Command Palette
Search for a command to run...
Taking the Animated Drawings APP As an Example, Use TorchServe to Tune the Model
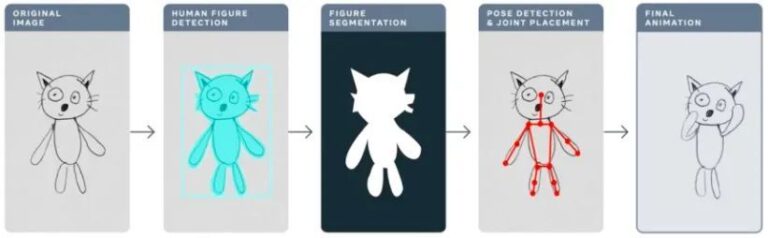
Contents The previous section introduced the five steps of TorchServe model deployment and optimization to deploy the model into the production environment. This section takes the Animated Drawings APP as an example to demonstrate the model optimization effect of TorchServe. This article was first published on WeChat official account:PyTorch Developer Community
Last year, Meta used the Animated Drawings app to make children's hand-drawn drawings "animated" with AI, turning static stick drawings into animations in seconds.


Animated Drawingssketch.metademolab.com/
This is not easy for AI. AI was originally designed to process images in the real world. Children's drawings are different in form and style from real images, and are more complex and unpredictable. Therefore, previous AI systems may not be suitable for tasks like Animated Drawings.
This article will take Animated Drawings as an example to explain in detail how to use TorchServe to tune the model that will be deployed to the production environment.
4 factors that affect model tuning in production environments
The following workflow shows the overall idea of using TorchServe to deploy a model in a production environment.

