Command Palette
Search for a command to run...
PyTorch's New Library TorchMultimodal Usage Instructions: Expand the Multimodal General Model FLAVA to 10 Billion Parameters

In the previous article, we introduced TorchMultimodal. Today, we will start from a specific case to demonstrate how to extend the multimodal basic model in the TorchMultimodal library with the support of Torch Distributed technology.
In recent years, large models have become a research field that has attracted much attention. Taking natural language processing as an example, language models have evolved from hundreds of millions of parameters (BERT) to hundreds of billions of parameters (GPT-3), showing a significant role in improving the performance of downstream tasks.
The industry has conducted extensive research on how to scale large-scale language models. A similar trend can be observed in the field of vision, where more and more developers are turning to transformer-based models (such as Vision Transformer and Masked Auto Encoders).
Obviously, due to the development of large-scale models, the research on single modality (such as text, image, video) has been continuously improved, and the framework has also quickly adapted to larger models.
At the same time, with the real-world applications of tasks such as image-text retrieval, visual question answering, visual dialogue, and text-to-image generation, multimodality has received increasing attention.
The next step is to train large-scale multimodal models. There are also some efforts in this area, such as OpenAI's CLIP, Google's Parti and Meta's CM3.
This article will show how to scale FLAVA to 10 billion parameters using PyTorch Distributed technology through a case study.
Additional reading:HyperAI: A look at the FX tools used by Meta: Optimizing PyTorch models with Graph Transformation
edit
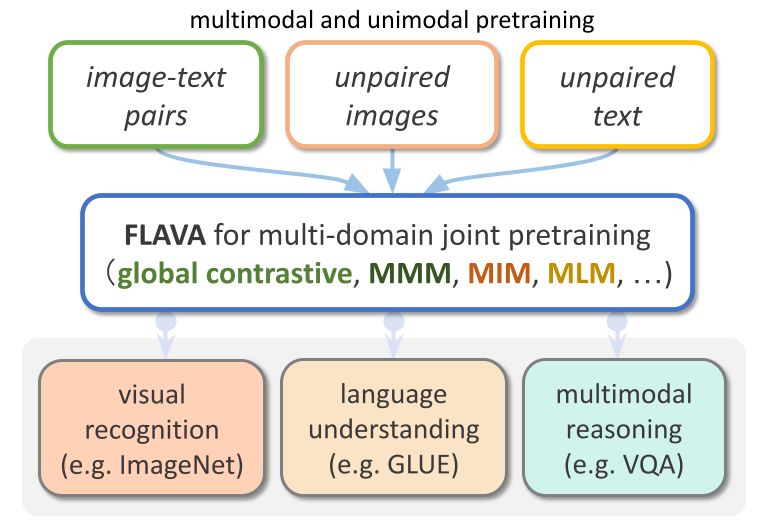
FLAVA is a vision and language based model available in TorchMultimodal
FLAVA has shown outstanding performance advantages in both single-modal and multi-modal benchmarks. This article will demonstrate how to extend FLAVA with relevant code examples.
See the code for details:
multimodal/examples/flava/native at main · facebookresearch/multimodal · GitHub
Expanding FLAVA Overview
FLAVA is a basic multimodal model consisting of transformer-based image and text encoders and a transformer-based multimodal fusion module.
FLAVA is pre-trained on both unimodal and multimodal data with different losses, including masked language, image, and multimodal model losses that require the model to reconstruct the original input from its context (self-supervised learning).
In addition, it uses an image text matching loss, including positive and negative examples of aligned image-text pairs, and a CLIP-style contrastive loss.
In addition to multimodal tasks (such as image-text retrieval), FLAVA also shows excellent performance on unimodal benchmarks (such as GLUE tasks in NLP and visual image classification).
edit
The original FLAVA model had about 350 million parameters and used the ViT-B16 configuration for both image and text encoders.
