Command Palette
Search for a command to run...
PyTorch 2.0 Is Released: Compile, Compile, and Compile!

Contents at a glance: At the PyTorch Conference 2022 held last night, PyTorch 2.0 was officially released. This article will sort out the biggest differences between PyTorch 2.0 and 1.x. Keywords: PyTorch 2.0 Compiler Machine Learning This article was first published on WeChat official account: HypeAI Super Neural
At the PyTorch Conference 2022, PyTorch officially released PyTorch 2.0. The entire event had a very high "compiler" rate. Compared with the previous 1.x version, 2.0 has undergone "disruptive" changes.
PyTorch 2.0 released a lot of new features that are enough to change the way you use PyTorch.It provides the same eager mode and user experience, while adding a compilation mode through torch.compile.The model can be accelerated during training and inference, providing better performance and support for Dynamic Shapes and Distributed.
This article will provide a detailed introduction to PyTorch 2.0.
Too long to read
- PyTorch 2.0 retains its original advantages while greatly supporting compilation
- torch.compile is an optional function that can run compilation with just one line of code
- 4 important technologies: TorchDynamo, AOTAutograd, PrimTorch and TorchInductor
- I tried compiling it 5 years ago, but the results were not satisfactory.
- PyTorch 1.x code does not need to be migrated to 2.0* PyTorch 2.0 stable version is expected to be released in March next year
Faster, better, compiled support
At last night’s PyTorch Conference 2022,torch.compile was officially released.It further improves the performance of PyTorch and begins to move parts of PyTorch back from C++ to Python.
The latest technologies in PyTorch 2.0 include:
TorchDynamo, AOTAutograd, PrimTorch and TorchInductor.
1. TorchDynamo
It can safely obtain PyTorch programs with the help of Python Frame Evaluation Hooks. This major innovation is a summary of PyTorch's research and development results in safe graph capture over the past five years.
2. AOTAutograd
Overload the PyTorch autograd engine as a tracing autodiff to generate advanced backward traces.
3. PrimTorch
The 2000+ PyTorch operators are summarized into a closed set of about 250 primitive operators, and developers can build a complete PyTorch backend for these operators. PrimTorch greatly simplifies the process of writing PyTorch functions or backends.
4. TorchInductor A deep learning compiler that generates fast code for multiple accelerators and backends. For NVIDIA GPUs, it uses OpenAI Triton as a key building block.
TorchDynamo, AOTAutograd, PrimTorch, and TorchInductor are written in Python.And support for dynamic shape (the ability to send vectors of different sizes without recompiling) makes them flexible and easy to learn, lowering the entry barrier for developers and vendors.
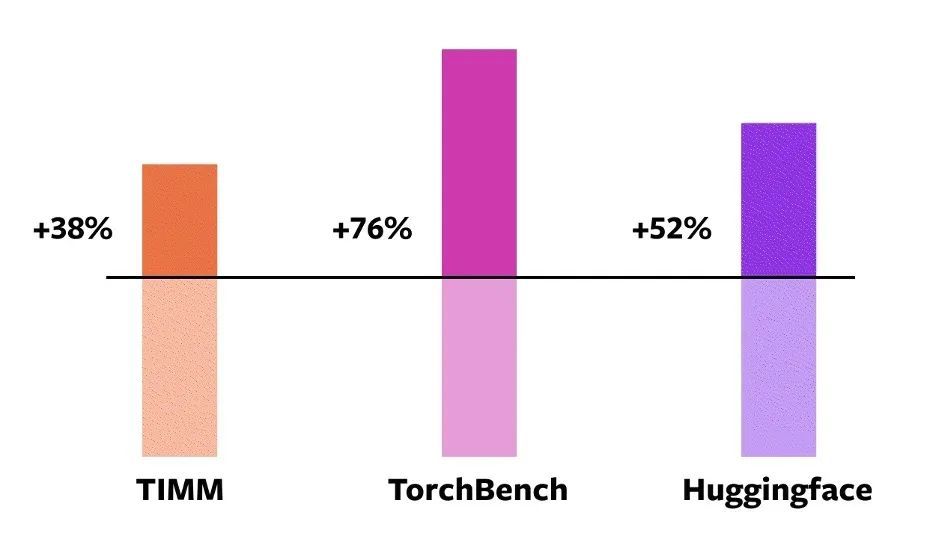
To validate these techniques,PyTorch officially uses 163 open source models in the field of machine learning.These include tasks such as image classification, object detection, image generation, and various NLP tasks such as language modeling, question answering, sequence classification, recommendation systems, and reinforcement learning.These benchmarks are divided into three categories:
- 46 models from HuggingFace Transformers
- 61 Models from TIMM: SoTA PyTorch Image Models Collection by Ross Wightman
- 56 models from TorchBench: A collection of popular repositories on GitHub.
