Command Palette
Search for a command to run...
Containing Nearly 200,000 Books, OpenAI-level Training Dataset Is Online

Do you also want to train a powerful GPT model like OpenAI, but suffer from the lack of sufficient training data sets? Recently, a netizen in the Reddit community uploaded a plain text data set containing nearly 200,000 books. Training a first-class GPT model is no longer a dream.
Recently, a hot resource post in the machine learning community "A dataset of 196,640 plain text books for training large language models such as GPT"It sparked a heated discussion.
The dataset covers download links for all large text corpora as of September 2020. In addition, it also contains the plain text of all books in bibliotik (an online book resource library), as well as a large amount of code for training.
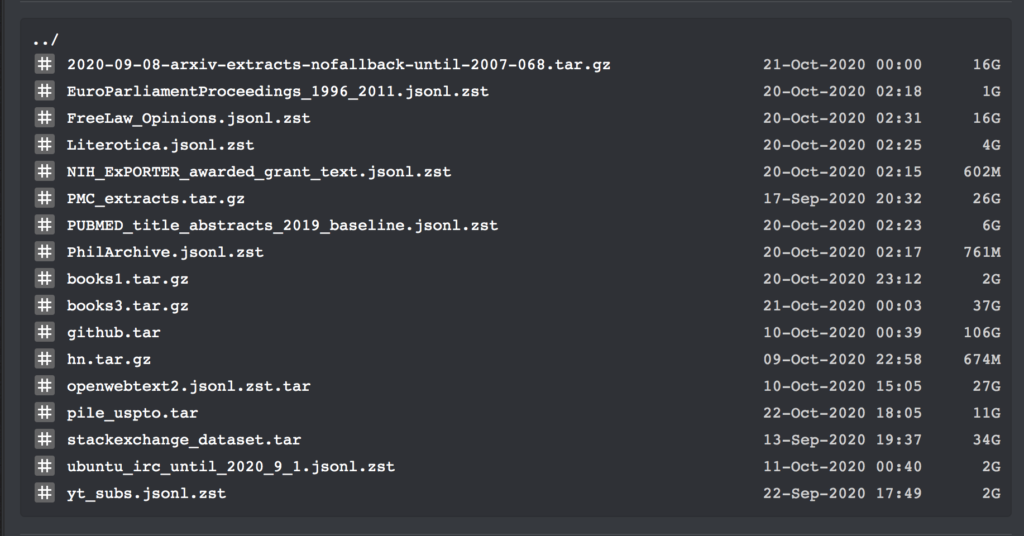
Just yesterday, in the machine learning community of reddit, netizen Shawn Presser released a set of plain text data sets, which received unanimous praise.
These datasets contain a total of 196,640 volumes of plain text data, which can be used to train large language models such as GPT.
Since this dataset contains multiple datasets and training codes, we will not go into details here. We will only list the specific information of the books1 and books3 datasets:
Book Plain Text Dataset
Posted by: Shawn Presser
Quantity included:books1: 1800 books; book3: 196640 books
Data format:txt format
Data size:books1: 2.2 GB; books3: 37 GB
Update time:October 2020
Download address:https://orion.hyper.ai/datasets/13642
According to the dataset organizer Shawn Presser, the quality of these datasets is very high. It took him about a week to repair the epub2txt script for the books1 dataset alone.
In addition, he also stated,The books3 dataset appears to be similar to the mysterious “books2” dataset from OpenAI’s paper.However, since OpenAI did not provide detailed information on this, it is impossible to understand any differences between the two.
However, in his opinion, this dataset is extremely close to the training dataset of GPT-3. With it, the next step is to train an NLP language model that is comparable to GPT-3. Of course, there is another condition: you also need to prepare enough GPUs.

According to the introduction,The books1 dataset contains 1,800 books, all from the large text corpus BookCorpus.These include poetry, novels, etc.
For example, "Shades of Gray: Noir, City Shrouded By Darkness" by American writer Kristie Lynn Higgins, "Animal Theater" by Benjamin Broke, and "America One" by T.I. Wade.
The powerful GPT-3 is backed by the training dataset
Those who are interested in the field of natural language processing know that in May this year, the natural language processing model GPT-3, which was built by OpenAI at a huge cost, attracted great attention in the industry with its amazing text generation ability, and has been popular ever since.
GPT-3 can not only answer questions, translate, and write articles better, but also has some mathematical calculation capabilities. The reason why it has these powerful capabilities is inseparable from the huge training data set behind it.
