Command Palette
Search for a command to run...
PyTorch 1.5 Released, TorchServe in Collaboration With AWS

Recently, PyTorch released an update to version 1.5. As an increasingly popular machine learning framework, PyTorch also brought major functional upgrades this time. In addition, Facebook and AWS also cooperated to launch two important PyTorch libraries.
As PyTorch is increasingly used in production environments, providing the community with better tools and platforms to efficiently scale training and deploy models has become a top priority for PyTorch.
Recently, PyTorch 1.5 was released.The main torchvision, torchtext, and torchaudio libraries have been upgraded, and features such as converting models from Python API to C++ API have been introduced.

besides,Facebook also collaborated with Amazon to launch two major tools: the TorchServe model serving framework and the TorchElastic Kubernetes controller.
TorchServe aims to provide a clean, compatible, industrial-grade path for large-scale deployment of PyTorch model inference.
The TorchElastic Kubernetes controller allows developers to quickly use Kubernetes clusters to create fault-tolerant distributed training jobs in PyTorch.
This seems to be a move by Facebook and Amazon to declare war on TensorFlow in the large-scale performance AI model framework.
TorchServe: for inference tasks
Deploying machine learning models for inference at scale is not an easy task. Developers must collect and package model artifacts, create a secure serving stack, install and configure software libraries for prediction, create and use APIs and endpoints, generate logs and metrics for monitoring, and manage multiple model versions across potentially multiple servers.
Each of these tasks takes a significant amount of time and can slow down model deployment by weeks or even months. In addition, optimizing services for low-latency online applications is a must.
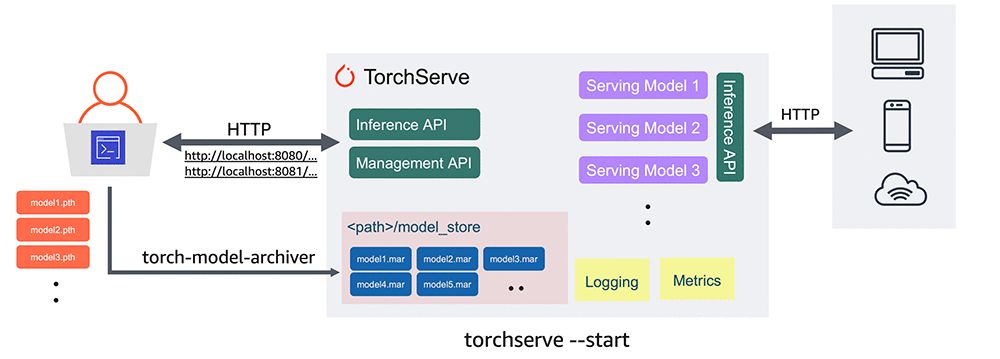
Previously, developers using PyTorch lacked an officially supported method for deploying PyTorch models. The release of the production model serving framework TorchServe will change this situation, making it easier to put models into production.
In the following example, we will show how to extract a trained model from Torchvision and deploy it using TorchServe.
#Download a trained PyTorch modelwget https://download.pytorch.org/models/densenet161-8d451a50.pth#Package model for TorchServe and create model archive .mar filetorch-model-archiver \--model-name densenet161 \--version 1.0 \--model-file examples/image_classifier/densenet_161/model.py \--serialized-file densenet161–8d451a50.pth \--extra-files examples/image_classifier/index_to_name.json \--handler image_classifiermkdir model_storemv densenet161.mar model_store/#Start TorchServe model server and register DenseNet161 modeltorchserve — start — model-store model_store — models densenet161=densenet161.mar
A beta version of TorchServe is now available.Features include:
- Native API: Supports the inference API for prediction and the management API for managing model servers.
- Secure deployment: Includes HTTPS support for secure deployments.
- Powerful model management capabilities: Allows full configuration of models, versions, and individual workers via the command line interface, configuration files, or runtime API.
- Model Archive: Provides tools to perform "model archiving", a process of packaging a model, parameters, and supporting files into a single persistent artifact. Using a simple command line interface, you can package and export a single ".mar" file that contains everything you need to serve a PyTorch model. The .mar file can be shared and reused.
- Built-in model handlers: Supports model handlers covering the most common use cases such as image classification, object detection, text classification, image segmentation. TorchServe also supports custom handlers.
- Logging and Metrics: Supports robust logging and real-time metrics to monitor inference services and endpoints, performance, resource utilization, and errors. You can also generate custom logs and define custom metrics.
