Command Palette
Search for a command to run...
JMED Chinese Real Medical Data Dataset
Date
Paper URL
License
MIT
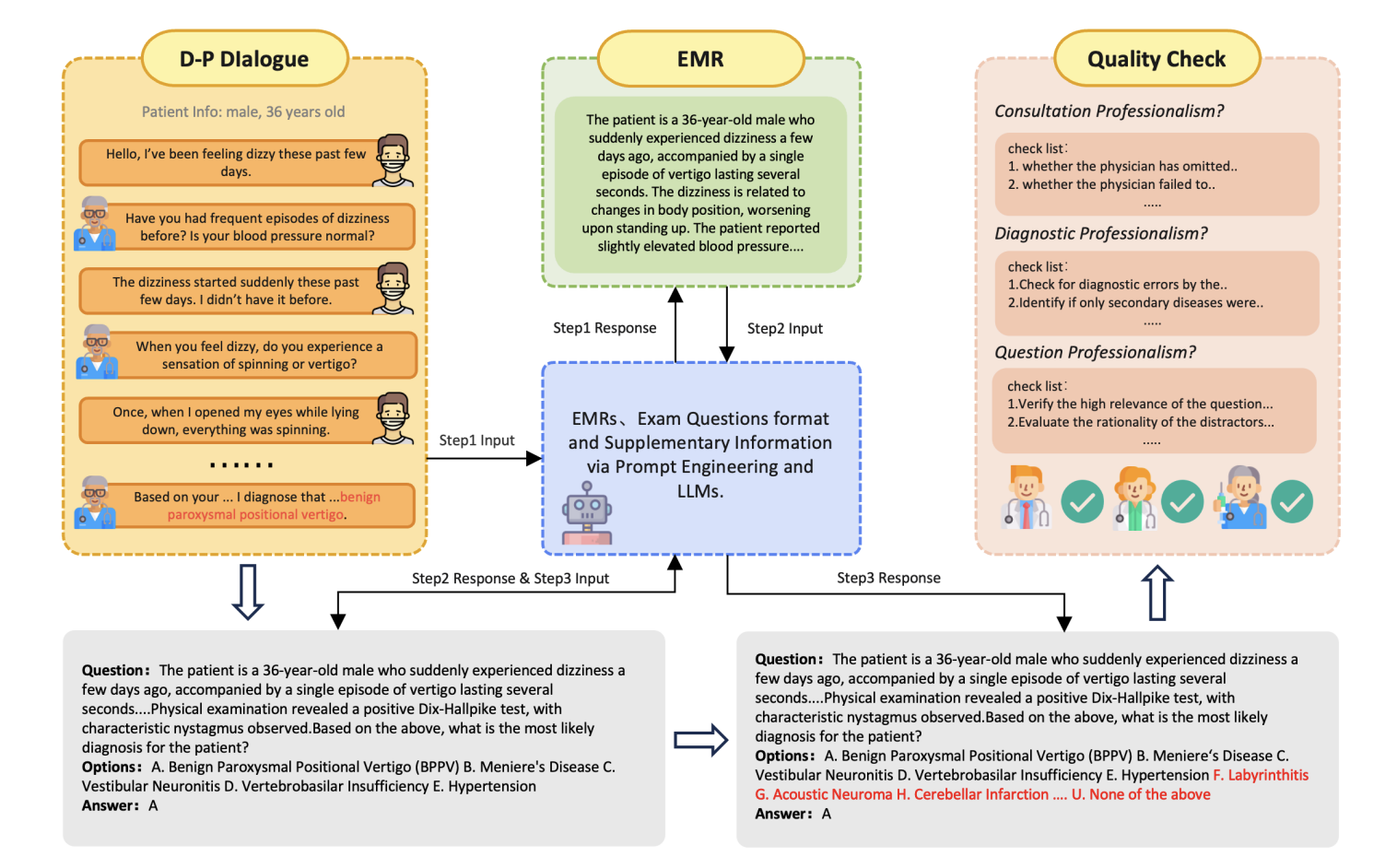
The JMED dataset is a new dataset based on the distribution of real-world medical data. It was built by the Citrus Team in 2025. The related paper results are "Citrus: Leveraging Expert Cognitive Pathways in a Medical Language Model for Advanced Medical Decision Support". The dataset is derived from anonymous doctor-patient conversations in JD Health Internet Hospital and is filtered to retain consultations that follow a standardized diagnostic workflow. The initial version contains 1k high-quality clinical records covering all age groups (0-90 years old) and multiple specialties. Each question includes 21 answer options, including one "none of the above" option. This design greatly increases the complexity and difficulty of distinguishing the correct answers, providing a more rigorous evaluation framework. Unlike existing datasets, JMED closely simulates real clinical data while facilitating effective model training. Although based on real consultation data, it does not come directly from actual medical data, so the research team can integrate the key elements required for model training. Compared with existing medical QA datasets, JMED has three main advantages: First, it more accurately reflects the ambiguity of patient symptom descriptions and the dynamic nature of clinical diagnosis in real scenarios. Second, the expanded answer options require enhanced reasoning capabilities to identify the correct answer among numerous interference factors. In addition, by leveraging a large amount of consultation data from JD.com's major hospitals, data that conforms to the distribution characteristics of real patients can be continuously generated.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.