Command Palette
Search for a command to run...
Damedane, the Divine Song of B Station: The Essence Lies in Face-changing, You Can Learn It in Five Minutes

AI face-changing technologies emerge in an endless stream, but each generation is stronger than the previous one. Recently, an AI face-changing model first order motion model published in NeurIPs 2019 has become popular, and its expression transfer effect is better than other methods in the same field. Recently, this technology has caused a new trend on Bilibili...
Recently, a wave of videos with an overly "raw" style (B station slang, meaning devilishly funny) have emerged on Bilibili, with millions of views, making them quite popular.
Up masters with full skills, use 「First order motion first order motion model」The AI face-changing project has generated a variety of videos with unique styles.
For example, Jacky Cheung, Du Fu, Tang Monk, and the panda-head emoji sang "Damedane" and "Unravel" with great emotion... The picture looks like this:


If you are not satisfied with the animated pictures, let’s go directly to the video:
The crying cat version of the brainwashing song "damedane", which has been played 2.113 million times so far, source: B station Up master thick hair Hu Tutu
I have to say, it's a bit addictive... You can go to the small broken station to search for more works to watch.
These videos have attracted countless netizens eager to try, and they have left messages asking for tutorials. Next, let's take a look at the technology that achieves these face-changing effects (the root of all evil):First order motion model.
Learning Garden B Station, multiple tutorials to teach you lip syncing
So far, similar face-changing and lip-syncing technologies have emerged in an endless stream, and every time one is proposed, it will trigger a wave of face-changing craze.
The First order motion model is very popular because it is effective in optimizing facial features and lip shape, and it is easy to use and efficient to implement.
For example, if you want to change the face of "damedane" at the beginning of the article,It only takes a few tens of seconds to achieve and can be learned in five minutes.
Most up-loaders on Bilibili use Google Drive and Colab to conduct tutorials. Considering the difficulty of circumventing the firewall, we selected a tutorial by one of the up-loaders and used the domestic machine learning computing container service (https://openbayes.com), and now you can also take advantage of the free vGPU usage time every week to complete this tutorial easily.
Update 2020-09-30: Currently, bilibili has removed all videos related to "AI face-changing", so the OpenBayes team has added the corresponding text version of the step-by-step tutorial:
You can complete your own "damedane" in less than 5 minutes
This tutorial video explains step by step, even a novice can easily learn this face-changing method. The up master also uploaded the notebook to the platform, and you can use it directly with just one click of clone.
However, many technical Up hosts said that in addition to entertainment, they make videos for technical exchanges, so they hope that everyone will not abuse them maliciously.
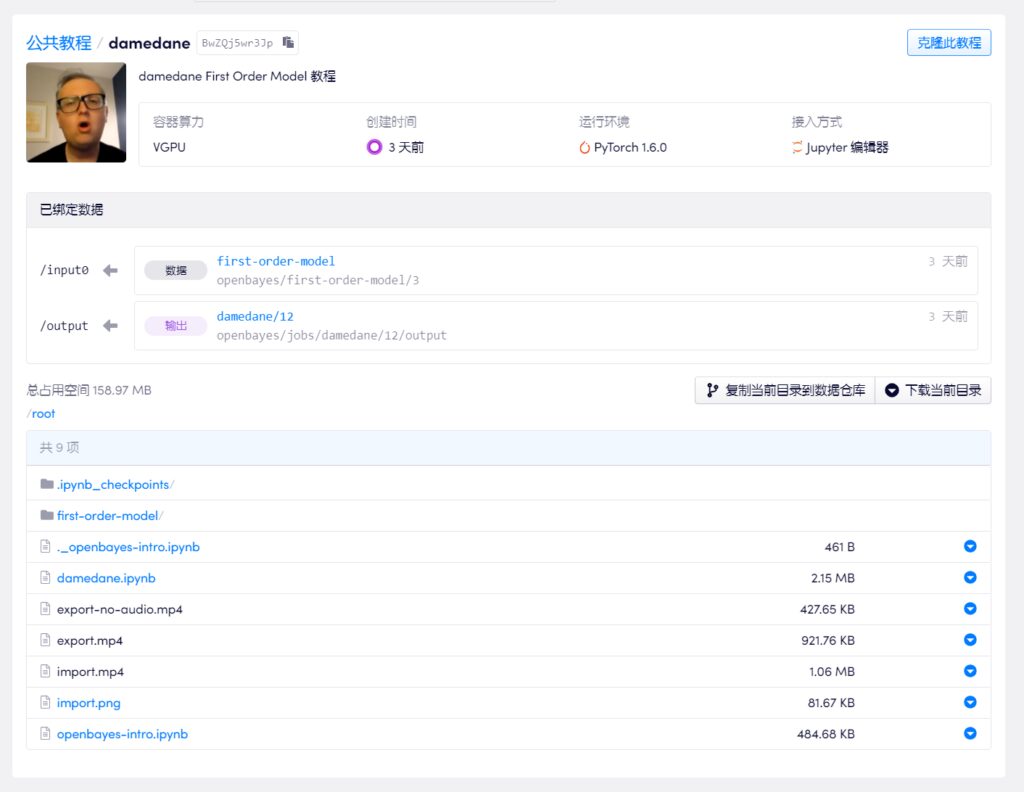
Video tutorial address:
https://openbayes.com/console/openbayes/containers/BwZQj5wr3Jp
Original project Github address:
https://github.com/AliaksandrSiarohin/first-order-model
Another face-changing tool, what’s its use?
The first order motion model comes from a paper presented at the top conference NeurlPS 2019.First Order Motion Model for Image Animation,The authors are from the University of Trento in Italy and snap.

