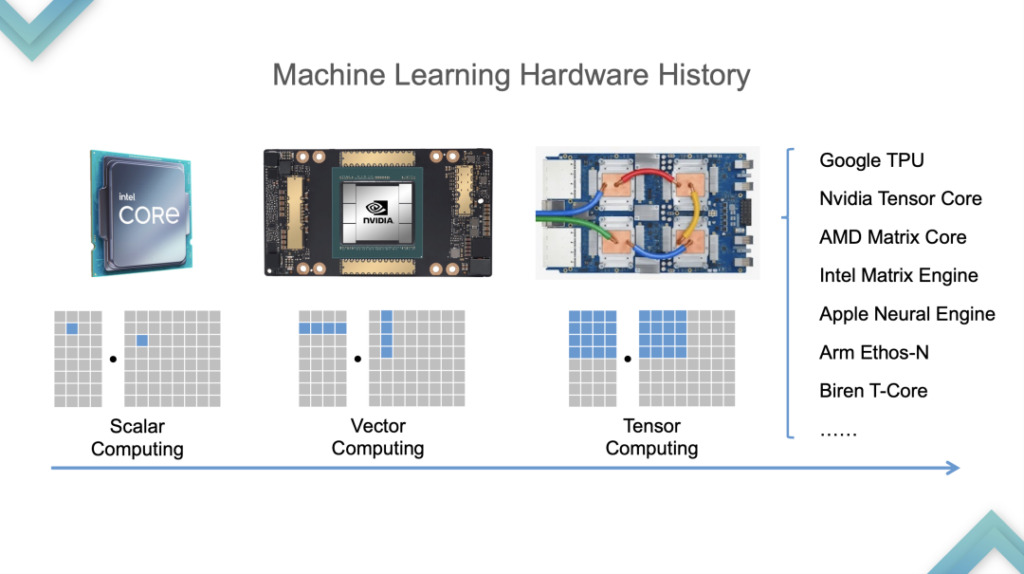
First, let’s look at the hardware development process. From CPU to GPU was around 2015 and 2016, and from GPU to TPU was around 2019. In order to support Tensorization,TVM first analyzed the characteristics of Tensorized Programs.
- Optimized loop nests with thread binding
First, a loop test is needed, which is required for all Tensorized Programs. There is multi-dimensional data loading underneath. This is different from CMT and CPU. It stores and calculates in tensors rather than scalars.
- Multi-dimensional data load/store into specialized memory buffer
Second, it is stored in a special memory buffer.
- Opaque tensorized computation body 16×16 matrix multiplication
Third, there will be a hardware pool that allows calculations. Take the following Tensor Primitive as an example. When calculating a 16*16 matrix multiplication, this calculation will no longer be expressed as a scalar combination calculation mode, but will be calculated as an account unit with one instruction.

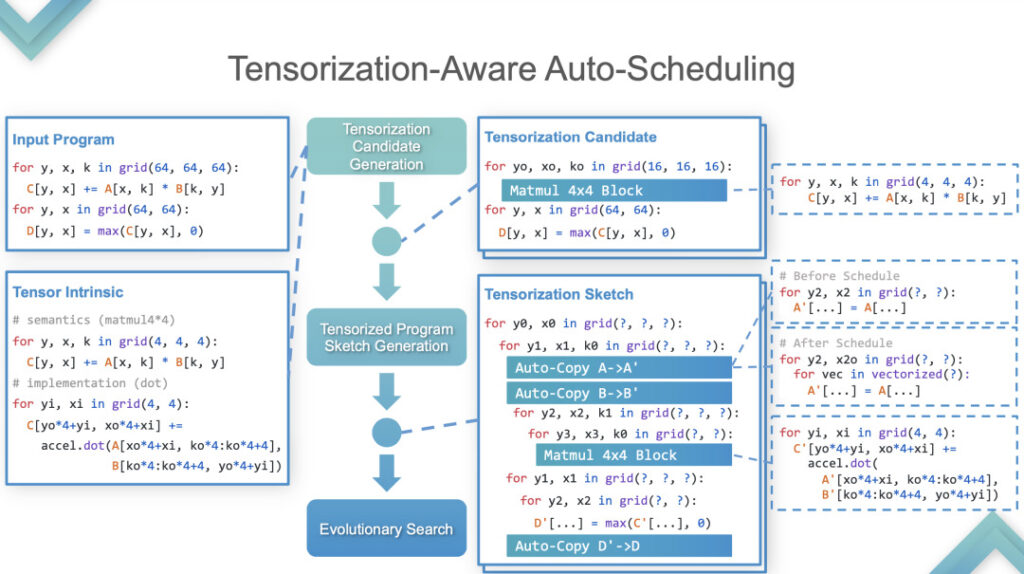
Based on the above three qualitative analyses of tensorized programs, TVM introduces computational blocks. Block is a computational unit with nesting at the outermost layer, iteration iterators and dependency relations in the middle, and body at the bottom. Its concept is to isolate the internal computation from the tensorized computation.