Reference:https://arxiv.org/pdf/2010.11929.pdf
The multimodal fusion transformer uses a single-modal encoder, but the number of layers is only 1/2 of the previous one. The PyTorch development team has been exploring increasing the size of the encoder to accommodate larger ViT variants.
Another aspect of scaling FLAVA is to increase the batch size. FLAVA makes use of the in-batch negative contrast loss, which is usually only available in large batch sizes.
Reference:https://openreview.net/pdfid=U2exBrf_SJh
In general, maximum training efficiency or throughput is achieved when operating close to the maximum possible batch size, which is determined by the amount of available GPU memory (see the Experiments section).
The following table demonstrates the output of different model configurations, where we experimentally determined the maximum batch size that can fit in memory for each configuration.

edit
Optimization Overview
PyTorch provides several native techniques to efficiently scale models. In the following sections, we will introduce three methods in detail and demonstrate how to apply these techniques to scale the FLAVA model to 10 billion parameters.
Distributed Data Parallelism
A common starting point for distributed training is data parallelism. Data parallelism replicates the model between GPUs and partitions the dataset. Different GPUs process different data partitions in parallel and synchronize their gradients (via all reduce) before updating the model weights.
The following figure shows the process of processing a data parallel (forward iteration, backward iteration, and weight update step):

edit
To achieve data parallelism, PyTorch provides a native API, DistributedDataParallel (DDP), which can be used as a module wrapper as shown below:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])Fully sharded data parallelism
The GPU memory usage of a training application can be roughly broken down into model input, intermediate activation storage (needed for gradient calculations), model parameters, gradients, and optimizer state.
When scaling a model, these elements are usually increased simultaneously. When a single GPU does not have enough memory, scaling a model using DDP can cause it to run out of memory because it replicates parameters, gradients, and optimizer state across all GPUs.
To reduce this duplication and save GPU memory, the model parameters, gradients, and optimizer states can be sharded to all GPUs, with each GPU managing only one shard. This approach is based on ZeRO-3 proposed by Microsoft.
A PyTorch-native implementation of this approach is available as the FullyShardedDataParallel (FSDP) API, which has been released as a beta feature in PyTorch 1.12.
During the forward and reverse iterations of the module, FSDP integrates the model parameters according to the calculation needs (using all-gather) and re-shards them after calculation. It uses scattering reduction sets to synchronize gradients to ensure that the gradients of the shards are globally averaged. The forward and reverse iterations of the model in FSDP are as follows:

edit
When using FSDP, you need to wrap the submodules of the model with an API to control when a specific submodule is sharded or not. FSDP provides an out-of-the-box auto-wrapping API, several wrapping policies, and the ability to write policies.
The following example demonstrates how to wrap a FLAVA model with FSDP. Specify the auto wrapping policy as: transformer_auto_wrap_policy . This will wrap a single transformer layer (TransformerEncoderLayer), image transformer (ImageTransformer), text encoder (BERTTextEncoder), and multimodal encoder (FLAVATransformerWithoutEmbeddings) into a single FSDP unit.
This uses a recursive encapsulation approach for efficient memory management. For example, after a single transformer layer is completed in the forward or backward iteration, parameters are deleted and memory is released, thus reducing peak memory usage.
FSDP also provides some configurable options to tune the performance of the application, such as the use of limit_all_gathers in this example. It can prevent all model parameters from being gathered prematurely and reduce the memory pressure of the application.
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)activation checkpointing
As mentioned above, intermediate activation storage, model parameters, gradients, and optimizer states affect GPU memory usage. FSDP can reduce the memory consumption caused by the latter three, but it cannot reduce the memory consumed by activation. The memory used by activation increases with the increase of batch size or number of hidden layers.
Activation checkpointing reduces memory usage by recomputing activations during backward iterations instead of keeping them in memory in the specific checkpointed module.
For example, by applying activation checkpointing to the 2.7 billion parameter model, the peak active memory after a forward iteration was reduced by a factor of 4.
PyTorch provides a wrapper-based activation checkpointing API. And checkpoint_wrapper allows users to encapsulate a single module through check, and apply_activation_checkpointing allows users to specify a strategy to encapsulate the module with checkpointing in the entire module.
