Command Palette
Search for a command to run...
PyTorch Official Library "new", TorchMultimodal Helps Multimodal Artificial Intelligence
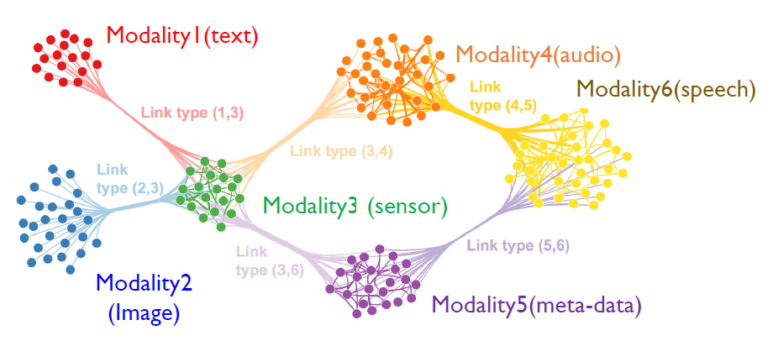
Multimodal artificial intelligence is a new AI paradigm that refers to multiple data types such as images, text, voice, and video, combined with multiple intelligent processing algorithms to achieve higher performance.
Recently, PyTorch officially released a domain library-TorchMultimodal.Large-scale training of multi-task, multi-modal models for SoTA.
The library provides:
- Composable building blocks (module, transforms, loss function) to accelerate model development
- SoTA model architecture extracted from published research, training and evaluation scripts (FLAVA, MDETR, Omnivore)
- Notebooks for testing these models
The TorchMultimodal library is still under active development, please pay attention to:
https://github.com/facebookresearch/multimodal#installation
TorchMultimodal Development Background
As technology advances, AI models that can understand multiple types of inputs (text, images, videos, and audio signals) and use this understanding to generate different forms of outputs (sentences, pictures, videos) are gaining more and more attention.
Recent work from FAIR (such as FLAVA, Omnivore, and data2vec) has shown thatMultimodal models for understanding compare favorably to unimodal models and in some cases are setting new SOTA standards.
Generative models like Make-a-video and Make-a-scene are redefining the capabilities of modern artificial intelligence systems.
To promote the development of multimodal AI in the PyTorch ecosystem, The TorchMultimodal library came into being, and its solution is:
- Provides composable building blocks, Using these building blocks, researchers can accelerate model development and experimentation in their own workflows. The modular design also reduces the difficulty of migrating to new modalities of data.
- Provides end-to-end examples for training and evaluating state-of-the-art models from research. These examples use some advanced features such as integrated FSDP and activation checkpointing for scaling model and batch sizes.
First look at TorchMultimodal
TorchMultimodal is a PyTorch domain library.For large-scale training of multi-task multimodal models. It provides:
1. Building Block
Modules are collections of composable building blocks such as models, ensemble layers, loss functions, datasets, and utilities, for example:
- Contrastive Loss with Temperature: Functions commonly used in training models such as CLIP and FLAVA. Also included are variables such as ImageTextContrastiveLoss used in models such as ALBEF.
- Codebook layer: Compressing high-dimensional data through nearest neighbor search in vector space is also an important component of VQVAE.
- Shifted-window Attention: Window is based on multi-head self attention and is an important component of encoders such as Swin 3D Transformer.
- CLIP components: Released by OpenAI, it is a very effective model for learning text and image representations.
- Multimodal GPT: When combined with a generator, OpenAI’s GPT architecture can be extended to an abstraction more suitable for multimodal generation.
- MultiHeadAttention: A key component of attention-based models that supports auto-regressive and decoding.
2. Example
A set of examples shows how to combine the building blocks with PyTorch components and public infrastructure (Lightning, TorchMetrics) to replicate SOTA models published in the literature. Five examples are currently provided, including:
- FLAVA: Official code for CVPR accepted papers, including a tutorial on FLAVA fine-tuning.
View the paper:https://arxiv.org/abs/2112.04482
- MDETR: Collaborating with the NYU authors to provide an example that alleviates interoperability pain points in the PyTorch ecosystem, including a notebook for phrase grounding and visual question answering using MDETR.
View the paper:https://arxiv.org/abs/2104.12763
- Omnivore: First example of a model in TorchMultimodal for processing video and 3D data, including notebooks for exploring the model.
View the paper:https://arxiv.org/abs/2204.08058
- MUGEN: Foundational work on auto-regressive generation and retrieval, including a demo for text-video generation and retrieval using OpenAI coinrun’s rich large-scale synthetic dataset.
View the paper:https://arxiv.org/abs/2204.08058
- ALBEF: Model code, including a notebook for using the model to solve a visual question answering problem.
View the paper:https://arxiv.org/abs/2107.07651
The following code shows the usage of several TorchMultimodal components related to CLIP:
# instantiate clip transform
clip_transform = CLIPTransform()
# pass the transform to your dataset. Here we use coco captions
dataset = CocoCaptions(root= ..., annFile=..., transforms=clip_transform)
dataloader = DataLoader(dataset, batch_size=16)
# instantiate model. Here we use clip with vit-L as the image encoder
model= clip_vit_l14()
# define loss and other things needed for training
clip_loss = ContrastiveLossWithTemperature()
optim = torch.optim.AdamW(model.parameters(), lr = 1e-5)
epochs = 1
# write your train loop
for _ in range(epochs):
for batch_idx, batch in enumerate(dataloader):
image, text = batch
image_embeddings, text_embeddings = model(image, text)
loss = contrastive_loss_with_temperature(image_embeddings, text_embeddings)
loss.backward()
optimizer.step()Install TorchMultimodal
Python ≥ 3.7, with or without CUDA support installed.
The following code takes the installation of conda as an example
Prerequisites
1. Install the conda environment
conda create -n torch-multimodal python=\<python_version\>
conda activate torch-multimodal2. Install PyTorch, torchvision and torchtext
See the PyTorch documentation:
https://pytorch.org/get-started/locally/
# Use the current CUDA version as seen [here](https://pytorch.org/get-started/locally/)
# Select the nightly Pytorch build, Linux as the OS, and conda. Pick the most recent CUDA version.
conda install pytorch torchvision torchtext pytorch-cuda=\<cuda_version\> -c pytorch-nightly -c nvidia
# For CPU-only install
conda install pytorch torchvision torchtext cpuonly -c pytorch-nightlyInstall from binary file
On Linux, Nightly binaries for Python 3.7, 3.8, and 3.9 are available via pip wheels. Currently only Linux platforms are supported via PyPI.
python -m pip install torchmultimodal-nightlySource installation
Developers can also build and run the examples from source:
git clone --recursive https://github.com/facebookresearch/multimodal.git multimodal
cd multimodal
pip install -e .The above is a brief introduction to TorchMultimodal. In addition to the code,PyTorch officially released a basic tutorial on fine-tuning multimodal models. And a blog on how to scale these models using PyTorch Distributed PyTorch (FSDP and activation checkpointing) techniques.
We will translate this blog into Chinese later. Welcome to continue to follow the PyTorch Developer Community Official Account!
-- over--








