Command Palette
Search for a command to run...
Typos Correction | Deploy 1 Chinese Text Spelling Correction Model
Content at a glance: One of the types of Chinese text errors is spelling errors. This article is a model deployment tutorial for implementing Chinese text error correction using the BART pre-training method.
Keywords: BART, Chinese spelling correction, NLP
This article was first published on WeChat official account: HyperAI
3 major obstacles to Chinese text errors: spelling, grammar, and semantics
Chinese text error correction is an important branch in the current field of natural language processing, which aims to detect and correct Chinese text errors.Common Chinese text errors include spelling errors, grammatical errors, and semantic errors.
1. Spelling Errors:
Refers to the incorrect use of words or phrases due to input methods, speech-to-text software, etc., mainly manifested in the incorrect use of homophones, similar characters, mixed sounds, etc., such as "天气晴郎 – 天气晴" and "时侯 – 当时".
2. Syntax Error:
Refers to missing, redundant, disordered or improperly matched words due to input methods, careless handwriting, disordered OCR recognition, etc., such as "Humility makes people progress - Humility makes people progress."
3. Semantic Error:
Knowledge and logical errors caused by lack of understanding of certain knowledge or lack of language organization skills, such as "there are 3 quarters in a year - there are 4 quarters in a year".
In this article, we will use the most common spelling errors as examples.Demonstrate how to deploy a Chinese text error correction model using the BART model.
To run the tutorial directly, please visit:
BART: A SOTA model that draws on the strengths of many
BART stands for Bidirectional and Auto-Regressive Transformers.It is a denoising autoencoder designed for pre-training seq2seq models. Suitable for natural language generation, translation and understanding tasks, proposed by Meta (formerly Facebook) in 2019.
For more details, please visit:
https://arxiv.org/pdf/1910.13461.pdf
The BART model draws on the advantages of BERT and GPT and uses the standard Transformer structure as its basis:
- Decoder module reference GPT: Replace the ReLU activation function with the GeLU activation function
- The encoder module is different from BERT: The feedforward neural network module was abandoned and the model parameters were simplified.
- The codec connection part refers to Transformer: Each layer of the decoder must perform cross-attention calculations on the output information of the last layer of the encoder (that is, the encoder-decoder attention mechanism)

In this tutorial,We use the nlp_bart_text-error-correction_chinese model for model deployment.
For more information, visit:
Tutorial details: Creating an online text correction demo
Environment Preparation
Execute the following command in the Jupyter terminal to install dependencies:
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install fairseqModel Download
Execute the following command in the terminal to download the model:
git clone http://www.modelscope.cn/damo/nlp_bart_text-error-correction_chinese.gitIt takes a long time to download the model. The model has been downloaded in this container and can be used directly. nlp_bart_text-error-correction_chinese directory.
Quick Use
Model deployment
Serving Service Writing
write predictor.py document:
- Import dependent libraries: In addition to the libraries used in the business, you need to additionally depend on openbayes-serving.
import openbayes_serving as serv
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks- Predictor class: No need to inherit other classes, at least provide init And predict interfaces.
- exist
__init__Specify the model path in the load model - exist
predictPerform inference and return the result
class Predictor:
def __init__(self):
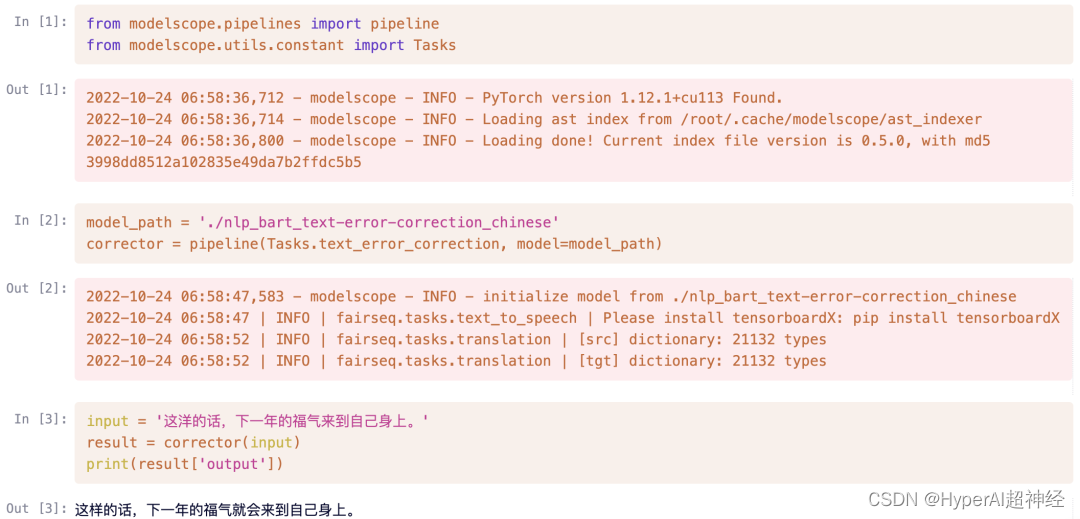
self.model_path = './nlp_bart_text-error-correction_chinese'
self.corrector = pipeline(Tasks.text_error_correction, model=self.model_path)
def predict(self, json):
text = json["input"].lower()
result = self.corrector(text)
return result- Run: Start the service
if __name__ == '__main__':
serv.run(Predictor)test
Execute in terminal python predictor.pyAfter successfully starting the service, execute the following code in this Notebook for testing.