These two APIs can be applied to most models because they do not require any modifications to the model definition code.
However, if you need finer-grained control over the checkpointed segments, such as checkpointing specific functionality within a module, you can use the torch.utils.checkpoint API, which requires modifying the model code.
The application of the activation checkpointing wrapper to a single FLAVA transformer layer (denoted by TransformerEncoderLayer) is shown below:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
As shown above, wrapping the FLAVA transformer layer with activation checkpointing and the overall model with FSDP allows scaling FLAVA to 10 billion parameters.
experiment
For the different optimization methods mentioned above, we will further experiment their impact on system performance.
Background:
- Using a single node with 8 A100 40 GB GPUs
- Run 1000 pre-training iterations
- PyTorch mixed precision training using bfloat16 data type (automatic mixed precision)
- Enable TensorFloat32 format to improve matmul performance on A100
- Define throughput as the average number of items processed per second (ignore the first 100 iterations when measuring throughput)
- Training convergence and its impact on downstream task indicators will serve as a new direction for future research
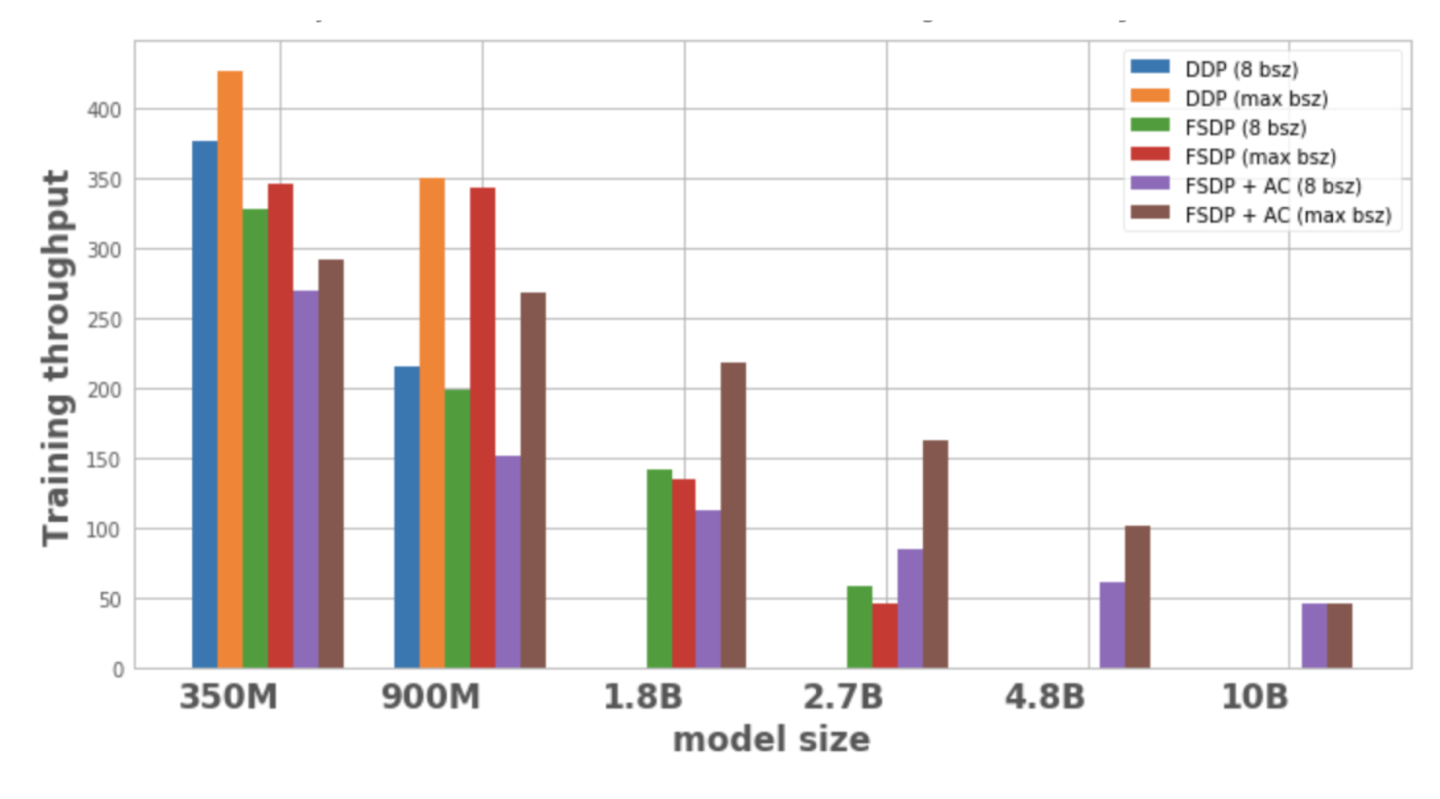
Figure 1 shows the throughput for each model configuration and optimization, with a local batch size of 8, the largest batch size possible on 1 node. The optimized model variant has no data points, indicating that the model cannot be trained on a single node.
