Command Palette
Search for a command to run...
MMDU Very Long multi-image multi-turn Dialogue Understanding Dataset
Date
Size
Organization
Publish URL
Paper URL
License
CC BY-NC-SA 3.0
Tags
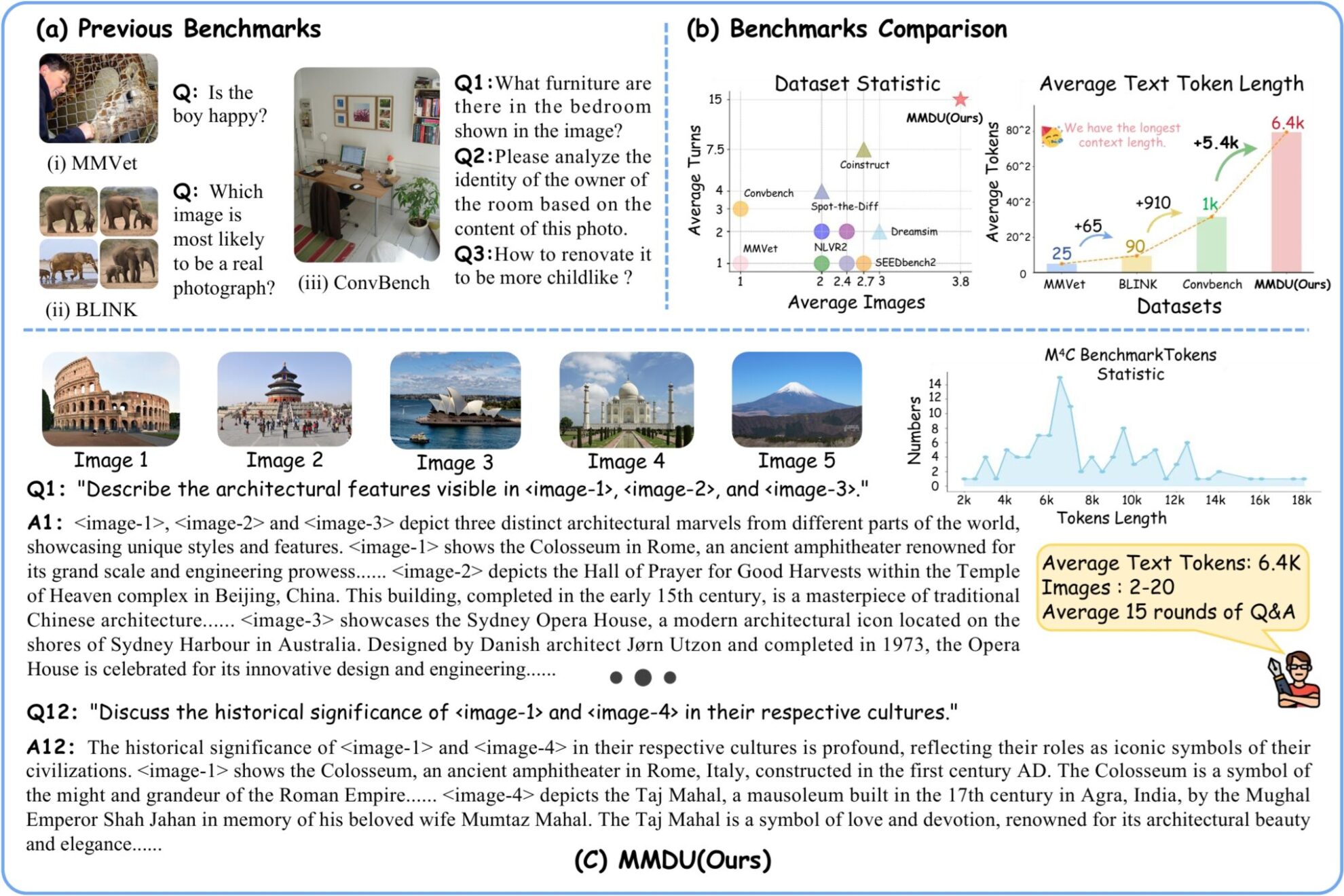
MMDU (Multi-Turn Multi-Image Dialog Understanding) is a very long multi-image multi-turn dialogue understanding dataset jointly launched by Wuhan University, Shanghai Artificial Intelligence Laboratory, Chinese University of Hong Kong and Moore Threads in 2024.MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs"A new multi-image multi-round evaluation benchmark MMDU and a large-scale instruction fine-tuning dataset MMDU-45k are proposed in the paper, aiming to evaluate and improve the performance of LVLMs in multi-round and multi-image conversations. The benchmark consists of 110 high-quality multi-image multi-turn dialogues with more than 1,600 questions, each with detailed long answers. Previous benchmarks usually involve only a single image or a small number of images, with fewer question turns and short answers. However, MMDU significantly increases the number of images, question and answer turns, and the context length of questions and answers. Questions in MMUD involve 2 to 20 images, with an average image and text token length of 8.2k tokens and a maximum image and text length of 18K tokens, posing a significant challenge to existing multimodal large-scale models. In MMDU-45k, the research team constructed a total of 45k instruction tuning data dialogues. Each piece of data in the MMDU-45k dataset has an ultra-long context, with an average image-text token length of 5k and a maximum image-text token length of 17k. Each dialogue contains an average of 9 rounds of questions and answers, and a maximum of 27 rounds. In addition, each piece of data contains the content of 2-5 pictures. The construction format of this dataset is carefully designed with excellent scalability, and can generate more and longer multi-image multi-round dialogues through combination. The length of images and the number of rounds in MMDU-45k significantly surpass all existing instruction tuning datasets. This enhancement greatly improves the model's ability to recognize and understand multiple images, as well as its ability to handle long context dialogues. The MMDU benchmark has the following advantages: **(1) Multi-round dialogue and multi-image input:**The MMDU benchmark consists of up to 20 images and 27 rounds of question-answering dialogues, surpassing multiple previous benchmarks and realistically replicating real-world chat interaction scenarios. **(2) Long context:**The MMDU benchmark evaluates the ability of LVLMs to process and understand contextual information with long context histories through up to 18k text+image tokens. **(3) Open evaluation:**MMDU breaks away from the close-ended questions and short outputs (e.g., multiple-choice questions or short answers) that traditional benchmarks rely on, and adopts a more realistic and refined evaluation approach. It evaluates the performance of LVLM through free-form multi-round outputs, emphasizing the scalability and interpretability of the evaluation results. In the process of building MMDU, researchers selected highly relevant images and text information from the open source Wikipedia, and with the assistance of the GPT-4o model, human annotators constructed question and answer pairs.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.