For open source models,PyTorch has not officially made any changes, but has added a torch.compile call for encapsulation.
Next, PyTorch engineers measured speed and verified accuracy in these models, since speedups can depend on the data type.Therefore, we measured the speedup on both float32 and automatic mixed precision (AMP).Since AMP is more common in practice, the test ratio is set to: 0.75 * AMP + 0.25 * float32.
Among these 163 open source models,torch.compile can run normally on the 93% model.After running, the model's running speed on the NVIDIA A100 GPU increased by 43%. Under Float32 precision, the running speed increased by an average of 21%; under AMP precision, the running speed increased by an average of 51%.
Note: On desktop-class GPUs (such as NVIDIA 3090), the measured speed is lower than on server-class GPUs (such as A100). As of now, the default backend TorchInductor of PyTorch 2.0 already supports CPUs and NVIDIA Volta and Ampere GPUs, and does not currently support other GPUs, xPUs, or older NVIDIA GPUs.
 NVIDIA A100 GPU eager mode torch.compile speedup for different models
NVIDIA A100 GPU eager mode torch.compile speedup for different models
Try torch.compile online:Developers can install and try it out through the nightly binary file. The PyTorch 2.0 Stable version is expected to be released in early March 2023.
In the PyTorch 2.x roadmap, the performance and scalability of the compiled mode will continue to be enriched and improved in the future.
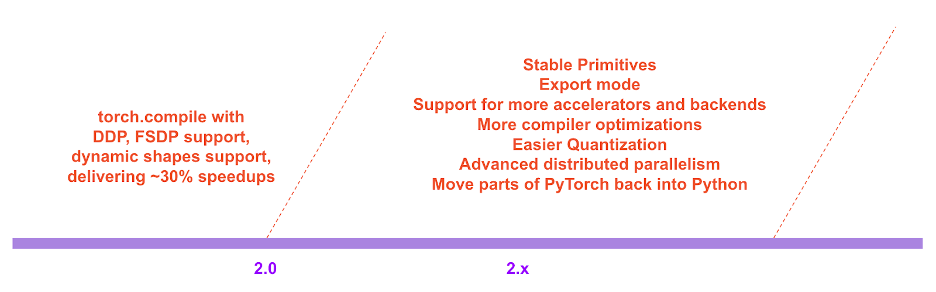 PyTorch 2.x roadmap
PyTorch 2.x roadmap
Development Background
The development philosophy of PyTorch has always been to put flexibility and hackability first, and performance second.Committed to:
1. High-performance eager execution
2. Continuously Pythonize the internal structure
3. Good abstraction of Distributed, Autodiff, Data loading, Accelerators, etc.
Since PyTorch was introduced in 2017, hardware accelerators (such as GPUs) have increased computation speed by about 15 times and memory access speed by about 2 times.
In order to maintain high-performance eager execution, most of the internal content of PyTorch had to be moved to C++, which reduced the hackability of PyTorch and increased the threshold for developers to participate in code contributions.
From day one, PyTorch officials were aware of the performance limitations of eager execution. In July 2017, officials began working on developing a compiler for PyTorch. This compiler needs to speed up the running of PyTorch programs without sacrificing the PyTorch experience.The key criterion was to maintain a certain degree of flexibility: supporting dynamic shapes and dynamic programs, which are widely used by developers.

PyTorch Technical Details
Since its launch, several compiler projects have been built in PyTorch.These compilers can be divided into 3 categories:
- Graph Acquisition
- Graph lowering
- Graph compilation
Among them, the acquisition of graph structure faces the most challenges.
In the past five years, we have tried torch.jit.trace, TorchScript, FX tracing and Lazy Tensors, but some of them are flexible but not fast enough, some are fast enough but not flexible, some are neither fast nor flexible, and some have poor user experience.
Although TorchScript is promising,But it requires a lot of code and dependency modifications, and is not very feasible.