Stage 2:At this stage, TVM performs Auto-Tensorization. Here is an example to explain how it is implemented.

Auto-Tensorization
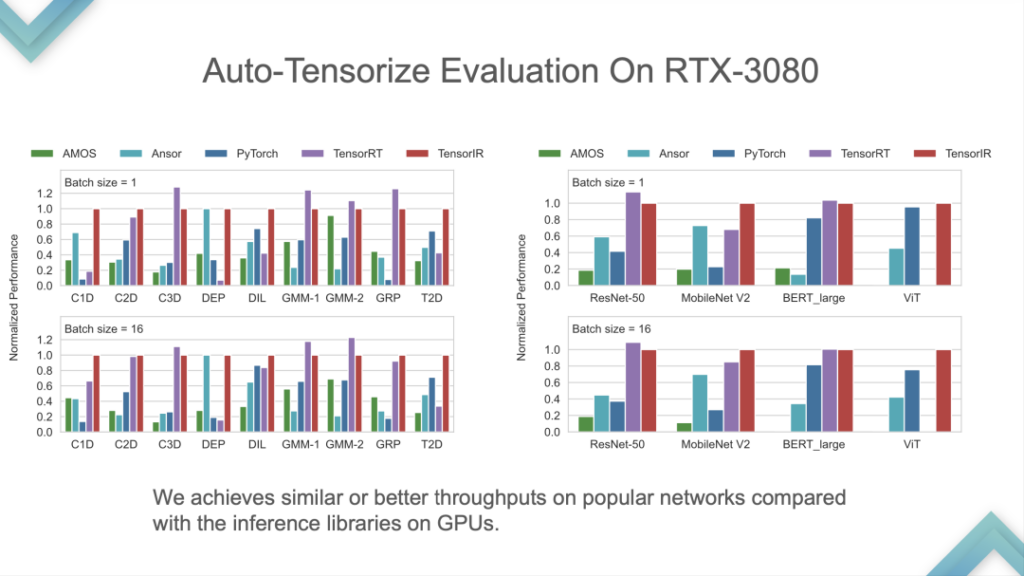
Input Program and Tensor Intrinsic were entered, and the results showed that TensorIR and TensorRT were basically on par on GPU, but not very good on some standard models. Because standard models are the standard indicators of ML Perf, NVIDIA engineers spend a lot of time on them. It is relatively rare to outperform TensorRT on standard models, which is equivalent to beating the most advanced technology in the industry.
This is a performance comparison on ARM's self-developed CPU. TensorIR and ArmComputeLib can be about 2 times faster than Ansor and PyTorch in end-to-end. Performance is not the most critical, the Auto-Tensorization idea is the core.
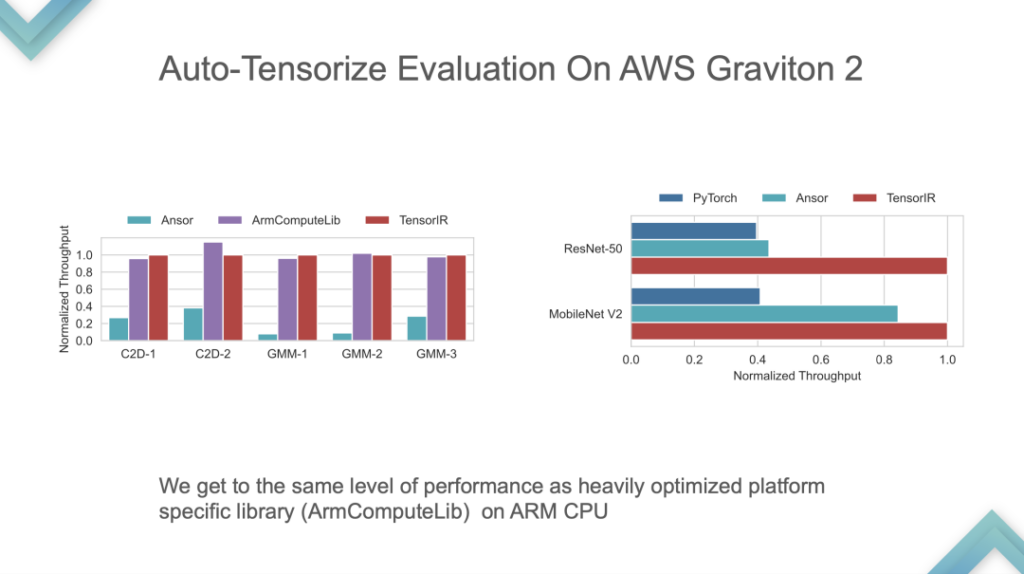
Stage 3:An End-to-End ML Compiler for Tensorized Hardware. At this stage, it can be thrown on the GPU or the supported accelerator chip, and then there are automatic tuning and model import, which is a self-consistent system. At this stage, the core of TVM is End-to-End, and a model can be developed for direct use, but customization is very difficult.
