Command Palette
Search for a command to run...
MMedC Large-Scale Multilingual Medical Corpus
Date
Size
Organization
Publish URL
Paper URL
License
CC BY-NC-SA 3.0
Tags
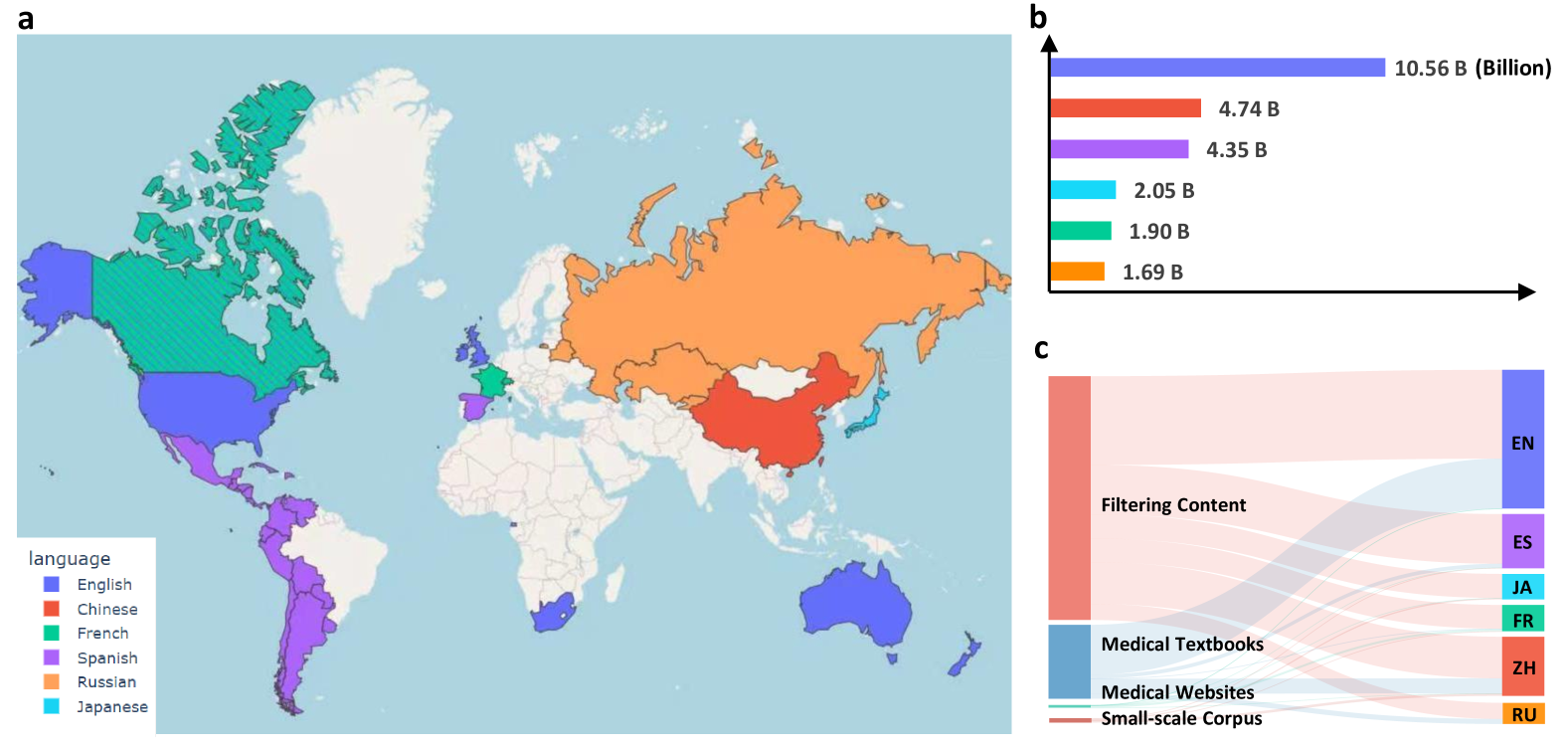
The Massive Multilingual Medical Corpus (MMedC) is a multilingual medical corpus built by the Smart Healthcare Team of the School of Artificial Intelligence of Shanghai Jiao Tong University in 2024. It contains about 25.5 billion tokens, covering 6 major languages: English, Chinese, Japanese, French, Russian and Spanish. This dataset was built to promote the development of multilingual medical language models. It covers most parts of the world, and support for more languages is still being updated and expanded. The related paper results are "Towards Building Multilingual Language Model for Medicine", published in Nature Communications. The data sources of MMedC mainly include four aspects: first, medical-related content is screened out from large-scale general text databases (such as CommonCrawl) through heuristic algorithms; second, text is extracted from medical textbooks using optical character recognition technology (OCR); third, data is crawled from officially licensed medical websites in many countries; finally, some existing small-scale medical data sets are integrated. In addition, in order to evaluate the development of multilingual models in the medical field, the research team also designed a new multilingual multiple-choice question-answering evaluation standard, named MMedBench. All questions in MMedBench are directly derived from medical examination question banks in various countries, rather than simply obtained through translation, avoiding diagnostic understanding biases caused by differences in medical practice guidelines in different countries. During the evaluation process, the model not only needs to choose the correct answer, but also must provide a reasonable explanation, thereby further testing the model's ability to understand and interpret complex medical information and achieve a more comprehensive evaluation. The research team also open-sourced the multilingual medical base model MMed-Llama 3, which performed well in multiple benchmarks, significantly surpassing existing open-source models and is particularly suitable for custom fine-tuning in the medical vertical. All data and code have been open-sourced, further promoting collaboration and technology sharing in the global research community. The construction and open source of MMedC provides rich and high-quality data support for the training and evaluation of multilingual medical language models, helps solve the problems of language barriers and globalization of medical resources, and demonstrates great potential for application in the medical field.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.