Command Palette
Search for a command to run...
VEGA Scientific Paper Graphics and Text Data Understanding Dataset
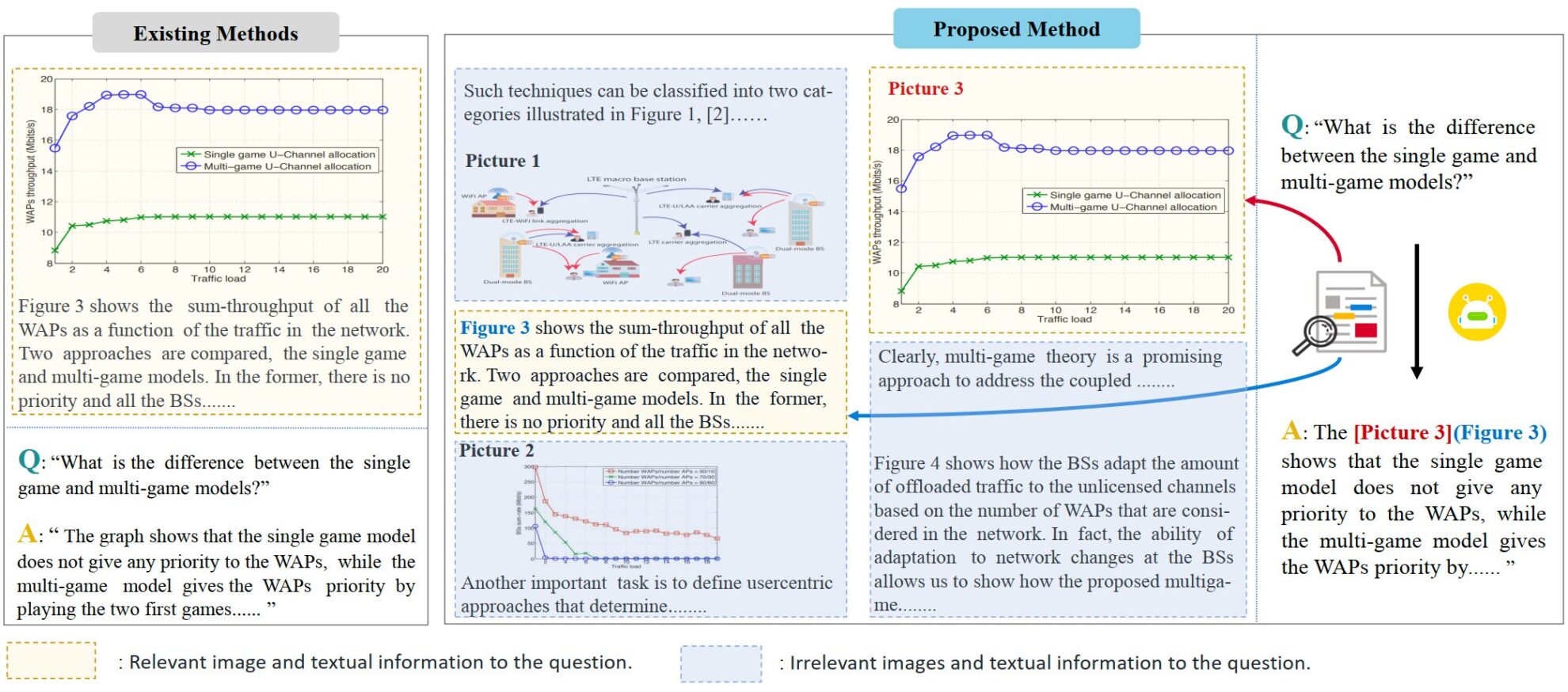
VEGA is a multimodal dataset focused on scientific paper understanding. It was proposed by Ji Rongrong's team at Xiamen University in 2024 and is designed to evaluate and improve the performance of models when processing inputs containing complex text and image information. The relevant paper is "VEGA: Learning Interleaved Image-Text Comprehension in Vision-Language Large ModelsThe dataset contains text and image data from more than 50,000 scientific papers and is specifically designed for the Interleaved Image-Text Comprehension (IITC) task. The construction process of the VEGA dataset includes three steps: question screening, context construction, and answer modification. It aims to provide longer and more complex interleaved text and image content as input and requires the model to specify the reference image when answering. VEGA is derived from the SciGraphQA dataset, which is a dataset for paper image understanding tasks and contains 295k question-answer pairs. The research team performed three steps on question screening, context construction, and answer modification to obtain the VEGA dataset. It contains 593,000 paper-type training data and 2,326 test data from 2 different tasks. It aims to provide longer and more complex text-image interlaced content as input and requires the model to specify the referenced image when answering.
- Question screening: Some questions in the original data set lack clear picture references, which will cause confusion when the input information is expanded to multiple pictures.
- Context construction: The original data set only has one question and answer for one image, and provides little context information. In order to expand the amount of text and images, the research team downloaded the source files of relevant papers on arxiv and constructed data with two lengths of 4k tokens and 8k tokens. Each question and answer pair contains at most 8 images.
- Answer modification: The author modified the answers in the original dataset and indicated the images referenced when answering to meet the requirements of the IITC task.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.