Next, I will talk about the development and thinking of Relax and Unity a little slowly, because:
- Personally, I think Relax and Unity are more important;
- It is still in the experimental stage, and many things are only ideas, lacking End-to-End demo and complete code.
Limitations of Apache TVM Stack:
- Huge Gap between Relay and TIR. The biggest problem with TVM is that the compilation paradigm from relay to TIR is too steep;
- Fixed Pipeline for Most Hardware. The standard process of TVM is Relay to TIR to? After compiling, in fact, many hardware either only supports BYOC, or wants to use BYOC+TIR, which is not well supported by Relay, Either TIR or Library. Taking GPU acceleration as an example, the underlying layer of Relay is fixed, either write CUDA for Auto Tuning, or use BYOC for TensorRT, or use cuBLAS to tune third-party libraries. Although there are many options, it is a question of choosing one or the other. This problem has a large impact and is not easy to solve on Relay.
Solution: TVM Unity.
Apache TVM Unity
The two layers of IR, Relax and TIR, are considered as a whole and merged into the Graph-TIR programming paradigm. The form of fusion: Taking the simplest Linear model as an example, in this case, the entire IR is controllable and programmable. The use of the Graph-TIR language solves the problem of the lower layer being too steep. The high-level operators can be modified step by step, and can even be changed to any BYOC or Function Calls.

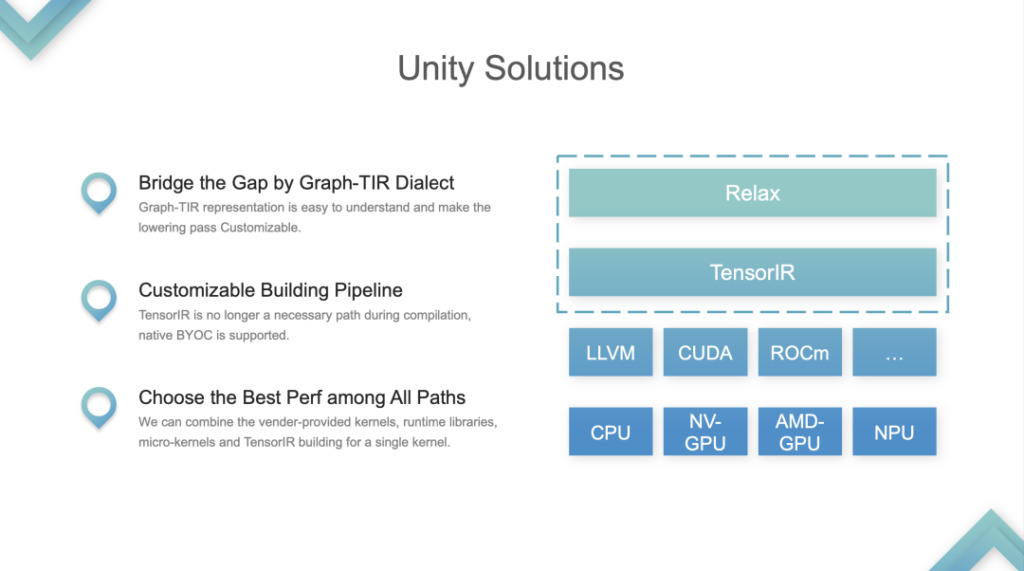
1. Support custom solutions to the problem of building pipelines. The original TVM pipeline was to relay an additional TIR, then do tuning on the TIR, and then pass it to LLVM or CUDA after tuning. This was a fixed building pipeline. Now the pipeline has changed.
