Command Palette
Search for a command to run...
ProtT3 Protein Text Question Answering Dataset
Date
Size
Organization
Publish URL
Paper URL
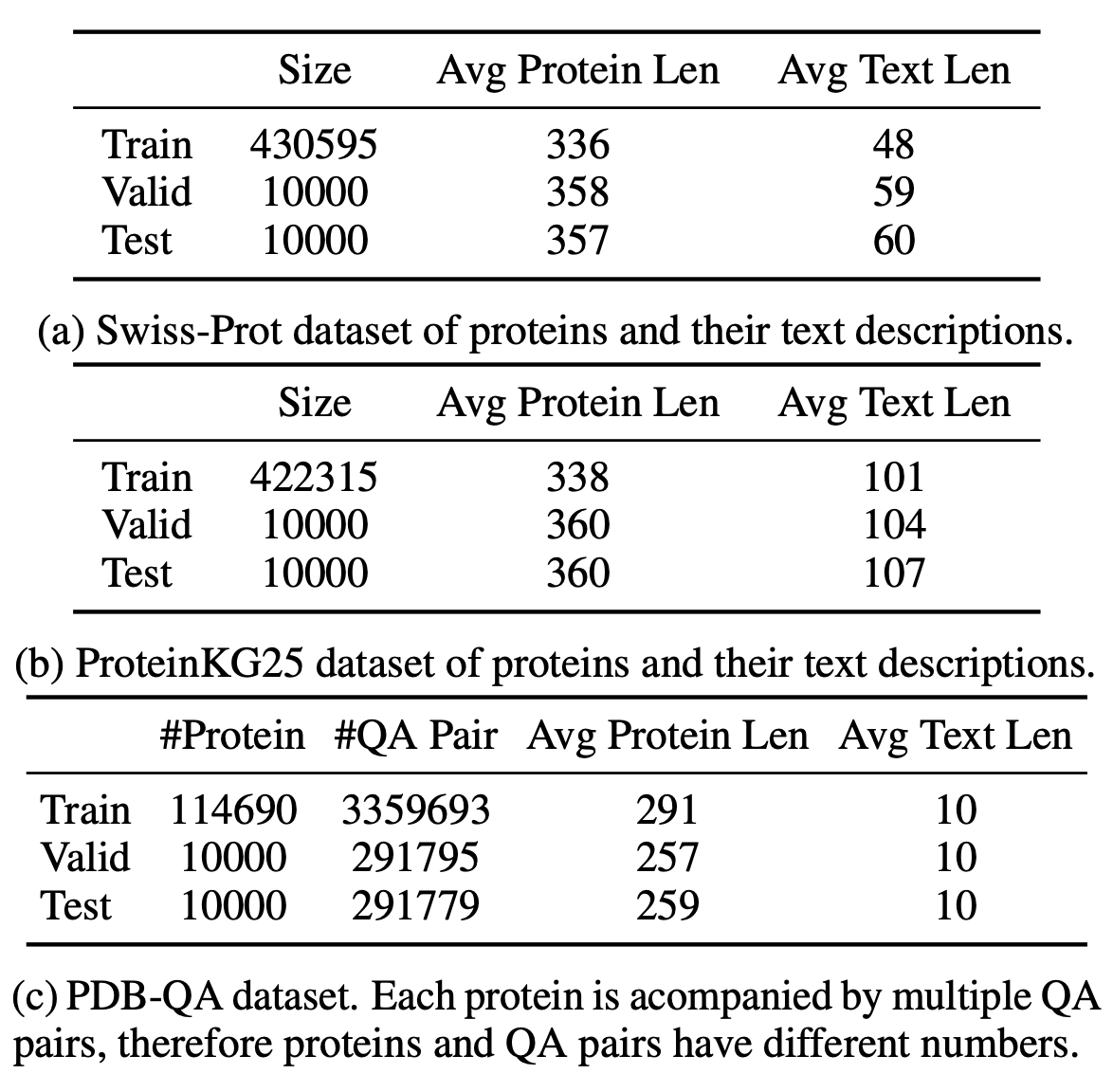
The ProtT3 dataset was jointly constructed by research teams from the National University of Singapore, the University of Science and Technology of China, and Hokkaido University in 2024.ProtT3: Protein-to-Text Generation for Text-based Protein Understanding", and has been selected for ACL 2024. This dataset is a pre-training dataset for the paper research. The ProtT3 dataset consists of three datasets: Swiss-Prot, ProteinKG25 and PDB-QA.

Citation
"`bib @inproceedings{liu2024prott, title={ProtT3: Protein-to-Text Generation for Text-based Protein Understanding}, author={Liu, Zhiyuan and Zhang, An and Fei, Hao and Zhang, Enzhi and Wang, Xiang and Kawaguchi, Kenji and Chua, Tat-Seng} booktitle={{ACL}}, publisher = {Association for Computational Linguistics}, year={2024}, url={https://openreview.net/forum?id=ZmIjOPil2b} }
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.