Command Palette
Search for a command to run...
Gradientenakkumulation
Datum
Tags
Bei der Gradientenakkumulation handelt es sich um einen Mechanismus zum Aufteilen einer Gruppe von Proben, die zum Trainieren eines neuronalen Netzwerks verwendet wird, in mehrere kleine Gruppen von Proben, die nacheinander ausgeführt werden.
Bevor wir die Gradientenakkumulation weiter diskutieren, ist es gut, den Backpropagation-Prozess eines neuronalen Netzwerks zu überprüfen.
Backpropagation neuronaler Netze
Deep-Learning-Modelle bestehen aus vielen miteinander verbundenen Schichten, in denen die Proben bei jedem Schritt durch Vorwärtsausbreitung weitergegeben werden. Nach der Ausbreitung durch alle Schichten generiert das Netzwerk Vorhersagen für die Stichproben und berechnet dann für jede Stichprobe einen Verlustwert, der angibt, „wie falsch das Netzwerk in Bezug auf diese Stichprobe lag“. Das neuronale Netzwerk berechnet dann die Gradienten dieser Verlustwerte in Bezug auf die Modellparameter. Diese Gradienten werden verwendet, um Aktualisierungen für die verschiedenen Variablen zu berechnen.
Beim Erstellen eines Modells wählen Sie einen Optimierer aus, der für den Algorithmus zur Minimierung des Verlusts verantwortlich ist. Der Optimierer kann einer der im Framework implementierten allgemeinen Optimierer (SGD, Adam usw.) oder ein benutzerdefinierter Optimierer sein, der den gewünschten Algorithmus implementiert. Neben Gradienten kann der Optimierer auch viele weitere Parameter verwalten und verwenden, um Aktualisierungen zu berechnen, wie z. B. Lernrate, aktueller Schrittindex (für adaptive Lernrate), Momentum usw.
Gradientenakkumulation der Technologie
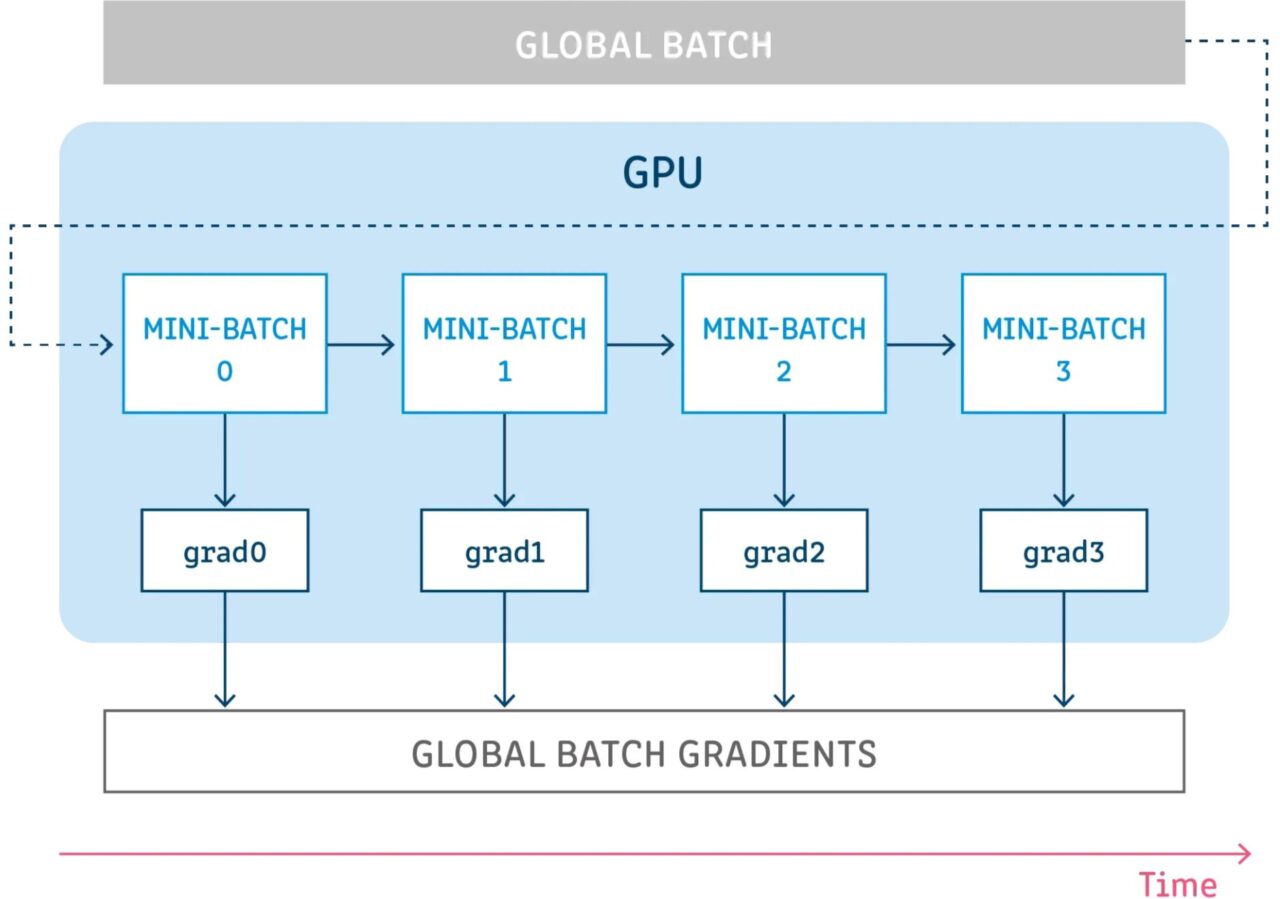
Bei der Gradientenakkumulation wird eine Konfiguration für eine bestimmte Anzahl von Schritten ausgeführt, ohne die Modellvariablen zu aktualisieren, während die Gradienten in diesen Schritten akkumuliert werden, und anschließend werden die akkumulierten Gradienten zum Berechnen der Variablenaktualisierungen verwendet.
Durch Ausführen einiger Schritte ohne Aktualisierung von Modellvariablen können Sie den Probenstapel logisch in mehrere kleinere Stapel aufteilen. Der in jedem Schritt verwendete Stapel von Proben ist eigentlich ein Mini-Stapel, während die Kombination der Proben aus allen diesen Schritten eigentlich den globalen Stapel bildet.
Indem die Variablen in all diesen Schritten nicht aktualisiert werden, verwenden alle Mini-Batches dieselben Modellvariablen zum Berechnen von Gradienten. Dies ist ein obligatorisches Verhalten, um sicherzustellen, dass dieselben Gradienten und Aktualisierungen berechnet werden, als ob die globale Batchgröße verwendet würde.
Das Akkumulieren der Gradienten in allen diesen Schritten ergibt die gleiche Summe der Gradienten.
Verweise
【1】https://towardsdatascience.com/was-ist-gradientenakkumulation-beim-deep-learning-ec034122cfa
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.