Command Palette
Search for a command to run...
Comic Translation, Embedding AI, Tokyo University Papers Included in AAAI'21

Recently, a study on the automatic translation of comic text has sparked heated discussion. The Mantra team, composed of two PhDs from the University of Tokyo, published a paper, which has been included in AAAI 2021. The Mantra project aims to provide automated machine translation tools for Japanese comics.
Recently, a joint release by the Mantra team of the University of Tokyo, Yahoo (Japan) and other institutions Towards Fully Automated Manga Translation(Paper address https://arxiv.org/abs/2012.14271)The paper has attracted the attention of academia and the two-dimensional community.

The Mantra team successfully achievedThe dialogues, atmosphere words, labels and other texts in the comics are automatically recognized, and the characters are distinguished and the context is connected. Finally, the translated text is accurately replaced and embedded in the bubble area.
With this magical translation tool, the translation team and comic fans should be very happy.
Publish papers, publish data sets, and commercialize
In terms of scientific research, the paper has been accepted by AAAI 2021. The research team has also opened up a translation evaluation dataset consisting of five comics of different styles (fantasy, romance, fighting, suspense, and life).
OpenMantra comic translation evaluation dataset
Paper address:https://arxiv.org/abs/2012.14271
Data format: annotated JSON files and raw images
Data content:1593 sentences, 848 scenes, 214 comic pages
Data size: 36.8 MB
Updated: December 7, 2020
Download address:https://orion.hyper.ai/datasets/14137
In terms of productization,Mantra plans to launch a packaged automatic translation engineIt not only provides automated comic translation and distribution services to publishers, but also releases services for individual users.
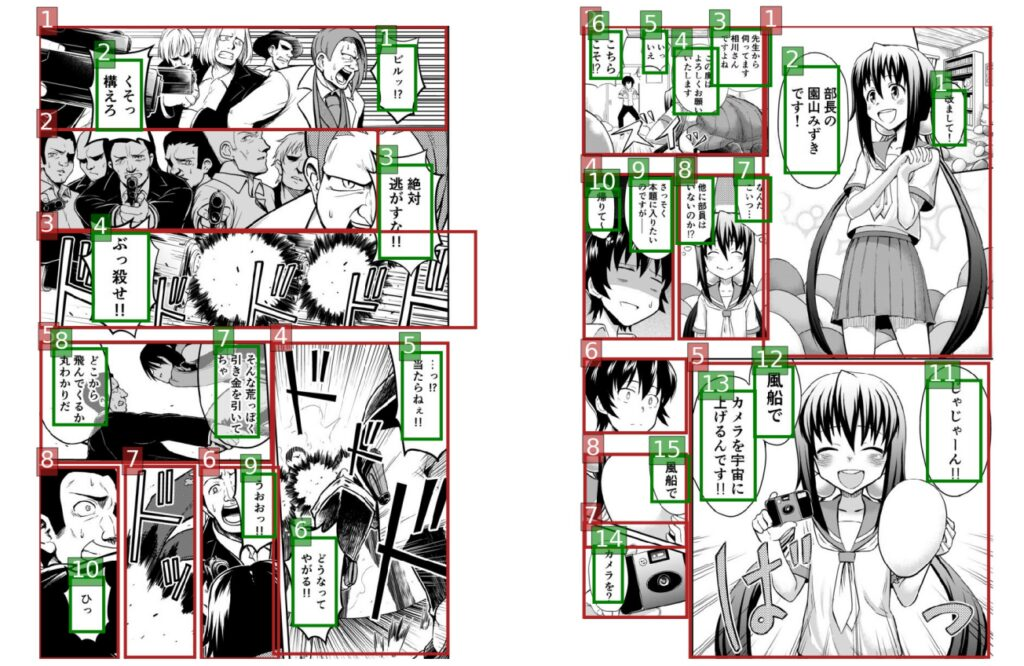
Below are some of the translations of the Japanese manga "Surrounding Men" selected from Mantra's official Twitter account.This multi-frame, lightly danmei-style comic is full of joy and gay love, with the anthropomorphic background of commonly used digital devices in life.:
