Command Palette
Search for a command to run...
GITQA Multimodal Graph Reasoning Question Answering Dataset
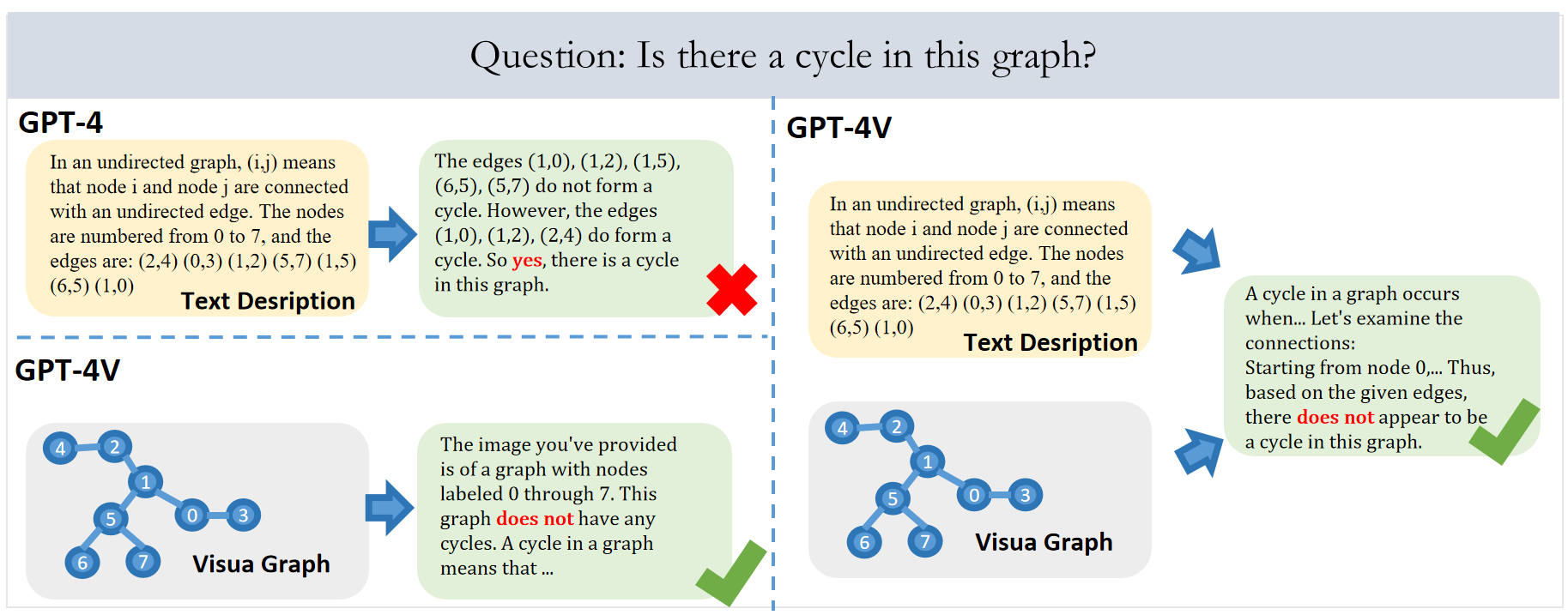
GITQA is the first reasoning question-answering dataset containing visual graphs, constructed by the Hong Kong University of Science and Technology and the Southern University of Science and Technology by drawing graph structures into visual images of different styles. The dataset contains more than 423K question-answering instances, each of which contains corresponding graph structure-text-visual information and its corresponding question-answer pair. The dataset contains two versions: GITQA-Base and GITQA-Aug. GITQA-Base only contains visual graphs of a single style. GITQA-Aug is richer, and it performs a variety of data enhancements on the visual graph, including changing the layout, the shape of the points, the width of the edges, and the style of the points, thereby providing a more diverse visual graph representation. This dataset can be used to evaluate the performance of text-based LLM and multimodal-based MLLM on graph reasoning tasks, and to study the impact of visual information on graph reasoning.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.