Command Palette
Search for a command to run...
Absolutely! OpenAI Will Release a New Product at the End of the Year, Generating 3D Point Cloud in 1 Minute With a Single Card, and text-to-3D Will Bid Farewell to the Era of High Computing Power Consumption
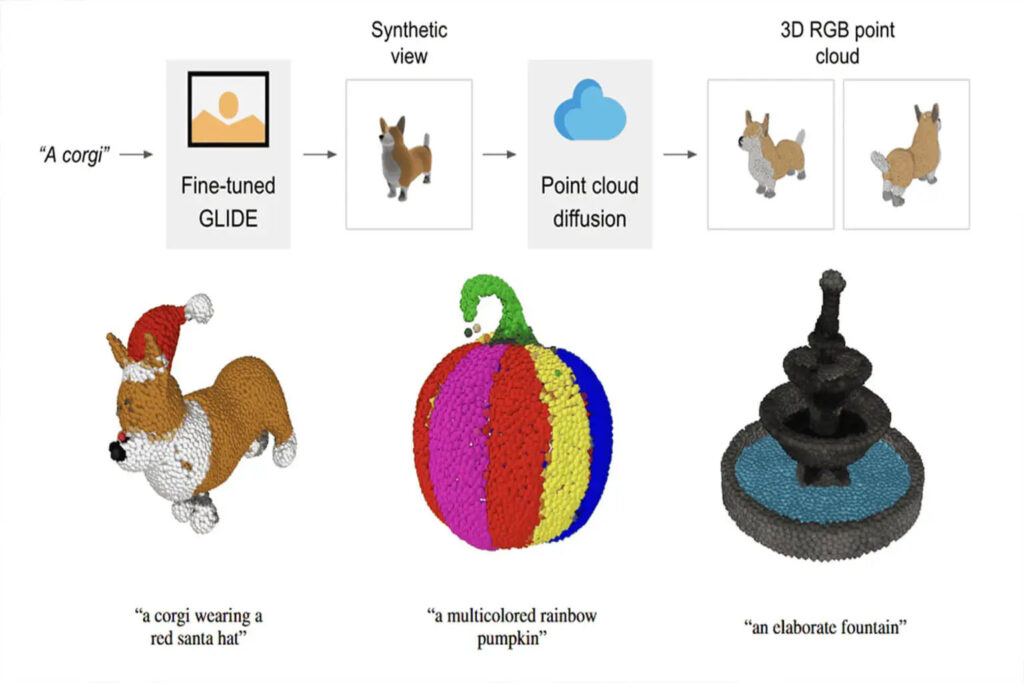
Contents at a glance:Following DALL-E and ChatGPT, OpenAI has made another effort and recently released Point·E, which can directly generate 3D point clouds based on text prompts. Keywords:OpenAI 3D Point Cloud Point E
OpenAI is striving for year-end performance. More than half a month ago, it released ChatGPT, but many netizens still haven’t figured it out. Recently, it quietly released another powerful tool – Point·E, which can directly generate 3D point clouds based on text prompts.
text-to-3D: With the right approach, one can do two things
I believe everyone is familiar with 3D modeling. In recent years, 3D modeling can be seen in fields such as film production, video games, industrial design, VR and AR.
However, creating realistic 3D images with the help of artificial intelligence is still a time-consuming and labor-intensive process.Taking Google DreamFusion as an example, generating 3D images from given text usually requires multiple GPUs and running for several hours.

Generally speaking, text-to-3D synthesis methods fall into two categories:
Method 1:Train generative models directly on paired (text, 3D) data or unlabeled 3D data.
Although such methods can effectively generate samples by leveraging existing generative model methods, they are difficult to extend to complex text prompts due to the lack of large-scale 3D datasets.
Method 2:Leverage pre-trained text-to-image models to optimize for differentiable 3D representations.
Such methods are usually able to handle complex and diverse textual cues, but the optimization process for each sample is expensive. In addition, due to the lack of a strong 3D prior, such methods may fall into local minima (which cannot correspond to a meaningful or coherent 3D object one-to-one).
Point·E combines text-to-image model and image-to-3D model.Combining the advantages of the above two methods,The efficiency of 3D modeling has been further improved, and only one GPU and one or two minutes are needed to complete the conversion of text to 3D point cloud.
Principle analysis: 3 steps to generate 3D point cloud
In Point E, the text-to-image model leverages a large corpus (text, image pair) to enable it to properly handle complex text prompts; the image-to-3D model is trained on a smaller dataset (image, 3D pair).
The process of generating a 3D point cloud based on text prompts using Point·E is divided into three steps:
1. Generate a synthetic view based on the text prompt
2. Generate a coarse point cloud (1024 points) based on the synthetic view
3. Generate fine point cloud (4096 Point) based on low-resolution point cloud and synthetic view

