Command Palette
Search for a command to run...
Use the super-resolution Leader Algorithm ESRGAN to Train the Image Enhancement Model

Super-resolution technology is often required to convert images or videos from low resolution to high resolution and restore or supplement lost details (i.e. high-frequency information).
Depending on the number of low-resolution images used,Super-resolution technology can be divided into single image super-resolution (SISR) and multiple image super-resolution (MISR).
SISR uses a low-resolution image.To achieve the effect of increasing the image size or increasing the pixels,Thus a high-resolution image is obtained.
MISR uses multiple low-resolution images of the same scene.Get different details and synthesize one or more high-resolution images. The output of MISR can be either a single image or a series of images (i.e., a video).
Three magic weapons for super-resolution: interpolation, reconstruction, and learning
Image super-resolution methods can be divided into three categories: interpolation-based, reconstruction-based and learning-based methods.
Method 1: Based onInterpolation
Interpolation is the process of magnifying the image to find the gaps.Fill the corresponding pixel values,This can restore the image content and improve the image resolution.
Commonly used interpolation methods include: nearest neighbor interpolation, linear interpolation, bilinear interpolation and bicubic interpolation.
Nearest neighbor interpolation
The nearest neighbor interpolation method is the simplest and most crude to implement, and has the smallest amount of calculation.Just copy the pixel value of the nearest pixel to fill it.However, the most notable feature of copying the pixels next to it is that the effect is poor and the blocking effect is obvious.

Linear interpolation
Linear Interpolation is to interpolate in one direction.For one-dimensional data only, the equation is a univariate polynomial, that is, there is only one variable.

Bilinear interpolation
Bilinear Interpolation is similar to the linear interpolation method for one-dimensional data.The difference is that bilinear interpolation is extended to two-dimensional images and needs to be interpolated in both the X and Y directions.
The bilinear interpolation operation process is slightly more complicated than the nearest neighbor interpolation, but the effect is smoother, which also causes some details of the interpolated image to look blurred.
Bicubic interpolation
Bicubic Interpolation Similarly,Interpolation of functions of three variables.Bicubic interpolation is more complex, and the image edges it outputs are smoother and more accurate than bilinear interpolation, but it is also the slowest.
Method 2: Reconstruction-based
The super-resolution restoration method based on reconstruction is to use multiple low-resolution images of the same scene.Sub-pixel precision alignment in space, The process of obtaining the motion offset between high-resolution and low-resolution images and constructing the spatial motion parameters in the observation model to obtain a high-resolution image.
The core idea of reconstruction-based super-resolution methods is toIt is to use temporal bandwidth (obtaining a multi-frame image sequence of the same scene) in exchange for spatial resolution.Realize the conversion of temporal resolution to spatial resolution.
Currently, super-resolution reconstruction methods can be divided into two categories: frequency domain methods and spatial domain methods.
The frequency domain method solves the image interpolation problem in the frequency domain. Its observation model is based on the shift characteristics of Fourier transform.It has simple theory, low computational complexity, and is easy to implement parallel processing.
The linear spatial observation model of the spatial method involves global and local motion, optical blur, intra-frame motion blur, etc.Its typical methods include non-uniform interpolation method, iterative back projection method, maximum a posteriori probability method (the most commonly used method in practical applications and scientific research), and convex set projection method.
Method 3: Learning-based
The learning-based super-resolution method refers to directly learning the end-to-end mapping function from low-resolution images to high-resolution images through a neural network.Use the prior knowledge learned by the model to obtain high-frequency details of the image.Thereby achieving better image restoration effect.
The algorithm steps based on shallow learning include:Feature extraction -> learning -> reconstruction. Mainstream methods include: example-based method, neighborhood embedding method, support vector regression method, sparse representation method, etc.
Among them, the example-based method is the first single-image super-resolution algorithm based on learning.First proposed by Freeman, it uses machine learning training data sets to learn the relationship between low resolution and high resolution, and then achieve super-resolution reconstruction.
The algorithm steps based on deep learning include:Feature extraction–> nonlinear mapping–> image reconstruction
Image super-resolution reconstruction methods based on deep learning include SRCNN, FSRCNN, ESPCN, VDSR, SRGAN, ESRGAN, etc.Here we focus on the three algorithms: SRCNN, SRGAN, and ESRGAN.
SRCNN
SRCNN is the pioneering work that uses deep learning for super-resolution reconstruction. Its network structure is very simple.It only includes 3 convolutional layers.