slideView the original Japanese version of "Nearby Man"
and automatic machine translation of Chinese and English versions
Recognition, translation, and embedding are all important steps
The specific implementation steps are explained in detail by the Mantra research team in the paper "Towards Fully Automated Manga Translation".
The first step is to locate the text
The first step in achieving automated comic translation is to extract the text area.
However, due to the particularity of comics, dialogues from different characters, onomatopoeia, text annotations, etc. will all be displayed in a comic picture. Cartoonists will use bubbles, different fonts, and exaggerated fonts to display texts with different effects.
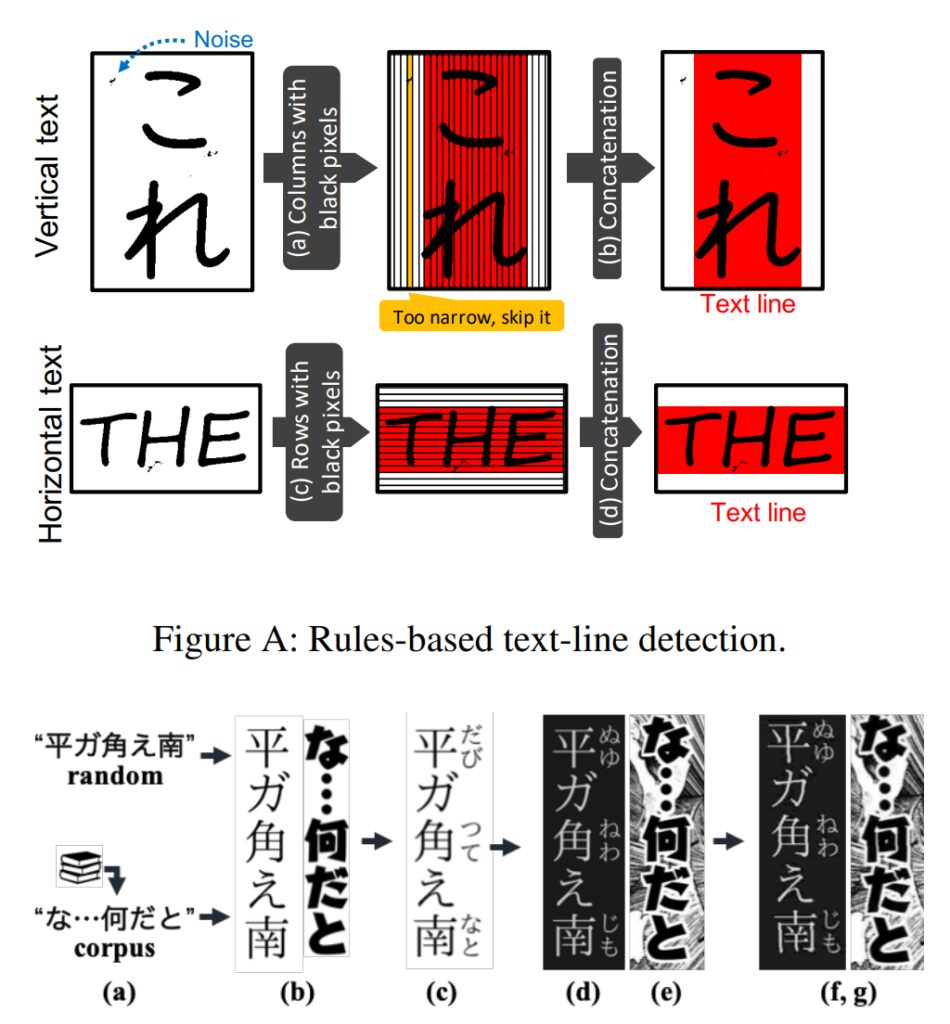
The research team found that due to these various fonts and hand-drawn styles in comics, even the most advanced OCR systems (such as Google Cloud Vision API) perform poorly on comic text.
Therefore, the team developed a text recognition module optimized for comics, which can recognize special characters by detecting text lines and identifying the characters in each text line.
Step 2 Content Identification
In comics, the most common text is the dialogue between characters, and the dialogue text bubbles will be cut into multiple pieces.
This requires that automated machine translation needs to accurately distinguish roles, pay attention to the connection between subjects and avoid repetition in the context, which puts higher demands on machine translation.
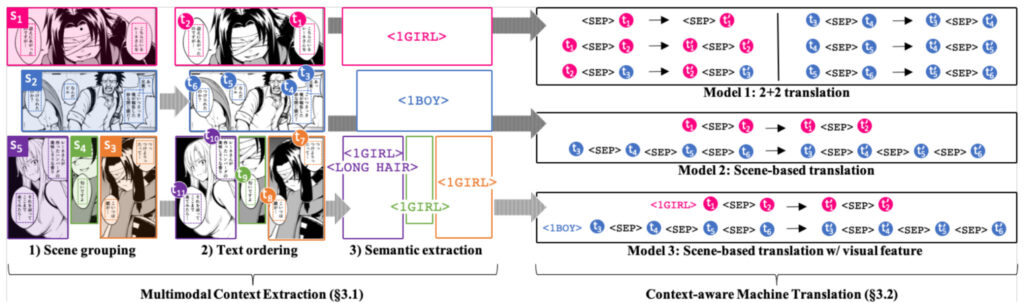
In this step, it is necessary to achieve it through context awareness, emotion recognition and other methods. In context awareness, the Mantra team used three methods: text grouping, text reading order, and extraction of visual semantics to achieve multimodal context awareness.
Step 3 Automatic embedding
The Mantra automated engine can not only distinguish between characters and translate accurately in context, but also solve the most time-consuming and labor-intensive part of comic translation - embedding characters.

