Command Palette
Search for a command to run...
Nemotron-CC-Math Mathematics pre-training Dataset
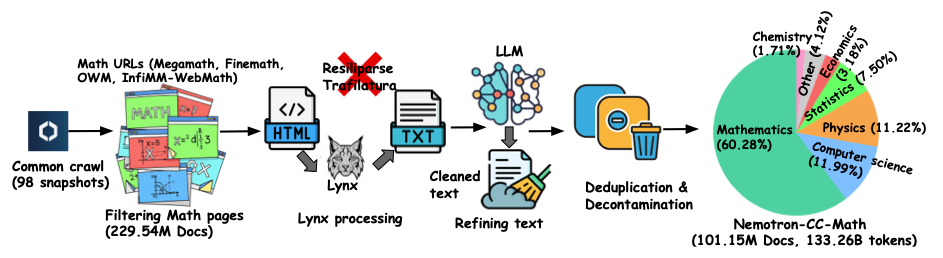
Nemotron-CC-Math is a high-quality, large-scale pre-training dataset focused on mathematics, released by NVIDIA and Boston University in 2025. The related paper results are "Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset”, aims to preserve and display high-value mathematical and code content, thereby driving the next wave of intelligent, globally capable language models. This dataset, containing 133 billion tokens, was built from Common Crawl using an extraction and normalization pipeline based on NVIDIA Lynx and a lightweight LLM. While preserving the structure of equations and code, the mathematical content is standardized into an editable LaTeX format. This represents the first reliable coverage of diverse (including long-tail) mathematical formats at web scale; its advantages have been validated in multiple benchmarks.
Citation
@article{karimi2025nemotroncc, title = {Nemotron-cc-math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset}, author = {Rabeeh Karimi Mahabadi, Sanjeev Satheesh, Shrimai Prabhumoye, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro}, url = {https://arxiv.org/abs/2508.15096}, year = {2025} }
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.