Command Palette
Search for a command to run...
After Reading the DALL-E Paper, We Found That Large Datasets Also Have Alternative Versions

The OpenAI team's new model DALL-E has been all over the screen. This new neural network uses 12 billion parameters and has been "specially trained" to generate corresponding images after any descriptive text input. Now, the team has open-sourced the paper and some module codes of this project, allowing us to understand the principles behind this artifact.
At the beginning of the year, OpenAI released the image generation model DALL-E, which completely broke the dimensional wall between natural language and images.
No matter how exaggerated or unrealistic the text description is, once it is input into DALL-E, it can generate a corresponding image, and the effect has amazed the entire technology circle.

Great effort brings about miracles: the cost ceiling in the alchemy industry
Computing power: 1024 blocks V 100
When the model was released, developers speculated about the implementation process behind the model and looked forward to the official paper. Recently, the DALL-E paper and some implementation codes were finally made public:

Paper address: https://arxiv.org/abs/2102.12092
As expected, OpenAI has once again demonstrated its strong "money power", as some developers had guessed before.The paper revealed that they used a total of 1024 16GB NVIDIA V100 GPUs throughout the training.
As for the code, the official version currently only opens the dVAE module for image reconstruction.The purpose of this module is to reduce the memory usage of the Transformer trained in the text-image generation task. The Transformer code has not yet been made public, so we can only look forward to subsequent updates. However, even with the code, not everyone is able to reproduce this GPU usage.
Dataset: 250 million image-text pairs + 12 billion parameters
In the paper, the OpenAI team introduced that the research on using machine learning synthesis methods to achieve text-to-image conversion began in 2015.
However, although the models proposed in these previous studies have been able to perform text-to-image generation, their generation results still have many problems, such as object deformation, unreasonable object placement, or unnatural mixing of foreground and background elements.

After research, the team found that previous studies were usually evaluated on smaller datasets (such as MS-COCO and CUB-200). Based on this, the team proposed the following idea:Is it possible that dataset size and model size are limiting factors for current methods?
Therefore, the team used this as a breakthrough, a dataset of 250 million image-text pairs was collected from the Internet.An autoregressive Transformer with 12 billion parameters is trained on this dataset.
In addition, the paper introduces that the training of the dVAE model uses 64 16GB NVIDIA V100 GPUs,The discriminant model CLIP uses 256 GPUs trained for 14 sky.
After intensive training, the team finally obtained DALL-E, a flexible and realistic image generation model that can be controlled by natural language.
The team compared and evaluated the results generated by the DALL-E model with those of other models.In the case of 90%, the generated results of DALL-E are more favorable than those of previous studies.

The picture and text data set is a flat substitute, really good
The success of the DALL-E model also proves the importance of large-scale training data for a model.
It may be difficult for ordinary alchemists to obtain the same data set as DALL-E, but the big brands all have substitute versions (affordable alternative versions).
Although OpenAI stated that their training dataset will not be made public yet,But they revealed that the dataset includes the Conceptual Captions dataset published by Google.
Large-scale image-text dataset mini alternative
The Conceptual Captions dataset was proposed by Google in the paper "Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning" published in ACL 2018.