edit
Figure 1: Training throughput under different configurations
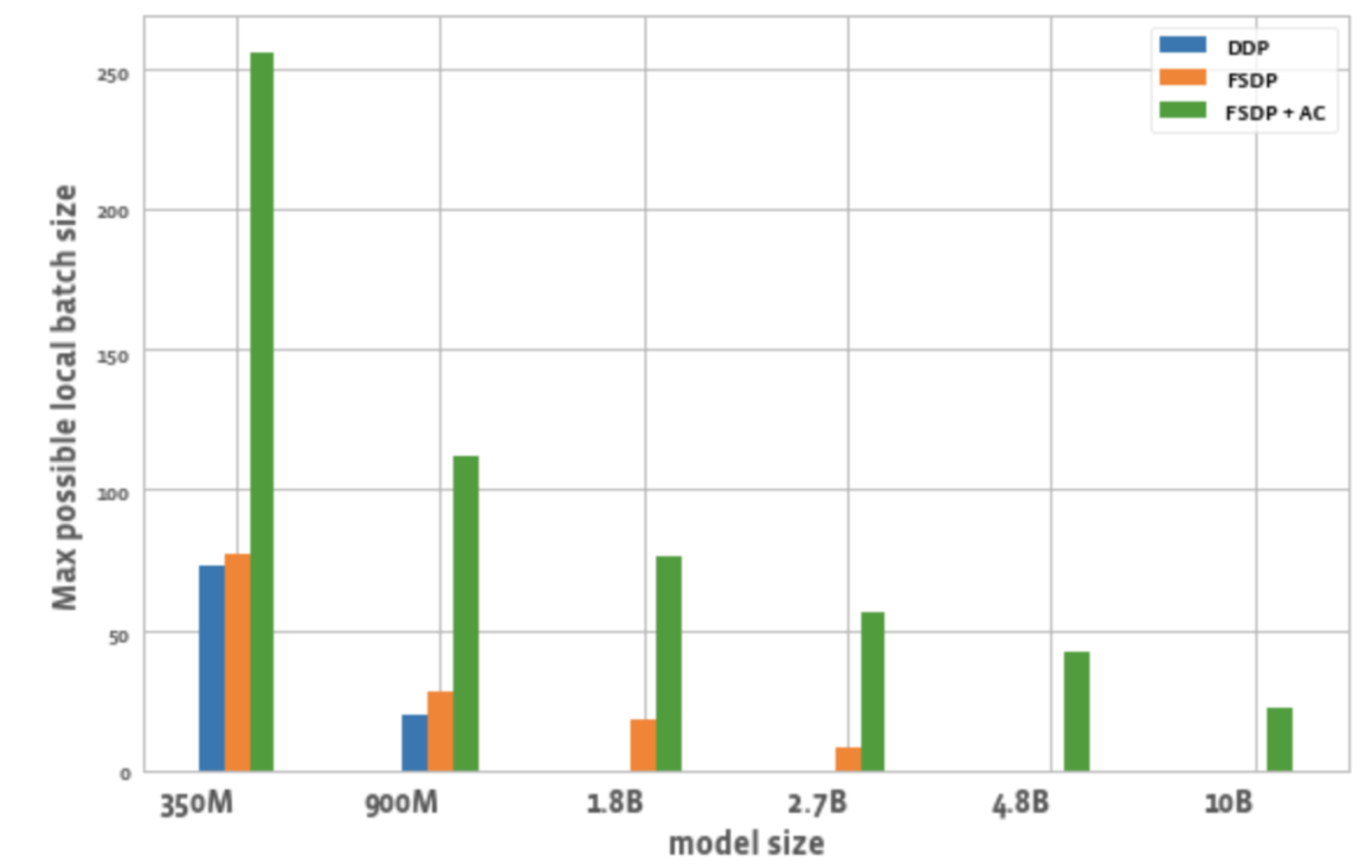
Figure 2 shows the maximum possible batch size for all GPUs in each optimization.