In the embedding process, you must first erase the embedded area and then embed the characters. Since the shapes, spellings, combinations, and connected readings of Japanese, Chinese, and English characters are all different, this process is particularly difficult.
In this step, you need to do: page matching → text box detection → pixel counting of text bubbles → splitting of connected bubbles → alignment between languages → text recognition → context extraction.
Experiment: Dataset and Model Testing
In the experimental part of the paper, the Mantra team mentioned that there is currently no comic dataset that includes multiple languages, so they created the OpenMantra (open source) and PubManga datasets, which OpenMantra is used to evaluate machine translation and contains 1,593 sentences, 848 scenes and 214 pages of comics. The Mantra team has asked professional translators to translate the dataset into English and Chinese.

The PubManga dataset is used to evaluate the constructed corpus, which contains annotations of: 1) bounding boxes of text and frames; 2) text (character sequences) in Japanese and English; and 3) reading order of frames and text.
To train the model, the team prepared 842,097 pairs of comic pages in Japanese and English, with a total of 3,979,205 pairs of Japanese-English sentences.The specific method can be found in the paper. The final model effect evaluation is done manually. The Mantra team invitedFive professional Japanese-English translators, score the sentences with a professional translation evaluation program.
Behind the project: interesting souls learning together
Currently, this paper has been included in AAAI 2021, and the productization work is also progressing steadily. From the Mantra team’s Twitter, we can see that many comics have successfully used Mantra for automatic machine translation.
Such a treasure project was completed by two doctoral students from the University of Tokyo. CEO Shonosuke Ishiwatari and CTO Ryota Hinami both graduated with a doctorate from the University of Tokyo and founded the Mantra team in 2020.

CEO Shonosuke Ishiwa,He entered the undergraduate class of the Department of Information Science at the University of Tokyo in 2010 and graduated with a Ph.D. in 2019.He mainly focuses on research and development in the field of natural language processing, including machine translation and dictionary generation, and is also the second author of this paper.
It is worth mentioning that Shi He Xiangzhisuke has rich research experience. Not only has he been an exchange scholar at CMU, he also interned at Microsoft Research Asia in Beijing for half a year from 2016 to 2017. At that time, he was engaged in research on NLC (Natural Language Computing) in the team of MSRA Chief Researcher Liu Shujie.
CTO Hinami Ryotaishi entered school in the same year as Shonosuke and focused on the field of image recognition.In 2016-17, I interned at Microsoft Research Asia with Ishiwa Shonosuke.
This pair of friends with complementary skills completed most of Mantra's work. Isn't it enviable from the amount of hair to the results?
If you want to learn more about Mantra, you can visit the paper (https://arxiv.org/abs/2012.14271)、Project official website(https://mantra.co.jp/)Or download the dataset(https://orion.hyper.ai/datasets/14137), for further research.