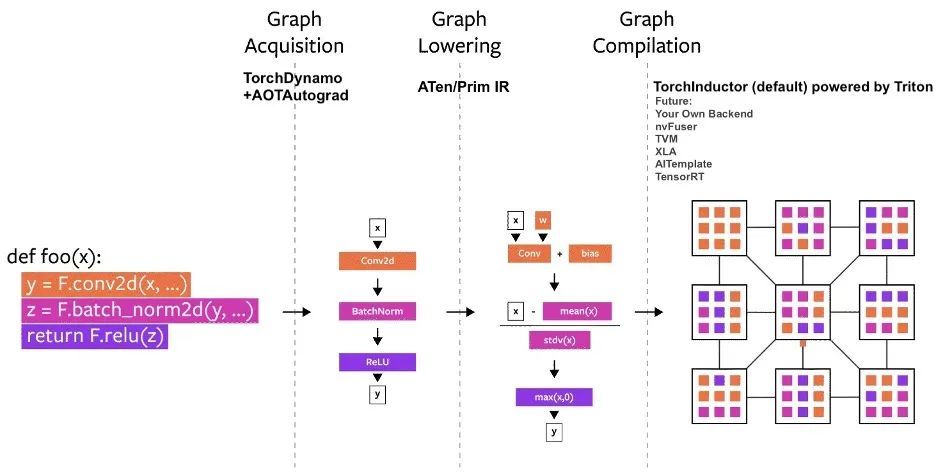 PyTorch compilation process diagram
PyTorch compilation process diagram
TorchDynamo: Reliably and quickly obtain graph structure
TorchDynamo uses a CPython feature introduced in PEP-0523 called the Frame Evaluation API. The official took a data-driven approach to verify its effectiveness on Graph Capture, using more than 7,000 Github projects written in PyTorch as a validation set.
Experiments show thatTorchDynamo can correctly and safely obtain the graph structure in 99% time, and the overhead is negligible.Because it does not require any modification to the original code.
TorchInductor: Faster codegen with define-by-run IR
More and more developers are writing high-performance custom kernels.Can speak Triton language.In addition, for the new compiler backend of PyTorch 2.0, the official also hopes to be able to use abstractions similar to PyTorch eager, and have sufficient general performance to support a wide range of functions in PyTorch.
TorchInductor uses Pythonic define-by-run loop level IR to automatically map PyTorch models to generated Triton code on the GPU and C++/OpenMP on the CPU.
The core loop level IR of TorchInductor contains only about 50 operators and is implemented in Python, which makes it highly hackable and extensible.
AOTAutograd: Reusing Autograd for ahead-of-time graphs
To accelerate training, PyTorch 2.0 must capture not only user-level code but also backpropagation. It would be even better if the proven PyTorch autograd system could be used.
AOTAutograd uses the PyTorch torch_dispatch extension mechanism to track the Autograd engine.Allows developers to capture backwards pass "ahead-of-time", allowing developers to use TorchInductor to accelerate forwards and backwards pass.
PrimTorch: Stable primitive operators
Writing a backend for PyTorch is not easy. Torch has 1200+ operators, and if you take into account the various overloads of each operator, the number is as high as 2000+.
 A Classification Overview of 2000+ PyTorch Operators
A Classification Overview of 2000+ PyTorch Operators
Therefore, writing backend or cross-cutting features becomes a time-consuming task. PrimTorch strives to define a smaller and more stable set of operators. PyTorch programs can be continuously downgraded to these operator sets. The official goal is to define two operator sets:
* Prim ops contains about 250 relatively low-level operators. Because they are low-level enough, these operators are more suitable for compilers. Developers need to fuse these operators to obtain good performance.
* ATen ops contains about 750 canonical operators suitable for direct output. These operators are suitable for backends that have been integrated at the ATen level, or for backends that have not been compiled to recover performance from the underlying operator set (such as Prim ops).
FAQ
1. How do I install PyTorch 2.0? What are the additional requirements?
Install the latest nightlies:
CUDA 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117CUDA 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu2. Is PyTorch 2.0 code backward compatible with 1.x?
Yes, 2.0 does not require modifying the PyTorch workflow, only one line of code model = torch.compile(model)The model will be optimized to use the 2.0 stack and run smoothly with other PyTorch code. This option is not mandatory and developers can still use previous versions.
3. Is PyTorch 2.0 enabled by default?
No, 2.0 must be explicitly enabled in your PyTorch code by optimizing the model with a single function call.
4. How to migrate PT1.X code to PT2.0?
Previous code does not require any migration. If you want to use the new compiled mode feature introduced in 2.0, you can first optimize the model with one line of code:model = torch.compile(model).
The speed improvement is mainly reflected in the training process. If the model runs faster than eager mode, it means it can be used for inference.
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)5. Which features are deprecated in PyTorch 2.0?
Currently PyTorch 2.0 is not stable and is still in nightlies. Support for Dynamic shapes in torch.compile is still in early stages and is not recommended until the stable 2.0 release in March 2023.
That said, even for static-shaped workloads, some bugs may appear when building in compiled mode. For parts of your code that are crashing, please disable compiled mode and file an issue.
Submit issue portal:https://github.com/pytorch/pytorch/issues
The above is a detailed introduction to PyTorch 2.0. We will complete the PyTorch 2.0 Get Started introduction in the future. Please continue to follow us!
You can also search Hyperai01 on WeChat and join the PyTorch technology development group discussion with Neural Star.








