Command Palette
Search for a command to run...
This Group of Engineers Has Taken Chinese NLP a Big Step Forward in Their Spare Time

Someone said that if you have studied NLP (natural language processing), you will know how difficult Chinese NLP is.
Although both belong to NLP, there are great differences in analysis and processing between English and Chinese due to different language habits, and the difficulties and challenges are also different.

Moreover, some of the currently popular models are mostly developed for English. Coupled with the unique usage habits of Chinese, many tasks (such as word segmentation) are very difficult, resulting in very slow progress in the field of Chinese NLP.
But this kind of problem may be changed soon, because since last year, many excellent open source projects have emerged, which have greatly promoted the development of NLP Chinese field.
Model: Chinese pre-trained ALBERT
In 2018, Google launched the language model BERT, Bidirectional Encoder Representations from Transformers. Due to its extremely powerful performance, it swept the charts of many NLP standards as soon as it was released and was immediately hailed as a masterpiece.
But one of the drawbacks of BERT is that it is too large. BERT-large has 300 million parameters, which makes it very difficult to train. In 2019, Google AI launched the lightweight ALBERT (A Little BERT), which has 18 times smaller parameters than the BERT model, but has better performance.
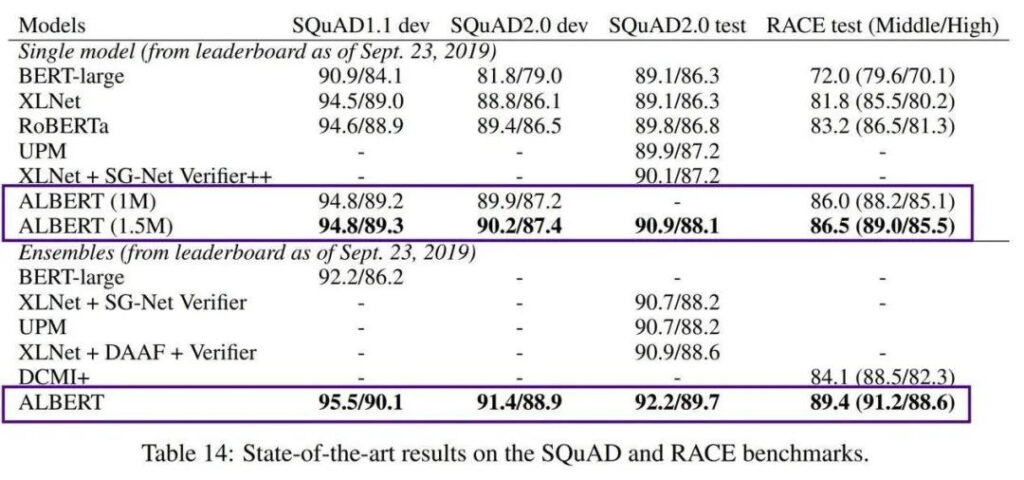
Although it solves the problem of high training cost and huge number of parameters of pre-trained models, AlBERT is still only targeted at English contexts, which makes engineers who focus on Chinese development feel a little helpless.
In order to make this model usable in the Chinese context and benefit more developers, the team of data engineer Xu Liang opened up the first Chinese pre-trained ALBERT model in October 2019.
Project gallery
https://github.com/brightmart/albert_zh
This Chinese pre-trained ALBERT model (denoted as albert_zh) is trained on a massive Chinese corpus. The training content comes from multiple encyclopedias, news, and interactive communities, including 30G of Chinese corpus and more than 100 billion Chinese characters.
From the data comparison, albert_zh's pre-training sequence length is set to 512, the batch size is 4096, and the training generates 350 million training data. Another powerful pre-training model, roberta_zh, generates 250 million training data with a sequence length of 256.
albert_zh pre-training generates more training data and uses longer sequences. It is expected that albert_zh will have better performance than roberta_zh and can handle longer texts better.
