")
Although Google Translate has been released for nearly 15 years, it still stubbornly believes that Android phones are very fast.
The most recent major update to GT was the introduction of a neural machine translation (GNMT) system in 2016, which includes 8 encoders and 8 decoders for translation into 9 languages.
They not only separate the sentences but also the words, which is how they handle a rare word. NMT has no reference when the word is not in the dictionary. For example, translating a letter group "Vas3k", in this case, GMNT tries to split the word into chunks and recover their translation.
But it still cannot explain why "卡顿" was translated into "very fast". Moreover, after this translation became a widely circulated joke among domestic engineers in recent days, Google's proud crowdsourcing error correction still failed to successfully intervene in this erroneous translation.
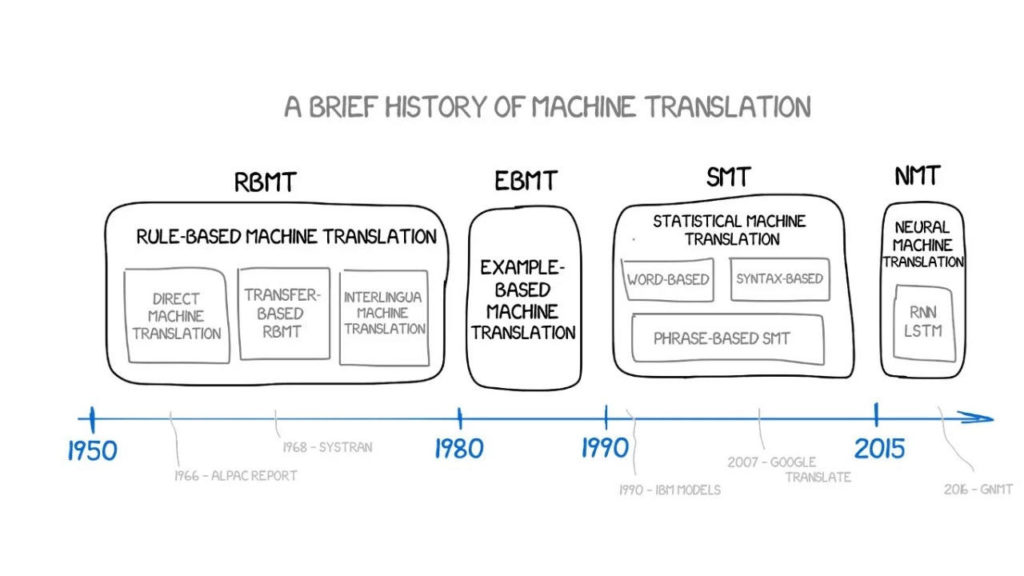
It is because of this little joke that we want to start studying machine translation. This article will review the development of machine translation over the past sixty years, including mainstream methods such as rule-based machine translation (RBMT), example-based machine translation (EBMT), statistical machine translation (SMT), neural machine translation (NMT), and the leading algorithms of manufacturers such as Google and Yandex.
You are reading the first half of this series of articles, "Machine Translation 1933-1984".
The first four decades of slow progress
Machine translation first appeared in 1933, during the Cold War.
At that time, Soviet scientist Peter Troyanskii proposed at the Soviet Academy of Sciences to "develop a machine that can be used for language translation and print text." The structure of this machine is very simple - there are only four cards in different languages, a typewriter, and an old-school movie camera.
The operator took the first word from the text, found the corresponding card, took a photo of it, and typed its morphological features (noun, plural, genitive, etc.) on a typewriter. The typewriter translated according to some of these features and presented it on magnetic tape and camera film.
")
Even though it could do simple translations, it was still considered a "useless" invention at the time. Unfortunately, Troyanskii spent 20 years on this invention and eventually died of angina pectoris, and the invention came to an end. Before the Soviet scientists discovered this machine in 1965, almost no one in the world knew about its existence.
On January 7, 1954, at the beginning of the Cold War, the first true translation machine in history, the IBM 701, appeared at the IBM headquarters in New York. It successfully translated 60 Russian sentences into English. This was the famous Georgetown-IBM experiment.
")
But the perfect gimmick is meant to cover up a small detail. No one mentions that the examples of translations are carefully selected and tested to exclude any ambiguity. For everyday use, this system is no better than a quick translation manual.
Even so, the foundations of modern natural language processing were created by scientists, including in the United States, through continuous experimentation, research and development. All of today's search engines, spam filters, and personal assistants are based on this.
