Command Palette
Search for a command to run...
MedQA Medical Text Question Answering Dataset
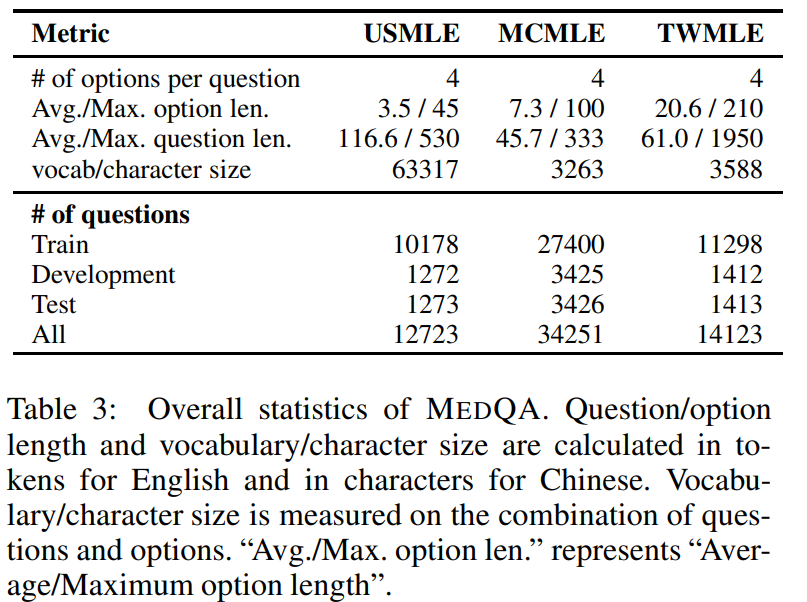
The MedQA dataset is a question-answering dataset for the medical field that simulates the style of the United States Medical Licensing Examination (USMLE). It was released by a research team from MIT and Huazhong University of Science and Technology in 2020. The related paper results are "What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams". The dataset is collected from professional medical examinations and covers English, Simplified Chinese, and Traditional Chinese, containing 12,723, 34,251, and 14,123 questions respectively, and is designed to evaluate the model's ability to understand and apply medical knowledge. . The MedQA dataset is constructed based on professional medical licensing exams, ensuring the high quality and professionalism of the questions. In addition to the question data, a large-scale medical textbook corpus is collected and released, from which the reading comprehension model can acquire the necessary knowledge to answer questions. The dataset is divided into training set, development set and test set, which are used for model training, verification and testing respectively.
Citation
@article{jin2020disease, title={What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams}, author={Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter}, journal={arXiv preprint arXiv:2009.13081}, year={2020} }
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.