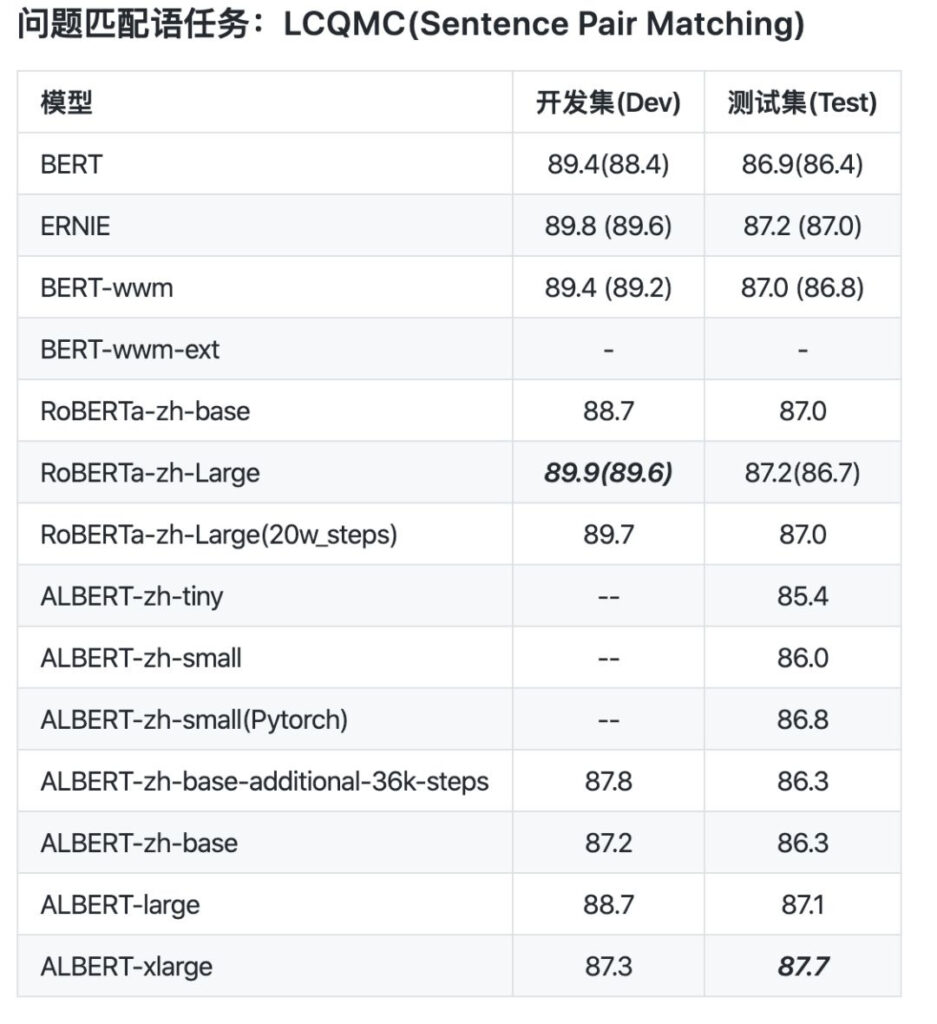
In addition, albert_zh trained a series of ALBERT models with different parameter sizes, from tiny to xlarge, which greatly promoted the popularity of ALBERT in the field of Chinese NLP.
It is worth mentioning that in January 2020, Google AI released ALBERT V2, and then slowly launched the Google Chinese version of ALBERT.
Benchmark: ChineseGLUE for Chinese GLUE
Once we have models, how do we judge whether they are good or bad? This requires a good enough test benchmark. Last year, the benchmark ChineseGLUE for Chinese NLP was also open sourced.
ChineseGLUE is based on the industry-renowned test benchmark GLUE, which is a collection of nine English language understanding tasks. Its goal is to promote the research of general and robust natural language understanding systems.
Previously, there was no Chinese version corresponding to GLUE, and some pre-trained models could not be judged in public tests on different tasks, resulting in a misalignment in the development and application of NLP in the Chinese field, and even a lag in technological application.
Faced with this situation, Dr. Zhenzhong Lan, the first author of AlBERT, Xu Liang, the developer of ablbert_zh, and more than 20 other engineers jointly launched a benchmark for Chinese NLP: ChineseGLUE.
Project gallery
https://github.com/chineseGLUE/chineseGLUE
The emergence of ChineseGLUE has allowed Chinese to be included as an indicator for evaluating new models, forming a complete evaluation system for testing Chinese pre-trained models.
This powerful test benchmark includes the following aspects:
1) A Chinese task benchmark consisting of several sentences or sentence pairs, covering multiple language tasks at different levels.
2) Provide a performance evaluation ranking list, which will be updated regularly to provide a basis for model selection.
3) A collection of benchmark models, including the starting code, pre-trained models, and benchmarks for ChineseGLUE tasks, which are available in frameworks such as TensorFlow, PyTorch, and Keras.
4) Have a huge original corpus for pre-training or language modeling research, which is about 10G (2019), and is planned to be expanded to a sufficient original corpus (such as 100G) by the end of 2020.
The launch and continuous improvement of ChineseGLUE is expected to witness the birth of more powerful Chinese NLP models, just as GLUE witnessed the emergence of BERT.
At the end of December 2019, the project was migrated to a more comprehensive and more technically supported project: CLUEbenchmark/CLUE.
Project gallery
https://github.com/CLUEbenchmark/CLUE
Data: The most complete data set and the largest corpus in history
With pre-trained models and test benchmarks, another important link is data resources such as datasets and corpora.
This led to a more comprehensive organization, CLUE, which is the abbreviation of Chinese GLUE. It is an open source organization that provides evaluation benchmarks for Chinese language understanding. Their focus areas include: tasks and datasets, benchmarks, pre-trained Chinese models, corpora and ranking releases.
