Command Palette
Search for a command to run...
LLM4Mat-Bench Crystal Structure Dataset
Date
Publish URL
Paper URL
LLM4Mat-Bench is a multimodal language model evaluation dataset for material property prediction jointly created by Princeton University, University of Toronto and other institutions. The related paper results are "LLM4Mat-Bench: Benchmarking Large Language Models for Materials Property Prediction", which aims to evaluate the performance of large language models (LLMs) in material property prediction and material discovery tasks. The dataset contains about 1.97 million crystal structure samples from 10 public material databases, covering 45 different material physical and chemical properties. It is the largest benchmark to date for evaluating the performance of large language models (LLMs) for material property prediction.
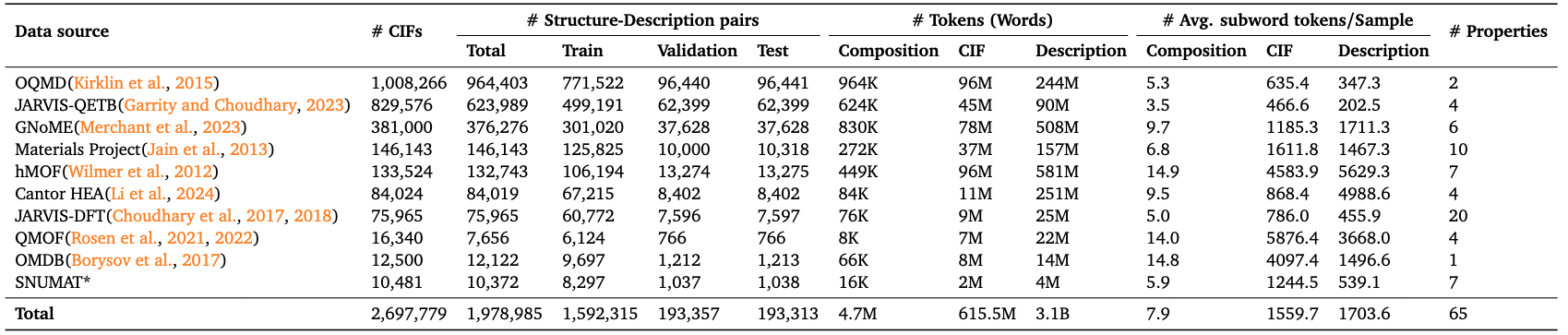
Total amount of data:
- Crystal composition mode (Composition): about 4.7M tokens
- Crystal structure mode (CIF): about 615.5M tokens
- Text Descriptions: about 3.1B tokens The process of building this dataset includes collecting original CIF files and material properties from multiple mainstream material databases, and automatically generating structural language descriptions based on crystal structures, thereby forming multi-modal, unified structure data samples. Each sample record contains the corresponding material ID, chemical formula, property values (such as band gap, formation energy, density, elastic modulus, etc.) and other information. The core goal of LLM4Mat-Bench is to promote the cross-integration of materials science and natural language processing, and to promote the research and application development in the fields of task-specific model evaluation, attribute prediction, instruction fine-tuning, etc. Its multi-source, multi-modal, and large-scale characteristics make it an important reference benchmark in the research of material language models.
Citation
"`bib @article{rubungo2025llm4mat, title={LLM4Mat-bench: benchmarking large language models for materials property prediction}, author={Rubungo, Andre Niyongabo and Li, Kangming and Hattrick-Simpers, Jason and Dieng, Adji Bousso}, journal={Machine Learning: Science and Technology}, volume={6}, number={2}, pages={020501}, year={2025}, publisher={IOP Publishing} }
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.