- Model Management: Supports managing multiple models or multiple versions of the same model at the same time. You can use model versions to return to earlier versions, or route traffic to different versions for A/B testing.
- Prebuilt images: Once you are ready, you can deploy the Dockerfile and Docker images for TorchServe in both CPU and NVIDIA GPU based environments. The latest Dockerfiles and images can be found here.
Installation instructions, tutorials, and documentation are also available at pytorch.org/serve.
TorchElastic: Integrated K8S controller
As machine learning training models become larger and larger, such as RoBERTa and TuringNLG, the need to scale out to distributed clusters becomes more and more important. To meet this need, preemptible instances (such as Amazon EC2 Spot instances) are often used.
But these preemptible instances themselves are unpredictable, so here comes the second tool, TorchElastic.
The integration of Kubernetes and TorchElastic allows PyTorch developers to train machine learning models on a cluster of compute nodes.These nodes can be changed dynamically without disrupting the model training process.
Even if a node fails, TorchElastic's built-in fault tolerance allows you to pause training at the node level and resume training once the node becomes healthy again.
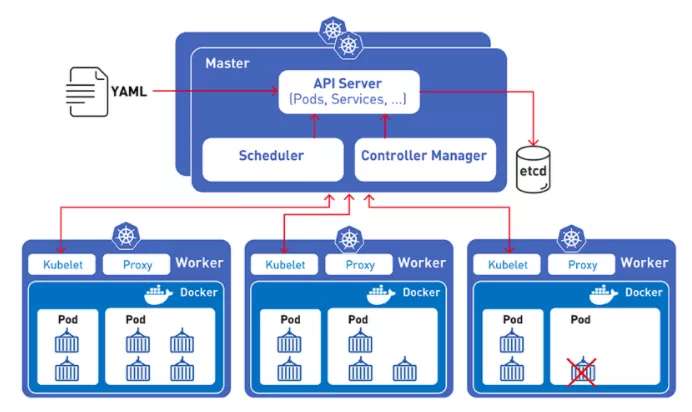
Additionally, using the Kubernetes controller with TorchElastic, you can run the critical task of distributed training on a cluster with replaced nodes in the event of hardware or node recycling issues.
Training jobs can be launched using a portion of the requested resources and can scale dynamically as resources become available, without having to stop or restart.
To take advantage of these capabilities, users simply specify the training parameters in a simple job definition, and the Kubernetes-TorchElastic package manages the job's lifecycle.
Here is a simple example of a TorchElastic configuration for an Imagenet training job:
apiVersion: elastic.pytorch.org/v1alpha1kind: ElasticJobmetadata:name: imagenetnamespace: elastic-jobspec:rdzvEndpoint: $ETCD_SERVER_ENDPOINTminReplicas: 1maxReplicas: 2replicaSpecs:Worker:replicas: 2restartPolicy: ExitCodetemplate:apiVersion: v1kind: Podspec:containers:- name: elasticjob-workerimage: torchelastic/examples:0.2.0rc1imagePullPolicy: Alwaysargs:- "--nproc_per_node=1"- "/workspace/examples/imagenet/main.py"- "--arch=resnet18"- "--epochs=20"- "--batch-size=32"
Microsoft and Google, are you panicking?
The cooperation between the two companies to launch the new PyTorch library may have a deeper meaning, because the "not playing with you" routine is not the first time it has appeared in the history of framework model development.
In December 2017, AWS, Facebook, and Microsoft announced that they would jointly develop ONNX for production environments.This is to counter Google's TensorFlow's monopoly on industrial use.
Subsequently, mainstream deep learning frameworks such as Apache MXNet, Caffe2, and PyTorch have all implemented varying degrees of support for ONNX, which facilitates the migration of algorithms and models between different frameworks.

However, ONNX's vision of connecting academia and industry has not actually met original expectations. Each framework still uses its own service system, and basically only MXNet and PyTorch have penetrated into ONNX.
Today,PyTorch launched its own service system, and ONNX has almost lost its meaning of existence (MXNet said it was at a loss).
On the other hand, PyTorch is constantly being upgraded and updated, and the compatibility and ease of use of the framework are improving.It is approaching and even surpassing its strongest rival, TensorFlow.
Although Google has its own cloud services and frameworks, the combination of AWS's cloud resources and Facebook's framework system will make it difficult for Google to cope with the powerful combination.
Microsoft has been kicked out of the group chat by two of the former ONNX trio. What are Microsoft’s plans for the next step?
-- over--








