Command Palette
Search for a command to run...
OceanBench Oceanography Benchmark Evaluation Dataset
Date
Size
Organization
Publish URL
Paper URL
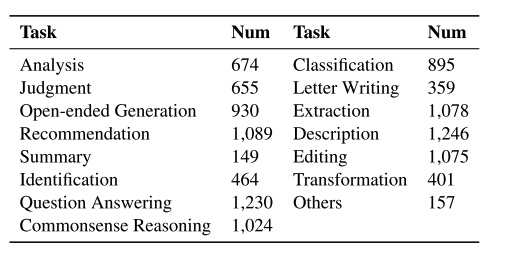
OceanBench is a benchmark evaluation dataset designed by the team of Ningyu Zhang and Huajun Chen from Zhejiang University in 2024. It is a dataset specifically designed for oceanographic tasks. This dataset includes 15 ocean-related tasks, such as question-answering and description tasks, and aims to comprehensively evaluate the capabilities of large language models (LLMs) in the field of oceanography. The samples in OceanBench are automatically generated from seed datasets and manually verified by experts to ensure the professionalism and accuracy of the data. OceanBench was created to promote the development of large-scale language models in the field of oceanography, provide a standardized testing platform, and help researchers better understand and improve the performance of models in ocean science tasks. Through this benchmark, researchers can evaluate the capabilities of models on different subtasks of ocean science, including but not limited to question answering and description generation tasks in the fields of ocean physics, marine chemistry, marine biology, geology, hydrology, etc. In addition, OceanBench also proposed OceanInstruct Ocean Large Model Instruction Dataset, which is a large language model instruction dataset designed specifically for the field of ocean science. It contains 20,000 instructions and is intended to provide training data for large language models in the ocean field. These instructions cover a wide range of ocean science knowledge, ensuring that the model has professional capabilities in ocean science question answering, content generation, and underwater embodied intelligence. This dataset was used to train the OceanGPT model, which performed well in ocean science question answering, content generation, and other aspects.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.