Rule-Based Machine Translation (RBMT)
The idea of rule-based machine translation first emerged in the 1970s, when scientists carefully observed the work of translators and tried to force computers to repeat those actions. These systems include:
-
Bilingual dictionary (RU -> EN)
-
Each language has a set of linguistic rules (e.g. nouns ending with certain suffixes, such as -heit, -keit, -ung, etc.), which is the root part of speech.
If necessary, the system can also add some tricks, such as name lists, spelling correctors and transliterators.
")
PROMPT and Systran are the most famous examples of RBMT systems, even though they have some nuances and subspecies.
-
Direct machine translation
This is the most direct type of machine translation. It translates the words in the text one by one and slightly corrects their morphology and coordinates the grammar to make the whole paragraph look more accurately translated. As for these modification rules, they are all set by professional linguists.
However, these translation rules sometimes fail and produce poor translations, and modern systems do not use such rules at all, but they are very popular with modern linguists.
")
-
Machine translation based on grammatical structure
Compared to literal translation, we first determine the grammatical structure of the sentence, just like what we were taught by teachers in school. Then we analyze the whole structure instead of individual words, which in theory helps to get a fairly good word order conversion in the translation.
But in practice, this approach still has limitations. On the one hand, it simplifies general grammatical rules, but on the other hand, its translation becomes more complicated due to the increase in word structures compared to single words.
")
-
Machine Translation of Interlanguage
In this approach, the source text is converted into an intermediate representation and unified in all world languages (interlingua). It is the same as what Descartes dreamed of: a metalanguage that follows universal rules and turns translation into a simple "back and forth" task. This can make interlingua able to translate any target language.
Because of this conversion, Interlingua is often confused with transfer-based metalanguage systems. The difference is that the linguistic rules are specific to each language and language, not to language pairs. This means that we can add a third language to an interlingua system and convert between the three, which is difficult to achieve in a translation system based on grammatical structure.
")
It looks perfect, but it is not so in real life. Creating such an interlanguage is extremely difficult - many scientists have spent their whole lives working on it. Although they did not achieve great success, thanks to them we now have representations at the morphological, syntactic and even semantic levels.
")
However, RBMT also has advantages, such as its morphological accuracy (it does not confuse words), the reproducibility of its results (all translators get the same results), and its ability to be tuned to subject areas (for example, to teach terminology to economists or engineers).
Even if someone succeeds in creating an ideal RBMT, and linguists continue to enhance it with all the spelling rules, there will always be exceptions it can't handle: irregular verbs in English, separable prefixes in German, suffixes in Russian, and people expressing themselves in different ways.
The cost of correcting these subtle differences is enormous. Don't forget homonyms, that is, the same word can have different meanings in different contexts, which leads to many possible translations of the same sentence. For example, when I say "I saw a man using a telescope on the mountain", how many meanings do you think this contains?
Languages do not develop based on a fixed set of rules - this is a fact that linguists like. During the 40 years of the Cold War, although machine translation was developing, no clear solution was found to improve the accuracy and convenience of translation.
Therefore, RBMT has been dead for a long time.
Example-Based Machine Translation (EBMT)
In the 1980s, in order to gain a firm foothold in the upcoming globalization, Japan, where few people knew English, urgently needed machine translation. With strong support from national policies, Japan became the country with the greatest interest in machine translation at that time.
Since rule-based machine translation (RBMT) is difficult to translate from English to Japanese because the translation process requires almost all words to be rearranged and also involves new words, this forces the Japanese to seek new translation ideas.
")
So, in 1984, Makoto Nagao of Kyoto University proposed the idea of replacing repeated translations with ready-made phrases, which is called example-based machine translation (EBMT). The more examples input, the faster and more accurate the translation.
The emergence of the EBMT idea was like a spark that ignited scientists' innovative inspiration, which was of great significance to the development of machine translation, although it was not a revolutionary initiative. But five years later, the revolutionary statistical translation would emerge based on it.
Next article preview
-
The 1990s-2000s machine translation era dominated by statistical machine translation (SMT);
-
Neural machine translation (NMT) finally made its debut in 2015;
-
Advanced gameplay of Google and Yandex;
")
")
Historical articles (click on the image to read)
")
"Why is October 24th Programmers' Day?"
")
"This paper is poisonous!"
")
"How to explain artificial intelligence to relatives and friends?"
")
")