This paper makes contributions in both data and modeling categories. First,The team proposed a new image caption annotation dataset, Conceptual Captions, which contains an order of magnitude more images than the MS-COCO dataset, including a total of approximately 3.3 million image and description pairs.
Conceptual Captions(Conceptual title) Dataset details
Data source:Google AI
Release time:2018
Quantity included:3.3 million image-text pairs
Data format:.tsv Data size:1.7 GB
Download address:https://orion.hyper.ai/datasets/14682
Using ResNet+RNN+Transformer to build a reverse DALL-E
In terms of modeling, based on previous research results,The team used Inception-ResNet-v2 to extract image features, and then used a model based on RNN and Transformer to generate image captions (DALL-E generates images from text descriptions, and Conceptual Captions generates text annotations from images).
To generate the dataset, the team started with a Flume pipeline that processed about a billion internet web pages in parallel, extracting, filtering, and processing candidate image and caption pairs from those pages, retaining those that passed several filters.
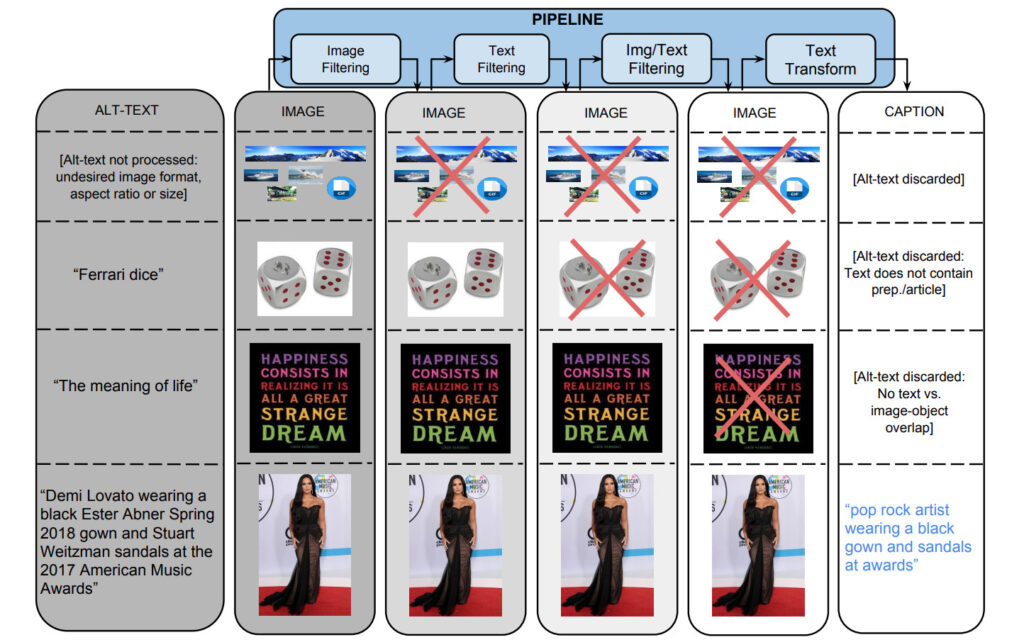
1. Image-based filtering
The algorithm filters images based on encoding format, size, aspect ratio, and objectionable content. It only saves JPEG images that are larger than 400 pixels in both dimensions, and the ratio of the size dimension does not exceed 2. It excludes images that trigger pornography or profanity detection. Ultimately, these filters filtered out more than 65% candidate data.
2. Text-based filtering
The algorithm obtains description text (Alt-text) from HTML web pages, removes titles with non-descriptive text (such as SEO tags or hashtags), and filters out annotations based on preset indicators such as pornography, swear words, profanity, profile photos, etc. In the end, only 3%'s candidate texts passed the screening.
In addition to separate filtering based on image and text content, data is also filtered out where none of the text tags can be mapped to image content.
Assign class labels to images using classifiers provided through the Google Cloud Vision APIs.
3. Text conversion and hyperlexicalization
During the data set collection process, more than 5 billion images from about 1 billion English web pages were processed. Under the high-precision filtering standard, only 0.2% of image and title pairs passed the screening, and the remaining titles were often excluded because they contained proper nouns (people, places, locations, etc.).
The authors trained an RNN-based subtitle model on non-hypersynchronized Alt-text data and give an output example in the figure below.

Model output description: Singer Justin Bieber performs at the Billboard Music Awards at MGM
The team used the Google Cloud Natural Language API to obtain named entity and grammatical dependency annotations. They then used the Google Knowledge Graph (KG) Search API to match named entities with KG entries and leverage related hypernym terms.
For example, “Harrison Ford” and “Calista Flockhart” are both identified as named entities, so they are matched with the corresponding KG entries that have “actor” as their conjunction, and the original surface tokens are then replaced with this conjunction.
Results Evaluation
The team took the test set of the dataset and4000 examples were randomly extracted and manually evaluated. Among the 3 annotations, more than 90% annotations received the majority of good ratings.
The team compared the differences between the model trained on COCO and the model trained on Conceptual.
in,The first difference is that the training results based on Conceptual are more social than the training results of COCO based on natural pictures.
For example, in the leftmost image below, the COCO-trained model uses "group of men" to refer to the people in the image, while the Conceptual-trained model uses the more appropriate and more informative term "graduates".

The second difference is that COCO-trained models often seem to "associate on their own" and "fabricate" some descriptions out of thin air.For example, it hallucinated the first picture as "in front of a building", the second picture as "a clock and two doors", and the third picture as "a birthday cake". In contrast, the team's model did not detect this problem.
The third difference is the types of images that can be used.Since COCO only contains natural images, cartoon images like the fourth one in the above picture will cause "associative" interference to the COCO-trained model, such as "stuffed toy", "fish", "side of the car" and other non-existent things. In contrast, the Conceptual-trained model can easily handle these images.
The launch of the DALL-E model has also made many researchers in this field sigh: data is really the cornerstone of AI. Do you also want to try to make miracles happen? Why not start with the Conceptual Captions dataset!
access https://orion.hyper.ai/datasets Or clickRead the original article, and get more datasets!
News Source:
https://openai.com/blog/dall-e/
DALL-E paper address:
https://arxiv.org/abs/2102.12092
DALL-E project GitHub address:
https://github.com/openai/dall-e
Conceptual Captions paper address:








