Command Palette
Search for a command to run...
WideSearch Information Gathering Benchmark Dataset
Date
Organization
Paper URL
License
Other
*This dataset supports online use.Click here to jump.
WideSearch is the first agent evaluation benchmark dataset designed for "broad info-seeking" released by ByteDance's Seed team in 2025. The related paper results are "WideSearch:Benchmarking Agentic Broad Info-Seeking", which aims to systematically evaluate and promote the reliability and integrity of large language models in large-scale fact collection, synthesis and verifiable structured output. The benchmark consists of 200 high-quality questions (100 English questions and 100 Chinese questions) carefully selected and manually cleaned by the research team from real user queries. These questions come from more than 15 different fields.
Data Fields:
- instance_id: unique ID of the task (corresponding to the gold CSV file name).
- query: A natural language instruction, usually specifying the required column names and Markdown table output requirements.
- evaluation: a serialized (string) object used for automatic evaluation, containing:
- unique_columns: primary key columns (for row alignment);
- required: column name that must appear;
- eval_pipeline: column-level evaluation configuration (such as preprocess, metric, criterion).
- language: Task language, the value can be en or zh.
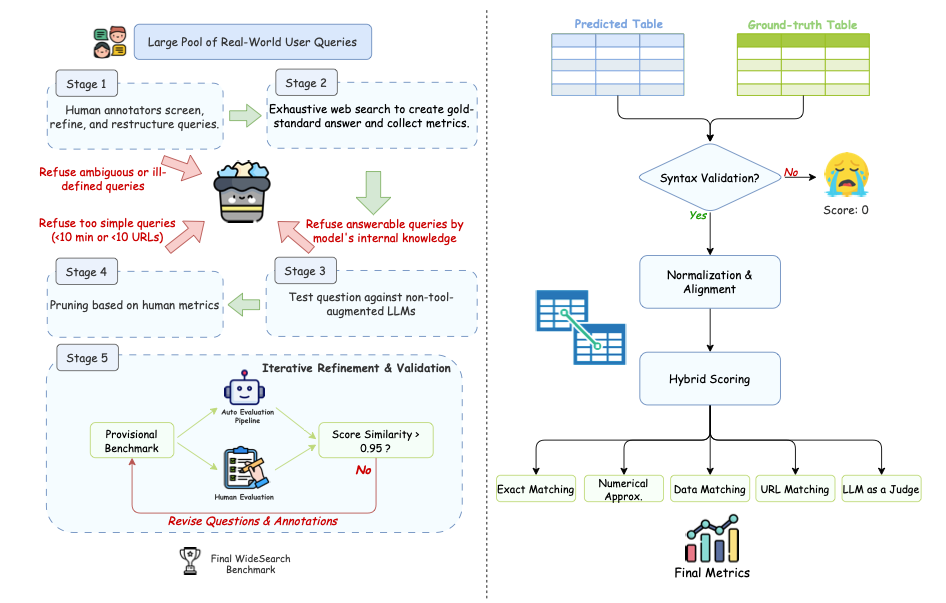
Data construction and automatic evaluation flow chart
Citation
@misc{wong2025widesearchbenchmarkingagenticbroad,
title={WideSearch: Benchmarking Agentic Broad Info-Seeking},
author={Ryan Wong and Jiawei Wang and Junjie Zhao and Li Chen and Yan Gao and Long Zhang and Xuan Zhou and Zuo Wang and Kai Xiang and Ge Zhang and Wenhao Huang and Yang Wang and Ke Wang},
year={2025},
eprint={2508.07999},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.07999},
}
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.