As you can tell from the title,The goal of this paper is to make static images move.Given a source image and a driving video, the image in the source image can be animated along with the action in the driving video. In other words, everything can be animated.
The effect is shown in the figure below. The upper left corner is the driving video, and the rest are source static images:

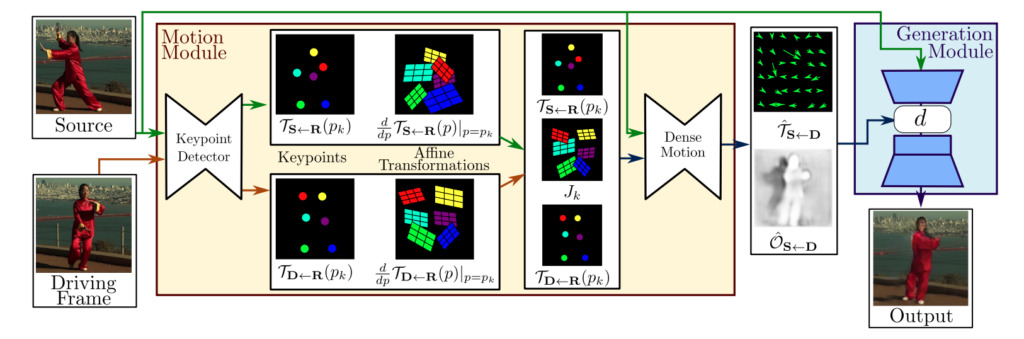
Model framework composition
In general, the framework of the first-order motion model consists of two modules:Motion estimation module and image generation module.
Motion Estimation Module:Through self-supervised learning, the appearance and motion information of the target object are separated and feature represented.
Image generation module:The model models the occlusions that occur during target motion, then extracts appearance information from a given celebrity image and combines it with the previously obtained feature representations for video synthesis.
How is it better than the traditional model?
Some people may wonder, how is this different from previous AI face-changing methods? The author gives an explanation.
The previous face-changing video operation required the following operations:
- Usually, it is necessary to conduct prior training on the facial image data of both parties to be swapped;
- It is necessary to annotate the key points of the source image and then perform corresponding model training.
But in reality, there is less personal face data and not much time for training.Therefore, traditional models usually work better on specific images, but when used on the general public, the quality is difficult to guarantee and they are prone to failure.

Therefore, the method proposed in this paper solves the problem of data dependence and greatly improves the generation efficiency.OnlyIt only needs to be trained on image datasets of the same category.
For example, if you want to achieve expression transfer, no matter whose face you replace, you only need to train on the face dataset; if you want to achieve Tai Chi movement transfer, you can use the Tai Chi video dataset for training.
After the training is completed, using the corresponding pre-trained model, you can achieve the result of making the source image move along with the driving video.

The author compared his method with the most advanced methods in this field, X2Face and Monkey-Net. The results showed that in the same dataset, all indicators of this method were improved.On two face datasets (VoxCeleb and Nemo), our method also significantly outperforms X2Face, which was originally proposed for face generation.

-- over--