Note: When testing in a container, if the flask version is greater than 2.1, duplicate registration errors may occur. You can run it by lowering the version.
import requests
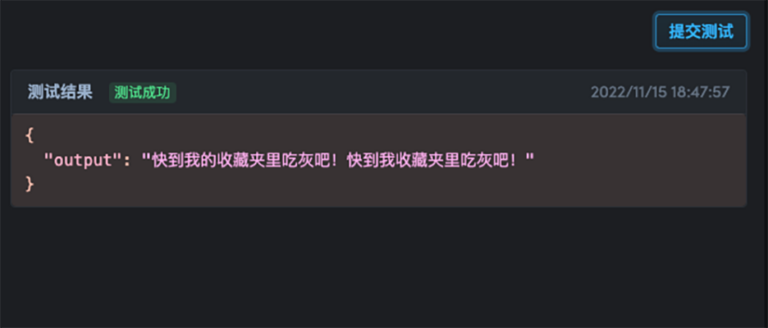
text = {"input": "这洋的话,下一年的福气来到自己身上。"}
result = requests.post('http://localhost:8080', json=text)
result.json()
{'output': '这样的话,下一年的福气就会来到自己身上。'}In addition to accessing the address locally http://localhost:8080,You can also test it via an externally accessible URL prompted in the terminal.

Note: For different OpenBayes computing power containers, the externally accessible URL is different. Directly using the link in this tutorial is invalid. You need to replace it with the link prompted in the terminal..
result = requests.post('https://openbayes.com/jobs-auxiliary/open-tutorials/t23g93jjm95d', json=text)
result.json()deploy
After the test is successful, stop the computing container and wait for the data synchronization to complete.
In "Computing Container - Model Deployment", click "Create New Deployment", select the same image as used in development, bind this computing container, and click "Deploy".You can perform online testing.
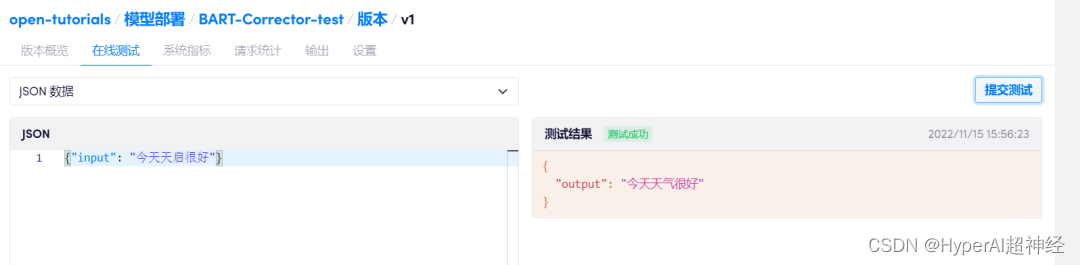
For more information about model deployment, please refer to:
At this point, a Chinese text error correction model that supports online testing has been trained and deployed!
To view and run the complete tutorial, visit the following link:
Come and try out your Chinese error correction model!
-- over--
Reference Links:
[1] https://www.51cto.com/article/715865.html
[2] https://arxiv.org/pdf/1910.1346