The implementation method is very refined: Input a low-resolution image, use the bicubic interpolation method to enlarge the image to the target size, then use a three-layer convolutional neural network to fit the nonlinear mapping between the low-resolution image and the high-resolution image, and finally output the reconstructed high-resolution image.
advantage:The network structure is simple (only 3 convolutional layers are used); the framework is flexible in selecting parameters and supports customization.
shortcoming: Only training is performed on a single scale factor, and once the amount of data changes, the model must be retrained; only one convolutional layer is used for feature extraction, which is relatively limited and the details are not fully presented; when the image is magnified by more than 4 times, the result is too smooth and unrealistic.
SRGAN
SRGAN is the first framework that supports image enlargement by 4 times while maintaining realism.Researchers proposed the concept of perceptual loss function, which includes an adversarial loss and a content loss.

The adversarial loss uses a discriminator network to determine the authenticity difference between the output image and the original image; the content loss is also driven by perceptual similarity rather than pixel space similarity.
The introduction of perceptual loss function,This enables SRGAN to generate real textures and supplement lost details for a single image when performing image super-resolution reconstruction.
ESRGAN
ESRGAN is based on SRGAN.The network structure, adversarial loss and perceptual loss are further improved.The image quality of super-resolution processing is enhanced. The model improvements include the following three aspects:
1 Introducing the larger and easier-to-train Residual-in-Residual Dense Block (RRDB) to improve the network structure, removing the Batch Normalization (BN) layer, and using residual scaling and smaller initialization to improve the training of deep networks;
2 Use RaGAN to improve the discriminator and predict the relative authenticity between the high-resolution image and the original image rather than the absolute value, so that the generator can restore more realistic texture details of the original image;
3 Improve the perceptual loss by changing the VGG features after activation in the previous SRGAN to be performed before activation, which improves the edge clarity and texture realism of the output image.

Compared with SRGAN,ESRGAN outputs images with better quality and more realistic and natural textures.It won the first place in the PIRM2018-SR challenge. The code can be found at github.com/xinntao/ESRGAN.
Tutorial: Image Enhancement with ESRGAN
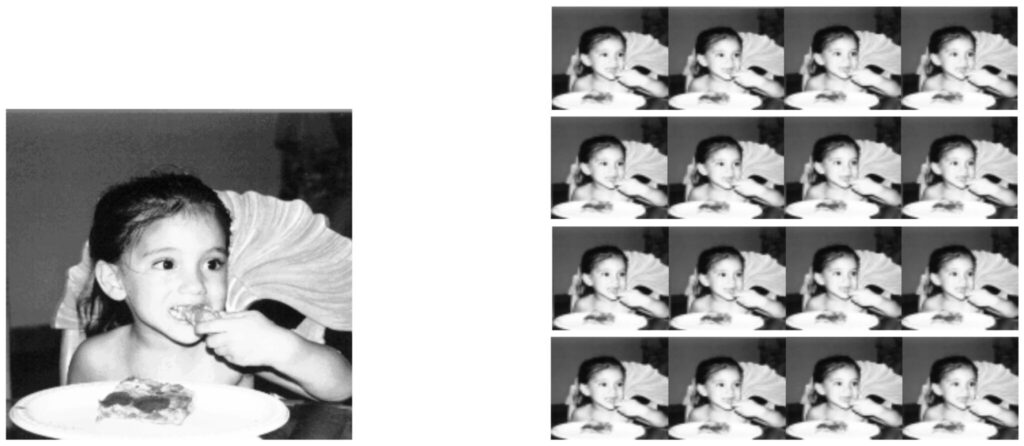
This tutorial will demonstrate how to use the ESRGAN algorithm in TensorFlow Hub for image enhancement. The output of ESRGAN is shown below:

Quick Start with ESRGAN
Open Source Agreement:Apache License 2.0
Installation environment:Python 3.6, TensorFlow 2.3.1
Instructions for use:The model is trained on 128 x 128 images from the DIV2K dataset (bicubic downsampled images).
Note:To run the tutorial, please use "Using ESRGAN for Image Super-Resolution Reconstruction.ipynb" and run the cells in sequence; the model folder in the directory contains the model file, and the esrgan-tf2_1.tar.gz file is the model compression package (the compression package is not used in this tutorial)
Prepare the environment

Defining Helper Functions

Performs super-resolution on an image loaded from a path

Compare output sizes side by side

About OpenBayes
OpenBayes is a leading machine intelligence research institution in China.Provides a number of basic services related to AI development, including computing power containers, automatic modeling, and automatic parameter adjustment.
At the same time, OpenBayes has also launched many mainstream public resources such as data sets, tutorials, and models.For developers to quickly learn and create ideal machine learning models.
Visit Now openbayes.com and register,Get 600 minutes/week of vGPU usage,And 300 minutes/week of free CPU computing time
Take action now and train your super-resolution image enhancement model with ESRGAN!