2. Choose the Best Perf among All Paths. Developers can choose between library or TIR and call anything. This is the most important problem Unity solves, and the community believes that this is a unified ML compilation solution.
Misunderstanding
- TVM and MLIR are in competition
In fact, TVM and MLIR do not have a clear, equal-level competitive relationship. TVM focuses on MLC machine learning compilation, while MLIR emphasizes Multi-Level, and its features can also be used for ML compilation. Developers use MLIR for machine learning compilation, on the one hand because MLIR has native docking with frameworks such as PyTorch, and on the other hand because before Unity, TVM's customization capabilities were relatively weak.
- TVM = Inference Engine for CPU/GPU
TVM has never been an inference engine. It can do compilation, and developers can use it to accelerate inference. TVM is a compiler infrastructure, but not an inference engine. The idea that "TVM can only be used for acceleration" is wrong. The fundamental reason why TVM can be used for acceleration is that it is a compiler, which is faster than the eager mode execution method such as PyTorch.
- TVM = Auto Tuning
Before Relax appeared, the first reaction of everyone to TVM was that they could get better performance through Auto Tuning. The next development direction of TVM is to dilute this concept. TVM provides various ways to achieve better performance and customize the entire compilation process. What TVM Unity needs to do is to provide a set of architectures to combine various advantages.
Next Step
In the next step, TVM will develop into a Cross-Layer Machine Learning Compiler Infrastructure and strive to become a customizable Building Pipeline for Different Backends, supporting customization on different hardware. This requires combining various methods and integrating the strengths of various parties.
Q & A
Q 1: Does TVM have any plans to optimize large models?
A 1: We have some preliminary ideas for large models. TVM has already started to do distributed reasoning and some simple training, but it will take some time before it can be truly implemented.
Q 2: What support and evolution will Relax have in Dynamic Shape in the future?
A 2: Relay VM supports Dynamic shape, but does not generate Symbolic Deduction. For example, the output of nmk matrix multiplication is n and m, but in Relay, the three nmks are collectively referred to as Any, which is an unknown dimension, and the output is also an unknown dimension. Relay VM can run these tasks, but some information will be lost during the compilation phase, so Relax solves these problems. This is Relax's improvement on Relay in Dynamic Shape.
Q 3: The combination of TVM optimization and device optimization. If Graph is used to generate instructions directly, TE and TIR seem to be rarely used in device optimization. If BYOC is used, TE and TIR seem to be skipped. It was mentioned in the sharing that Relax may have some customization, which seems to be able to solve this problem.
A 3: In fact, many hardware manufacturers have already taken the TIR route, while some manufacturers have not paid attention to related technologies and still choose the BYOC method. BYOC is not a compilation in the strict sense, and it has restrictions on the building pattern. In general, it is not that enterprises cannot use community technologies, but that they have made different choices based on their own circumstances.
Q4: Will the emergence of TVM Unity involve higher migration costs? From the perspective of TVM PMC, how can we help users smoothly transition to TVM Unity?
A 4: The TVM community has not abandoned Relay, but has only added the Relax option. Therefore, the old version will continue to evolve, but in order to use some new features, some code and version migration may be required.
After Relax is fully released, the community will provide migration tutorials and certain tool support to support the direct import of Relay models into Relax. However, migrating the customized version developed based on Relay to Relax still requires a certain amount of work, which will take about a month for a team of more than a dozen people in the company.
Q 5: TensorIR has made great progress in Tensor compared to before, but I noticed that TensorIR is mainly aimed at programming models such as SIMT and SIMD, which are mature programming methods. Is there any progress in TensorIR in many new AI chips and programming models?
A 5: From the community's perspective, the reason why TensorIR uses the SIMT model is that only SIMT hardware can be used now. Many manufacturers' hardware and instruction sets are not open source. The hardware that can be accessed from major manufacturers is basically only CPU, GPU and some mobile phone SoCs. The community of other manufacturers basically cannot access them, so it cannot be based on their programming models. In addition, even if the community and enterprises cooperate to create a TIR of a similar level, it cannot be open sourced. This is due to commercial operation considerations.
The above is a summary of Feng Siyuan’s speech at the 2023 Meet TVM Shanghai Station.Next, the detailed content shared by other guests of this event will also be released on this official account one after another. Please continue to pay attention!
Get the PPT:Follow the WeChat public account "HyperAI Super Neural Network" and reply with the keyword in the background TVM Shanghai,Get the full PPT.
TVM Chinese Documentation:https://tvm.hyper.ai/
GitHub address:https://github.com/apache/tvm