In most cases, models deployed to production environments are optimized based on throughput or latency service level agreements (SLAs).
Usually real-time applications are more concerned with latency, while off-line applications are more concerned with throughput.
There are many factors that affect the performance of models deployed in production environments. This article focuses on four of them:
1. Model optimizations
This is a pre-step to deploying models to production environments, including quantization, pruning, using IR graphs (TorchScript in PyTorch), fusing kernels, and many other techniques. Currently, many of these techniques are available as CLI tools in TorchPrep.
2. Batch inference
It refers to feeding multiple inputs into a model. It is frequently used during the training process and is also helpful for controlling costs during the inference phase.
Hardware accelerators are optimized for parallelism, and batching helps to fully utilize computing power, which often leads to higher throughput. The main difference in inference is that you don’t have to wait too long to get a batch from the client, which is what we often call dynamic batching.
3. Numbers of Workers
TorchServe deploys models through workers. Workers in TorchServe are Python processes that have copies of model weights for inference. Too few workers will not benefit from sufficient parallelism; too many workers will lead to reduced worker contention and end-to-end performance.
4. Hardware
Choose a suitable hardware from TorchServe, CPU, GPU, AWS Inferentia based on your model, application, latency, and throughput budget.
Some hardware configurations are designed to obtain the best class performance, while others are designed to better meet expected cost control. Experiments show that GPUs are more suitable when the batch size is large; when the batch size is small or low latency is required, CPUs and AWS Inferentia are more cost-effective.
Tips: Things to note when optimizing TorchServe performance
Before you begin,Let’s first share some tips on deploying models with TorchServe and getting the best performance.
* Learn PyTorch official tutorial
Hardware selection is also closely linked to model optimization selection.
The choice of hardware for model deployment is closely related to latency, throughput expectations, and the cost of each inference.
Due to the differences in model size and application, CPU production environments are usually not able to afford the deployment of similar computer vision models.You can register to use OpenBayes.com, and you will get 3 hours of RTX3090 for free when you register, and 10 hours of RTX3090 for free every week to meet general GPU needs.
Furthermore, optimizations such as IPEX recently added to TorchServe make such models cheaper to deploy and more CPU-affordable.
For details on IPEX optimization model deployment, please refer to
* The worker in TorchServe belongs to the Python process.Can provide parallel,The number of workers should be set with caution.By default, TorchServe starts a number of workers equal to the number of VCPUs or available GPUs on the host, which may add considerable time to TorchServe startup.
TorchServe exposes a config property to set the number of workers. In order to allow multiple workers to provide efficient parallelism and avoid them competing for resources, it is recommended to set the following baseline on CPU and GPU:
CPU:Set in handler torch.set_num_threads(1) . Then set the number of workers to num physical cores / 2 But the best thread configuration can be achieved by utilizing the Intel CPU launcher script.
GPU:The number of available GPUs can be set in config.properties number_gpus TorchServe uses round-robin to assign workers to GPUs. Recommendations:Number of workers = (Number of available GPUs) / (Number of Unique Models)Note that pre-Ampere GPUs do not provide any resource isolation with Multi Instance GPUs.
* Batch size directly affects latency and throughput.In order to better utilize computing resources, the batch size needs to be increased. There is a tradeoff between latency and throughput; a larger batch size can improve throughput but also result in higher latency.
There are two ways to set the batch size in TorchServe.One is through model config in config.properties, and the other is registering the model using the Management API.
The next section shows how to use the TorchServe benchmark suite to determine the best combination of hardware, workers, and batch size for model optimization.
Meet TorchServe Benchmark Suite
To use the TorchServe benchmark suite, you first need an archived file, which is the one mentioned above. .mar File. This file contains the model, handler, and all other artifacts used to load and run inference. Animated Drawing APP uses Detectron2's Mask-rCNN target detection model
Running the benchmark suite
The Automated benchmark suite in TorchServe can benchmark multiple models under different batch sizes and worker settings and output reports.
learn Automated benchmark suite
Start running:
git clone https://github.com/pytorch/serve.git cd serve/benchmarks pip install -r requirements-ab.txt apt-get install apache2-utils
Configure model level settings in the yaml file:
Model_name: eager_mode: benchmark_engine: "ab" url: "Path to .mar file" workers: - 1 - 4 batch_delay: 100 batch_size: - 1 - 2 - 4 - 8 requests: 10000 concurrency: 10 input: "Path to model input" backend_profiling: False exec_env: "local" processors: - "cpu" - "gpus": "all"
This yaml file will be benchmark_config_template.yaml The yaml file contains other settings for generating reports and viewing logs with AWS Cloud.
python benchmarks/auto_benchmark.py --input benchmark_config_template.yaml
Run the benchmark and the results are saved in a csv file. _/tmp/benchmark/ab_report.csv_ or full report /tmp/ts_benchmark/report.md Found in.
Results include TorchServe average latency, model P99 latency, throughput, concurrency, number of requests, handler time, and other metrics.
Focus on tracking the following factors that affect model tuning: concurrency, model P99 latency, and throughput.
These numbers need to be considered in conjunction with the batch size, the equipment used, the number of workers, and whether model optimization has been performed.
The latency SLA for this model has been set to 100 ms. This is a real-time application, latency is an important issue, and throughput should be as high as possible without violating the latency SLA.
By searching the space, we run a series of experiments on different batch sizes (1-32), numbers of workers (1-16), and devices (CPU, GPU), and summarize the best experimental results, as shown in the following table:

This model tried all the latency on CPU, batch size, concurrency and number of workers, but all failed to meet the SLA, and actually reduced latency by 13 times.
Moving model deployment to the GPU immediately reduced latency from 305ms to 23.6ms.
One of the simplest optimizations you can do for your model is to reduce its precision to fp16, which is a one-line code (model.half()) , can reduce the model P99 latency of 32% and increase the throughput by almost the same amount.
Another way to optimize the model is to convert the model to TorchScript and use optimization_for_inference or other techniques (including onnx or tensor runtime optimizations) that take advantage of aggressive fusions.
On CPU and GPU, set number of workers=1 This works best for the case in this article.
* Deploy the model to the GPU and set number of workers = 1, batch size = 1, throughput increased by 12 times and latency reduced by 13 times compared to CPU.
* Deploy the model to the GPU and set model.half(), number of workers = 1 , batch size = 8, we can achieve the best results in terms of throughput and affordable latency. Compared to the CPU, the throughput is increased by 25 times, and the latency still meets the SLA (94.4 ms).
Note: If you are running a benchmark suite, make sure you set the appropriate batch_delay, sets the concurrency of requests to a number proportional to the batch size. Concurrency here refers to the number of concurrent requests sent to the server.
Summarize
This article introduces the considerations for tuning the TorchServe model in a production environment and the TorchServe benchmark suite for performance optimization, giving users a deeper understanding of possible choices for model optimization, hardware selection, and overall cost.
focus on PyTorch Developer CommunityOfficial account to get more PyTorch technology updates, best practices and related information!