Since data format and data quality have a huge impact on training results,Point·E used Blender to convert all training data into a common format.
Blender supports multiple 3D formats and comes with an optimized rendering engine. The Blender script unifies the model into a bounding cube, configures a standard lighting setup, and finally exports an RGBAD image using Blender's built-in real-time rendering engine.
""" Script to run within Blender to render a 3D model as RGBAD images. Example usage blender -b -P blender_script.py -- \ --input_path ../../examples/example_data/corgi.ply \ --output_path render_out Pass `--camera_pose z-circular-elevated` for the rendering used to compute CLIP R-Precision results. The output directory will include metadata json files for each rendered view, as well as a global metadata file for the render. Each image will be saved as a collection of 16-bit PNG files for each channel (rgbad), as well as a full grayscale render of the view. """
Blender script code
By running the script, the 3D model is uniformly rendered as an RGBAD image
For the complete script, see:
Previous text-to-3D AI comparison
In the past two years, there have been many explorations on text-to-3D model generation.Major companies such as Google and NVIDIA have also launched their own AI.
We have collected and compiled three text-to-3D synthesis AIs for you to compare the differences horizontally.
DreamFields
Publishing Agency:Google
Release time:December 2021
Project address:https://ajayj.com/dreamfields
DreamFields combines neural rendering with multimodal image and text representation.Based on text descriptions alone, it is possible to generate a variety of 3D object shapes and colors without 3D supervision.

In the process of DreamFields generating 3D objects,It draws on the image-text model pre-trained on a large text image dataset and optimizes the Neural Radiance Field from multiple perspectives.This enables images rendered by the pre-trained CLIP model to achieve good results on the target text.
DreamFusion
Publishing Agency:Google
Release time:September 2022
Project address:https://dreamfusion3d.github.io/
DreamFusion can achieve text-to-3D synthesis with the help of a pre-trained 2D text-to-image diffusion model.
DreamFusion introduces a loss based on probability density distillation, which enables the 2D diffusion model to be used as a prior for optimizing the parametric image generator.

By applying this loss in a similar procedure to DeepDream, Dreamfusion optimizes a randomly initialized 3D model (a Neural Radiance Field, or NeRF) to a relatively low loss for 2D renderings from random angles via gradient descent.
Dreamfusion does not require 3D training data, nor does it need to modify the image diffusion model.The effectiveness of pre-trained image diffusion model as a prior is demonstrated.
Magic3D
Publishing Agency:NVIDIA
Release time:November 2022
Project address:deepimagination.cc/Magic3D/
Magic3D is a text-to-3D content creation tool that can be used to create high-quality 3D mesh models.Using image conditioning technology and text-based prompt editing methods, Magic3D provides new ways to control 3D synthesis, opening up new avenues for a variety of creative applications.
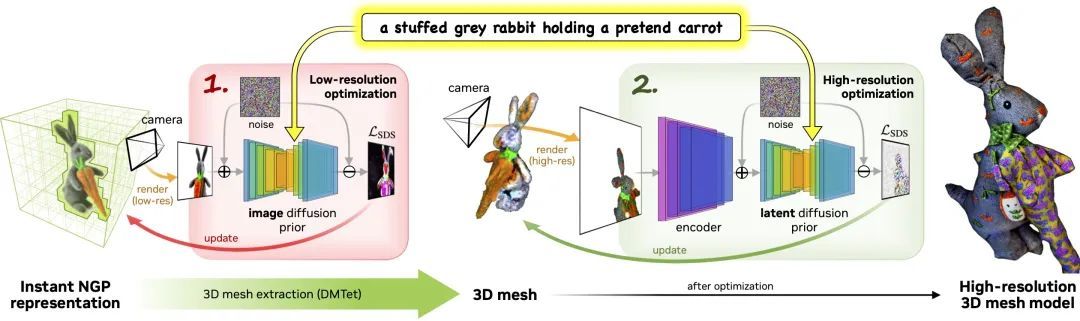
The process consists of two stages:
Phase 1:Use a low-resolution diffusion prior to obtain a coarse model, and use hash grid and sparse acceleration structure to accelerate it.
Phase 2:A textured mesh model initialized from a coarse neural representation is optimized via an efficient differentiable renderer interacting with a high-resolution latent diffusion model.
Technological progress still needs to break through limitations
Text-to-3D AI is gradually being released, but text-based 3D synthesis is still in its early stages of development.There is no universally recognized benchmark in the industry that can be used to more fairly evaluate related tasks.
Point·E is of great significance for fast text-to-3D synthesis.It greatly improves processing efficiency and reduces computing power consumption.
But it is undeniable thatPoint E still has certain limitations.For example, the pipeline requires synthetic rendering, and the generated 3D point cloud has a low resolution, which is not enough to capture fine-grained shapes or textures.
What do you think about the future of text-to-3D synthesis? What will be the future development trend? Welcome to leave a message in the comment section to discuss.