Some time ago, CLUE released the largest and most comprehensive Chinese NLP dataset, covering 142 datasets in 10 categories, CLUEDatasetSearch.

Project gallery
https://github.com/CLUEbenchmark/CLUEDatasetSearch
Its content includes all major directions of current research such as NER, QA, sentiment analysis, text classification, text assignment, text summarization, machine translation, knowledge graphs, corpora, and reading comprehension.
As long as you type in keywords or information such as the field you belong to on the website page, you can search for the corresponding resources. Each data set will provide information such as name, update time, provider, description, keywords, category, and paper address.
Recently, the CLUE organization has opened up 100 GB of Chinese corpus and a collection of high-quality Chinese pre-trained models, and submitted a paper to arViv.

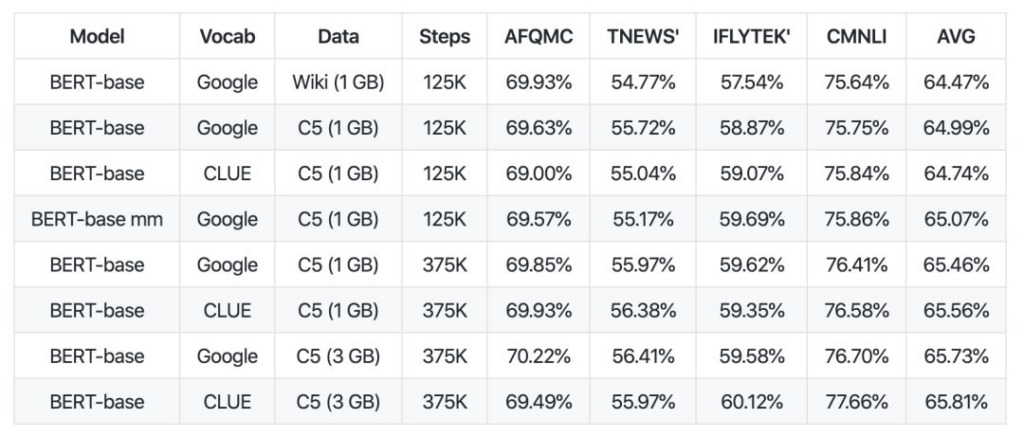
In terms of corpus, CLUE has open-sourced CLUECorpus2020: Large-scale Pre-training Corpus for Chinese 100G of Chinese pre-training corpus.
These contents are obtained after corpus cleaning of the Chinese part of the Common Crawl dataset.
They can be used directly for pre-training, language model or language generation tasks, or publish small vocabularies dedicated to Chinese NLP tasks.
Project gallery
https://github.com/CLUEbenchmark/CLUECorpus2020
In terms of model collection, CLUEPretrainedModels was released: a collection of high-quality Chinese pre-trained models - the most advanced large models, the fastest small models, and similarity-specific models.
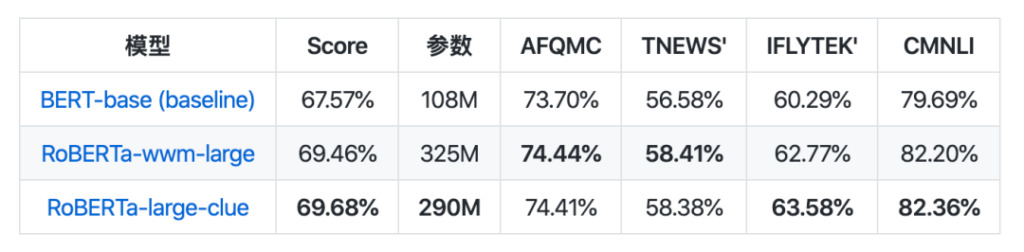
The large model achieves the same results as the current best Chinese NLP model, and even outperforms some tasks. The small model is about 8 times faster than Bert-base. The semantic similarity model is used to process semantic similarity or sentence pair problems, and is likely to be better than directly using a pre-trained model.
Project gallery
https://github.com/CLUEbenchmark/CLUEPretrainedModels
The release of these resources, to some extent, is like fuel to drive the development process, and sufficient resources may open up the road to rapid development of the Chinese NLP industry.
They make Chinese NLP easy
From a linguistic perspective, Chinese and English are the two languages with the largest number of users and the greatest influence in the world. However, due to their different language characteristics, they also face different problems in the research of NLP field.
Although the development of Chinese NLP is indeed more difficult and lagging behind the research on English, which can be better understood by machines, it is precisely because of the engineers mentioned in the article who are willing to promote the development of Chinese NLP and continue to explore and share their results that these technologies can be better iterated.
Thanks to their efforts and contributions to so many high-quality projects! At the same time, we hope that more people can participate and jointly promote the development of Chinese NLP.
-- over--