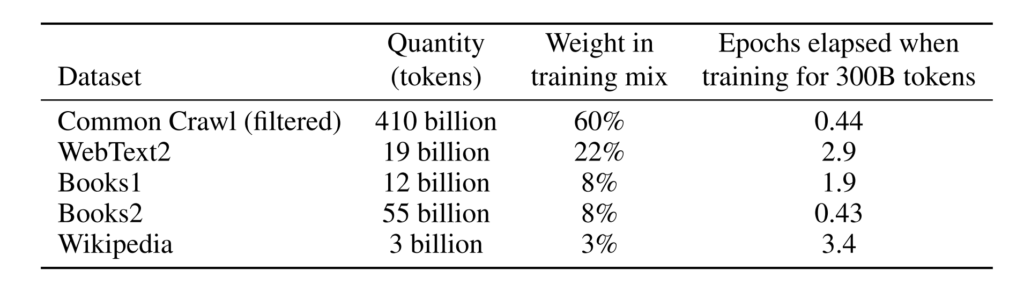
According to the introduction,The training data set used by GPT-3 is very large. It is based on the CommonCrawl data set containing nearly 1 trillion words, web text, data, Wikipedia and other data. The largest data set it uses has a capacity of 45TB before processing.Its training costs also reached a staggering 12 million US dollars.
Larger training data sets and more model parameters make GPT-3 far ahead in natural language processing models.
However, for ordinary developers, if they want to train a first-class language model, not to mention the high training cost, they will be stuck at the step of training the dataset.
Therefore, the data set brought by Shawn Presser undoubtedly solved this problem, and some netizens said that they saved huge costs through this work.
Super Neuro has now moved the books1 dataset to https://orion.hyper.ai,Search for the keyword "book" or "text", or click on the original text to obtain the dataset.
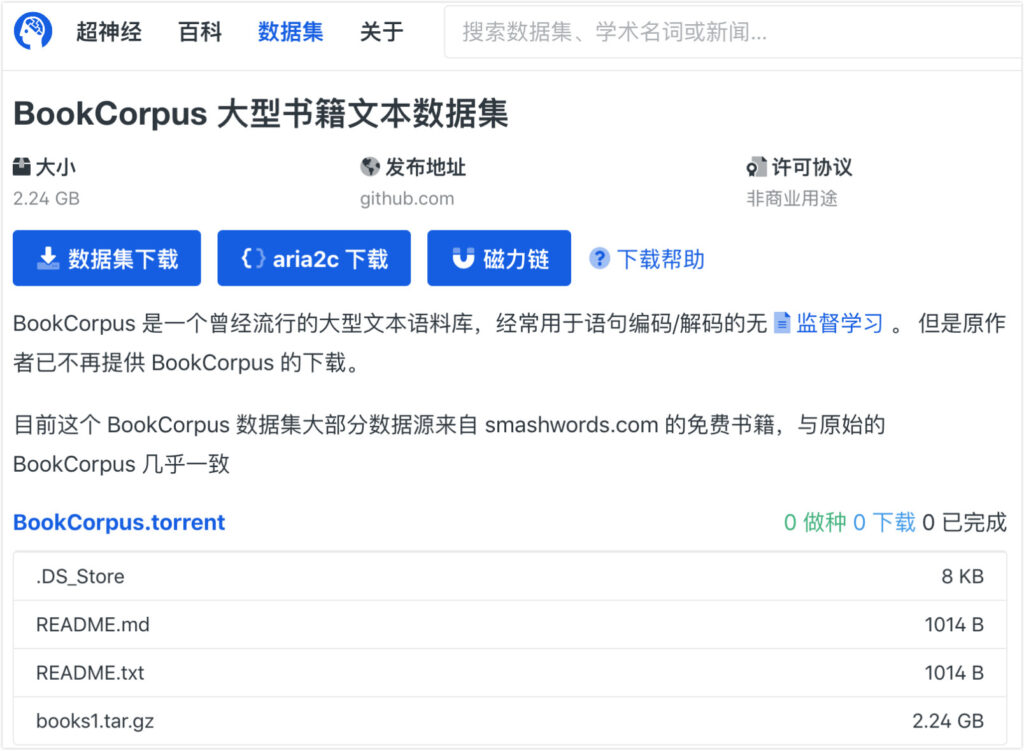
Other datasets can be obtained from the following links:
Books3 dataset download address:
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
Training code download address:
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
Original reddit post:https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
-- over--








