Previous episode review
-
Sixty years of slow development of machine translation
-
Rule-Based Machine Translation (RBMT)
-
Example-Based Machine Translation (EBMT)
")
Click on the image to read the first part of this article
Statistical Machine Translation (SMT)
In early 1990, at IBM Research Center, a machine translation system was demonstrated for the first time, which knew nothing about rules and linguistics. It analyzed the text in the figure below in two languages and tried to understand the patterns.
")
The idea is simple and beautiful. In both languages, an identical sentence was broken into several words and then reassembled. This operation was repeated about 500 million times, so that, for example, the word "Das Haus" was translated into "house" vs "building" vs "construction" and so on.
If the source word (for example, "Das Haus") is translated as "house" most of the time, the machine will assume this meaning. Note that we did not set any rules or use any dictionaries - all conclusions were made by the machine, guided by data and logic. When translating, the machine seemed to say, "If people translate it this way, I will do the same." Thus, statistical machine translation was born.
")
The advantage is that it is more efficient, more accurate, and does not require linguists. The more text we use, the better the translation we get.
")
(Statistical translation from Google: it not only shows the usage probability of this meaning, but also provides statistics on other meanings)
One more question:
How does a machine connect the words “Das Haus” and “building” — and how do we know these are correct translations?
The answer is we don’t know.
At first, the machine assumes that the word "Das Haus" has the same association with any word in the translated sentence, and then when "Das Haus" appears in other sentences, the association with "house" increases. This is the "word alignment algorithm", which is a typical task of machine learning at the university level.
The machine needs millions of sentences in two languages to collect relevant statistical information about each word. How to obtain this language information? We decided to use the summaries of the meetings of the European Parliament and the United Nations Security Council - these summaries are presented in the languages of all member states, which can save a lot of time for material collection.
-
Word-based SMT
In the beginning, the first statistical translation systems broke sentences into words. Because this approach was straightforward and logical, IBM’s first statistical translation model was called “Model 1.”
Model 1: Basket of Words
")
Model 1 uses the classic approach of splitting into words and counting statistics, but does not take into account word order, and the only trick is to translate one word into multiple words. For example, “Der Staubsauger” can become “vacuum cleaner”, but this does not mean that it will become “vacuum cleaner”.
Model 2: Considering the order of words in a sentence
")
The lack of order in which words are placed is the main limitation of Model 1, which is very important during translation. Model 2 solves this problem by memorizing the common positions of words in the output sentence and reshuffling them in the intermediate steps to make the translation more natural.
So, have things gotten better? No.
Model 3: Adding new words
")
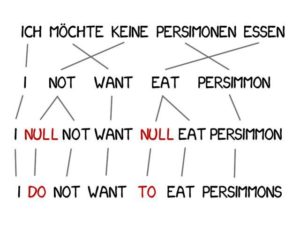
In translation, it is often necessary to add new words to improve the semantics, such as using "do" in German when negation is required in English.The German phrase ““Ich will keine Persimonen”” translates into English as “I do not want Persimmons”.
To solve this problem, Model 3 adds two more steps based on the previous ones:
-
If the machine considers that a new word needs to be added, the NULL token is inserted;
-
Choose the correct grammar or word pair for each word alignment.
Model 4: Word Alignment
Model 2 takes word alignment into account, but knows nothing about reordering. For example, adjectives often swap places with nouns, and no matter how the order is remembered, it is difficult to get a subtle translation without adding grammatical factors. Therefore, Model 4 takes this "relative order" into account - if two words always swap places, the model will know.
Model 5: Fixing Errors
Model 5 gained more learning parameters and solved the problem of word position conflicts. Despite their revolutionary significance, text-based systems still cannot handle homonymy, where every word is translated in a single way.
However, these systems are no longer used as they have been replaced by more advanced phrase-based translations.
-
Phrase-based SMT
The method is based on all the principles of word-based translation: statistics, reordering and lexical techniques. It segments the text not only into words, but also into phrases, which are, to be precise, consecutive sequences of multiple words.
As a result, the machine learned to translate stable word combinations, which significantly improved accuracy.
")
The point is that these phrases are not always simple syntactic structures, and if one is aware of the interference of linguistics and sentence structure, the quality of the translation will drop significantly. Frederick Jelinek, a pioneer in computational linguistics, once joked: "Every time I attack a linguist, the performance of the speech recognizer improves."
In addition to improved accuracy, phrase-based translation provides more options for bilingual texts. For word-based translation, an exact match of the source is crucial, so it is difficult to contribute value on literary or free translations.
Phrase-based translation does not have this problem, and in order to improve the level of machine translation, researchers have even begun to parse news websites in different languages.
")
Almost everyone has been using this method since 2006. Google Translate, Yandex, Bing and other well-known online translation systems were all phrase-based before 2016. Therefore, the results of these translation systems are either perfect or meaningless, yes, this is the characteristic of phrase translation.
This old rule-based method always produces biased results. Google translated "three hundred" into "300" without hesitation, but in fact "three hundred" also means "300 years". This is a common limitation of statistical translation machines.
Before 2016, almost all studies considered phrase-based translation to be the most advanced, and even equated "statistical machine translation" and "phrase-based translation". However, people realized that Google would revolutionize the entire machine translation.
-
Syntax-based SMT
This method should also be mentioned briefly. Many years before neural networks came along, grammar-based translation was considered the "future", but the idea did not take off.
