Command Palette
Search for a command to run...
The AI Company Behind "Instant Universe" Was Involved in the Development of Stable Diffusion and Received $50 Million in Financing Last year.

This article was first published on HyperAI WeChat official account~
On the morning of March 13th, Beijing time, the 2023 Oscars ceremony was held in Los Angeles., the film "Blink of an Eye" won seven awards in one fell swoop and became the biggest winner.The lead actress Michelle Yeoh also won the Academy Award for Best Actress for this film, becoming the first Chinese actress in Oscar history.

It is understood that the visual effects team behind this hotly debated sci-fi film has only 5 people. In order to complete these special effects shots as quickly as possible, they chose Runway's technology to help create certain scenes, such as the green screen tool (The Green Screen) to remove the background of the image.
"Just a few clicks saves me hours, and I can use that time to try three or four different effects to make the film better," said director and screenwriter Evan Halleck in an interview.

Runway: Participated in the development of the first generation of Stable Diffusion
At the end of 2018, Cristóbal Valenzuela and other members founded Runway.It is an artificial intelligence video editing software provider that is committed to using the latest advances in computer graphics and machine learning to lower the threshold for content creation for designers, artists and developers and promote the development of creative content.

Only about 40 employees
besides,Runway also has a lesser-known identity – it was a major participant in the initial version of Stable Diffusion.
In 2021, Runway worked with the University of Munich in Germany to build the first version of Stable Diffusion. Subsequently, British startup Stability AI "brought in funding" and provided Stable Diffusion with more computing resources and funds needed for model training. However, Runway and Stability AI are no longer working together.
In December 2022, Runway received US$50 million in Series C financing. In addition to the "Blink" team, its clients also include media groups CBS and MBC, advertising companies Assembly and VaynerMedia, and design company Pentagram.
On February 6, 2023, Runway’s official Twitter account released the Gen-1 model.You can transform an existing video into a new one by applying any style specified by textual cues or reference images.
Gen-1: structure + content
Researchers proposed a structure- and content-guided video diffusion model–Gen-1, which can edit videos based on the visual or textual description of the expected output.
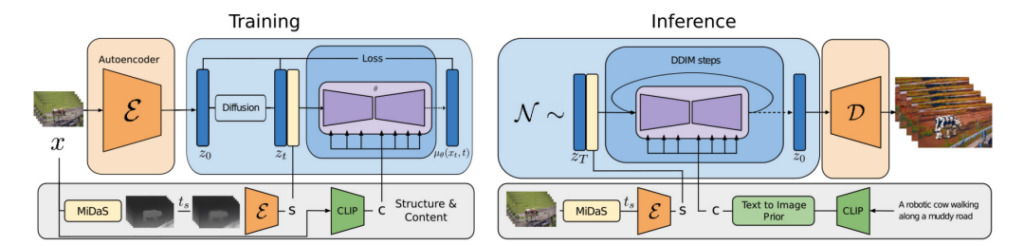
The so-called content refers to the features that describe the appearance and semantics of the video, such as the color and style of the target object and the lighting of the scene.
Structure refers to the description of its geometric and dynamic characteristics, such as the shape, position and time changes of the target object.
The goal of the Gen-1 model is to edit video content while preserving the video structure.
During the model training process, the researchers used a large-scale dataset consisting of uncaptioned videos and text-image pairs. At the same time, monocular scene depth estimates were used to represent the structure, and the embeddings predicted by a pre-trained neural network were used to represent the content.
This approach provides several powerful modes of control over the generation process:
1. Refer to the image synthesis model and train the model so that the inferred video content (such as presentation or style) matches the image or prompt provided by the user.

2. Refer to the diffusion process and perform information obscuring on the structure representation, which allows developers to set the degree of similarity of model adherence to a given structure.
3. Refer to classifier-free guidance and use custom guidance methods to adjust the reasoning process to control the temporal consistency of the generated clips.
In this experiment, researchers:
- We extend the latent diffusion model to video generation by introducing a temporal layer into the pre-trained image model and jointly training images and videos.
- We propose a structure- and content-aware model that can modify videos under the guidance of example images or text. Video editing is performed entirely at the inference stage, without the need for video-by-video training or preprocessing.
- Full control over temporal, content, and structure consistency. Experiments show that joint training on image and video data enables control of temporal consistency during inference. For structural consistency, training at different levels of detail in the representation allows the user to choose the desired setting during inference.
- A user survey showed that this method was more popular than several other methods.
- By fine-tuning on a small subset of images, the trained model can be further customized to generate more accurate videos of specific subjects.
To evaluate the performance of Gen-1, the researchers used videos from the DAVIS dataset and a variety of other material.To automatically create edit prompts, the researchers first ran a captioning model to obtain a description of the original video content and then used GPT3 to generate edit prompts.
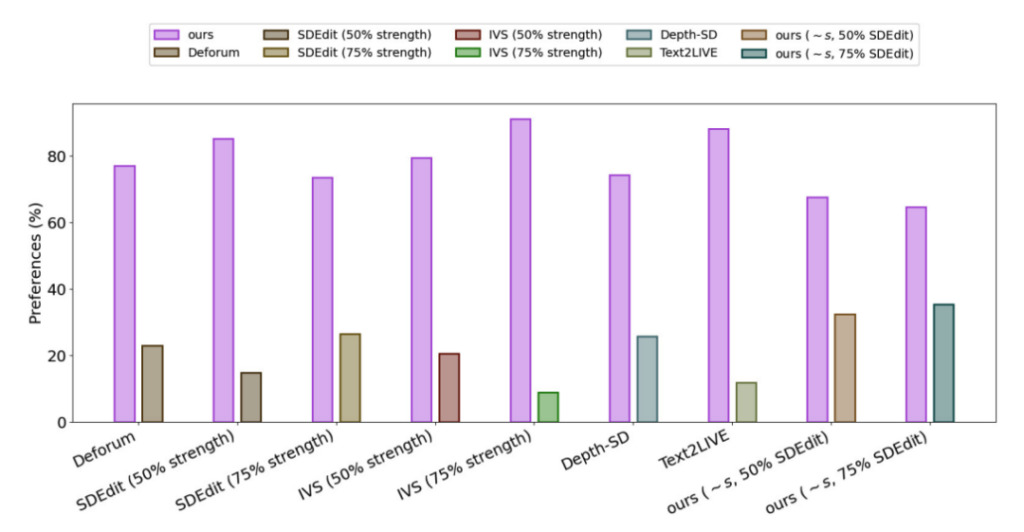
The experimental results show that in the satisfaction survey of all the methods,75% users prefer the Gen-1 generation effect.
AIGC: Moving forward amid controversy
In 2022, generative AI has become the most eye-catching technology since the rise of mobile and cloud computing more than a decade ago, and we are fortunate to witness the budding of its application layer.Many large models are rapidly emerging from laboratories and are being applied to various scenarios in the real world.
However, despite its many benefits such as improving efficiency and saving costs, we also need to see that generative artificial intelligence still faces many challenges, including how to improve the output quality and diversity of the model, how to increase its generation speed, as well as security, privacy, and ethical and religious issues during the application process.
Some people have questioned AI art creation, and some even think it is an "invasion" of art by AI. Faced with this voice, Runway co-founder and CEO Cristóbal Valenzuela believes that AI is just a tool in the toolbox used to color or modify images and other content, no different from Photoshop or LightRoom.Although generative AI is still controversial, it opens the door to creation for non-technical people and creative people, and will lead the field of content creation to new possibilities.
Reference Links:
[1]https://hub.baai.ac.cn/view/23940
[2]https://cloud.tencent.com/developer/article/2227337?