edit
Figure 2: Maximum possible local batch size under different configurations
From this we can observe:
1. Expand the model size:
DDP can only fit 350M and 900M models on a single node. Using FSDP saves memory, so it is possible to train models 3 times larger than DDP (i.e., 1.8B and 2.7B variants). Combining activation checkpoints (AC) with FSDP allows training larger models, about 10 times larger than DDP (i.e., 4.8B and 10B variants).
2. Throughput:
– For smaller models, when batch size is 8, DDP has slightly higher or equal throughput than FSDP, which can be explained by the additional communication required by FSDP. FSDP and AC combined have the lowest throughput. This is because AC reruns the checkpointed forward iteration pass during the backward iteration, sacrificing additional computation to save memory. However, for the 2.7B model, FSDP + AC actually has higher throughput compared to FSDP alone. This is because the 2.7B model with FSDP is close to the memory limit even at batch size 8, triggering CUDA malloc retry, resulting in slower training. AC helps reduce memory pressure resulting in no retry.
– For DDP and FSDP+AC, the throughput of the model increases with the batch size. The same is true for FSDP for smaller variants. However, for the 1.8B and 2.7B parameter models, the throughput decreases when increasing the batch size. One potential reason is that at memory limit, PyTorch’s CUDA memory management may have to retry cudaMalloc calls or run costly defragmentation to find free memory blocks to handle the workload’s memory needs, which may lead to slower training.
– For large models (1.8B, 2.7B, 4.8B) that can only be trained with FSDP, the highest throughput setting is to scale to the largest batch size with FSDP+AC. For 10B, it can be observed that the throughput for small and largest batch sizes is almost equal. This is because AC incurs increased computation and the largest batch size may incur expensive defragmentation operations due to running under CUDA memory limits. However, for these large models, the increase in batch size is enough to offset this overhead.
3. Batch size:
Compared to DDP, FSDP alone can achieve slightly higher batch sizes. For the 350M parameter model, using FSDP+AC can achieve 3 times higher batch sizes than DDP, and for the 900M parameter model, it can achieve 5.5 times higher batch sizes. Even at 10B, the maximum batch size is about 20, which is quite good. FSDP+AC can basically achieve larger global batch sizes with fewer GPUs, which is particularly effective for contrastive learning tasks.
in conclusion
As multimodal base models evolve, scaling model parameters and efficient training are becoming a focus area. The PyTorch ecosystem aims to accelerate training and scaling multimodal models by providing different tools.
In the future, PyTorch will add support for other types of models, such as multimodal generative models, and improve the automation of related technologies. Welcome everyone to continue to follow the PyTorch Developer Community Official Account, or you can scan the QR code and note "PyTorch" to join the PyTorch community.

PyTorch official blog, tutorials
Latest developments and best practices
Scan the QR code to join the discussion group