Its supporters believe that it can be merged with rule-based methods. Sentences can be accurately parsed grammatically - determining the subject, predicate and other parts of the sentence, and then building a sentence tree. By using it, machines can learn to convert syntactic units between languages and translate by word or phrase. This can completely solve the problem of "translation error".
")
The idea is beautiful, but the reality is very bleak. The grammatical analysis works very poorly, even though its grammar library problem has been solved before (because we already have many ready-made language libraries).
Neural Machine Translation (NMT)
In 2014, an interesting paper on neural network machine translation appeared, but it did not attract widespread attention. Only Google began to dig deeper into this field. Two years later, in November 2016, Google made a high-profile announcement: the rules of the game for machine translation have officially been changed by us.
The idea is similar to the feature in Prisma that mimics the style of famous artists. In Prisma, a neural network is taught to recognize the style of an artist's work, and the resulting stylized image can, for example, make a photo look like a Van Gogh. It's an illusion created by the network, but we think it's beautiful.
")
What if we could transfer a style to a photograph, what if we tried to impose another language on the source text? The text would be the exact “style of the artist” and we would try to transfer it while preserving the essence of the image (in other words, the essence of the text).
Imagine what would happen if this kind of neural network was applied to a translation system?
Now, let's say the source text is a collection of certain features, which means you need to encode it and then have another neural network decode it back into text in a language that only the decoder knows. It doesn't know where these features came from, but it can say it in Spanish.
This will be a very interesting process, one neural network can only encode sentences into a specific set of features, and the other can only decode them back into text. Neither of them knows who the other is, they each only know their own language, and they are strangers to each other but can coordinate.
")
However, there is also a problem here, that is, how to find and define these characteristics. When we talk about dogs, its characteristics are obvious, but what about text? You know, 30 years ago, scientists tried to create a universal language code, but ultimately failed.
However, we now have deep learning, which can solve this problem very well, because it exists for this purpose. The main difference between deep learning and classical neural networks is that it precisely focuses on the ability to search for these specific features, regardless of their nature. If the neural network is large enough and has thousands of video cards at its disposal, it can generalize these features in the text.
In theory, we could pass the features obtained from neural networks to linguists, so that they could open up completely new perspectives for themselves.
A question is, what type of neural network can be applied to text encoding and decoding?
We know that Convolutional Neural Networks (CNNs) currently only work for images based on independent patches of pixels, but in text there are no independent patches and each word depends on the context around it, just like language and music. Recurrent Neural Networks (RNNs) will provide a best choice because they remember all previous results - in our case, previous words.
And recurrent neural networks are already being used today, such as the iPhone’s RNN-Siri voice recognition (it parses the order of sounds, the next one depends on the previous one), keyboard prompts (remember the previous one, guess the next one), music generation, and even chatbots.
")
In two years, the neural network completely surpassed the translation of the previous 20 years. It reduced word order errors by 50%, vocabulary errors by 17%, and grammatical errors by 19%. The neural network even learned to deal with problems like homonyms in different languages.
It is worth noting that neural networks can achieve true direct translation, completely discarding dictionaries. When translating between two non-English languages, there is no need to use English as an intermediate language. Previously, if you want to translate Russian into German, you need to translate Russian into English first, and then translate English into German, which will increase the error rate of repeated translation.
")
Google Translate (since 2016)
In 2016, they developed a system called Google Neural Machine Translation (GNMT) for translation in nine languages. It includes eight encoders and eight decoders, as well as a network connection that can be used for online translation.
")
They not only separate the sentences but also the words, which is how they handle a rare word. NMT has no reference when the word is not in the dictionary. For example, translating a letter group "Vas3k", in this case, GMNT tries to split the word into word chunks and recover their translation.
Tip: Google Translate used for website translations in the browser still uses the old phrase-based algorithm. Somehow Google didn't upgrade it and the differences are noticeable when compared to the online version.
However, the Google Translate currently used in the browser for website translation still uses a phrase-based algorithm. Somehow, Google has not upgraded it in this regard, but this also allows us to see the difference from the traditional translation mode.
Google uses a crowdsourcing mechanism on the Internet, where people can choose the version they think is most correct. If many users like it, Google will continue to translate the phrase in this way and mark it with a special badge. This is very useful for short, everyday sentences such as "Let's go to the movies" or "I'm waiting for you."
Yandex Translation (since 2017)
Yandex launched its neural translation system in 2017, which uses the CatBoost algorithm that combines neural networks with statistical methods.
This method can effectively make up for the shortcomings of neural network translation - translation distortion is prone to occur for phrases that do not appear frequently. In this case, a simple statistical translation can quickly and easily find the correct word.
")
The future of machine translation?
People are still excited about the concept of "Babel fish" - instant voice translation. Google has taken a step towards it with its Pixel Buds, but in reality, it's definitely not perfect because you need to let it know when to start translating and when to shut up and listen. Even Siri can't do this.
There is another difficulty to be explored: all learning is limited to the corpus of machine learning. Even if a more complex neural network can be designed, it can only learn from the provided text. Human translators can supplement relevant corpora by reading books or articles to ensure more accurate translation results. This is where machine translation lags far behind human translation.
However, since human translators can do this, in theory, neural networks can also do this. And it seems that some people have already tried to use neural networks to achieve this function. That is, through a language it knows, reading in another language to gain experience, and then feeding it back to its own translation system for backup, let us wait and see.
Additional reading
")
《Statistical Machine Translation》
By Philipp Koehn
Follow the public account and reply "Statistical Machine Translation" to download the PDF version
")
")








