Command Palette
Search for a command to run...
Free the Original Artist! Wav2Lip Uses AI to Listen to the Sound and Synchronize the character's Lip Movements

"seeing is believing"AI technology has become ineffective. Face-changing and lip-syncing technologies are emerging one after another, and the effects are becoming more and more realistic. Wav2Lip The model only needs an original video and a target audio to combine them into one.
In recent years, Hollywood animations have repeatedly won more than $1 billion in box office, such as "Zootopia" and "Frozen", all of which are of excellent quality.Just taking the lip movements as an example, it is very rigorous, and the lip movements of animated characters are almost identical to those of real people.
To achieve such an effect, a very complicated process is required, which consumes huge manpower and material resources. Therefore, many animation producers only use relatively simple lip movements to save costs.
Now, AI is working to ease the work of original artists. A team from the University of Hyderabad in India and the University of Bath in the UK published a paper at ACM MM2020 this year."A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild",An AI model called Wav2Lip is proposed, which only needs a video of a person and a target voice to combine the two into one, making the two work together seamlessly.
Lip syncing technique Wav2Lip, the effect is so outstanding
There are actually many technologies for lip syncing. Even before the emergence of deep learning-based technology, there were some technologies that matched the character's lip shape with the actual voice signal.
But this Wav2Lip shows an absolute advantage among all the methods. Other existing methods are mainly based on static images to output lip-synced videos that match the target voice, but lip-syncing often does not work well for dynamic, speaking characters.
Wav2Lip can directly perform lip conversion on dynamic videos and output video results that match the target voice.
In addition, not only videos but also lip syncing to animated pictures will be available, thus enriching your emoticon packages!

Manual evaluation showed,Compared to existing methods, videos generated by Wav2Lip ,outperform existing methods more than 90% of the time.
How effective is the model? Super Neuro conducted some tests. The following video shows the running effect of the official demo. The input materials are the test materials provided by the official website, as well as the Chinese and English test materials selected by Super Neuro.
The characters in the original video input are not speaking
Through AI model operation, the character's lip shape is synchronized with the input voice
We can see that the effect is perfect in the official demo animation video. In the super neural real person test, except for the slight deformation and shaking of the lips, the overall lip sync effect is still relatively accurate.
Tutorial is out, learn in three minutes
After reading this, are you eager to try it? If you already have a bold idea, why not start now?
Currently, the project has been open sourced on GitHub, and the author provides interactive demonstrations, Colab notebooks, and complete training code, inference code, pre-trained models, and tutorials.
The project details are as follows:
Project Name:Wav2Lip
GitHub address:
https://github.com/Rudrabha/Wav2Lip
Project operating environment:
- Language: Python 3.6+
- Video processing program: ffmpeg
Download the pre-trained face detection model:
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
In addition to preparing the above environment, you also need to download and install the following software packages:
- librosa==0.7.0
- numpy==1.17.1
- opencv-contrib-python>=4.2.0.34
- opencv-python==4.1.0.25
- tensorflow==1.12.0
- torch==1.1.0
- torchvision==0.3.0
- tqdm==4.45.0
- numba==0.48
However, you don’t have to prepare for these cumbersome procedures.You only need to prepare a picture/a video of a person (CGI person is also OK) + an audio (synthetic audio is also OK).You can run it with just one click on the domestic machine learning computing power container service platform.
Portal:https://openbayes.com/console/openbayes/containers/EiBlCZyh7k7
Currently, the platform also offers free vGPU usage time every week, so everyone can easily complete the tutorial.
The model has three weights: Wav2Lip, Wav2Lip+GAN, and Expert Discriminator. The latter two are significantly better than the Wav2Lip model alone. The weight used in this tutorial is Wav2Lip+GAN.
The model authors emphasize thatAll results of its open source code should only be used for research/academic/personal purposes,The model is trained based on the LRS2 (Lip Reading Sentences 2) dataset, so any form of commercial use is strictly prohibited.
To avoid abuse of the technology, the researchers also strongly recommend that any content created using Wav2Lip's code and models must be marked as synthetic.
The key technology behind it: lip sync discriminator
How does Wav2Lip listen to audio and lip-sync so accurately?
It is said that the key to achieving a breakthrough is:The researchers used a lip sync discriminator,This forces the generator to continuously produce accurate and realistic lip movements.
In addition, this study improves the visual quality by using multiple consecutive frames instead of a single frame in the discriminator and using a visual quality loss (rather than just a contrastive loss) to account for temporal correlations.
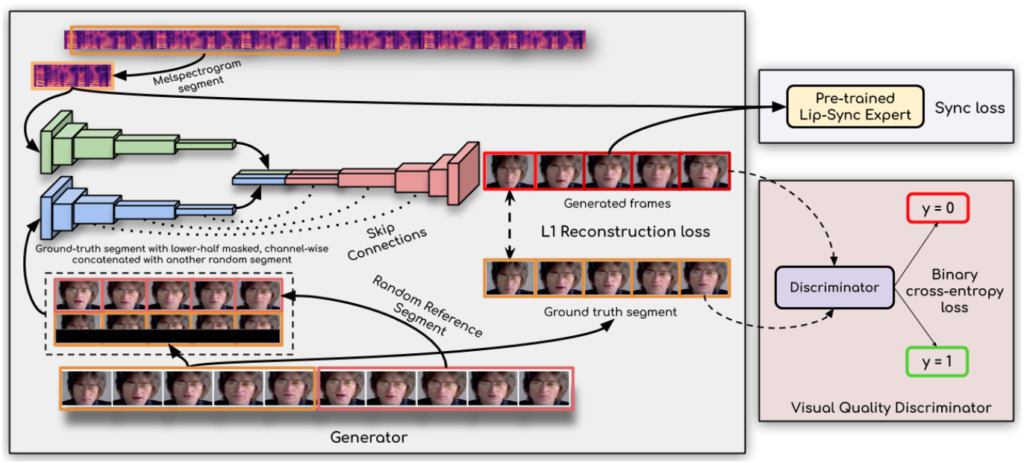
The researchers said,Their Wav2Lip model is almost universal, applicable to any face, any voice, any language, and can achieve high accuracy for any video.It can be seamlessly merged with the original video, can also be used to convert animated faces, and importing synthesized speech is also feasible.
It is conceivable that this artifact may create another wave of ghost videos...
Paper address:
Demo address:
https://bhaasha.iiit.ac.in/lipsync/
-- over--








