Command Palette
Search for a command to run...
POINTS-Reader: Ein Leichtes Dokument-Vision-Sprachmodell Mit Durchgängiger Destillationsfreier Architektur
Datum
Größe
1.2 GB
Lizenz
Other
GitHub
Paper-URL
1. Einführung in das Tutorial

POINTS-Reader ist ein schlankes visuelles Sprachmodell (VLM), das im August 2025 von Tencent, der Shanghai Jiao Tong University und der Tsinghua University gemeinsam entwickelt wurde und speziell für die Umwandlung von Dokumentenbildern in Text konzipiert ist. POINTS-Reader verzichtet auf eine hohe Anzahl an Parametern und die „Destillation“ von Lehrermodellen. Stattdessen nutzt es ein zweistufiges, selbstlernendes Framework, um eine hochpräzise End-to-End-Erkennung komplexer chinesischer und englischer Dokumente (einschließlich Tabellen, Formeln und mehrspaltiger Layouts) bei gleichzeitig minimalistischer Struktur zu erreichen. Zugehörige Forschungsarbeiten sind verfügbar. POINTS-Reader: Destillationsfreie Anpassung von Vision-Language-Modellen für die Dokumentkonvertierung Es wurde von EMNLP 2025 angenommen und wird auf der Hauptkonferenz präsentiert.
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte.
2. Effektanzeige
Einzelsäule mit Latexformel

Einzelne Spalte mit Tabelle
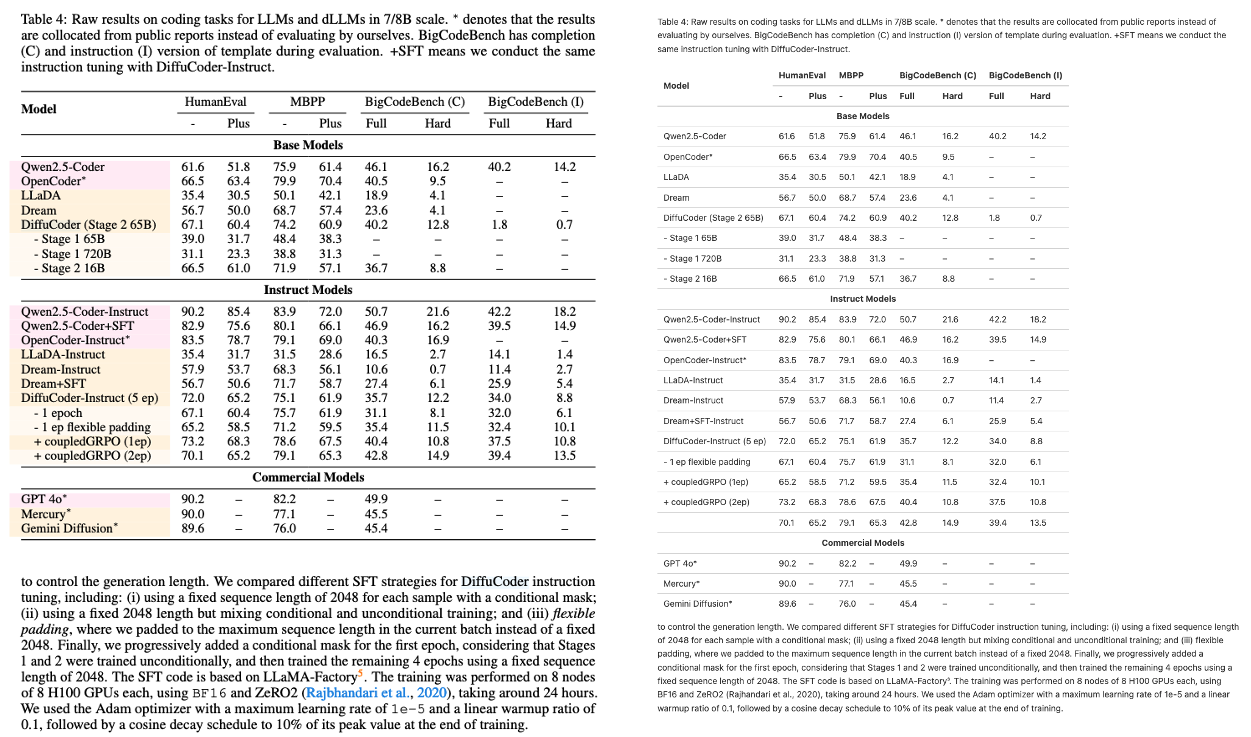
Mehrspaltig mit Latex-Formel

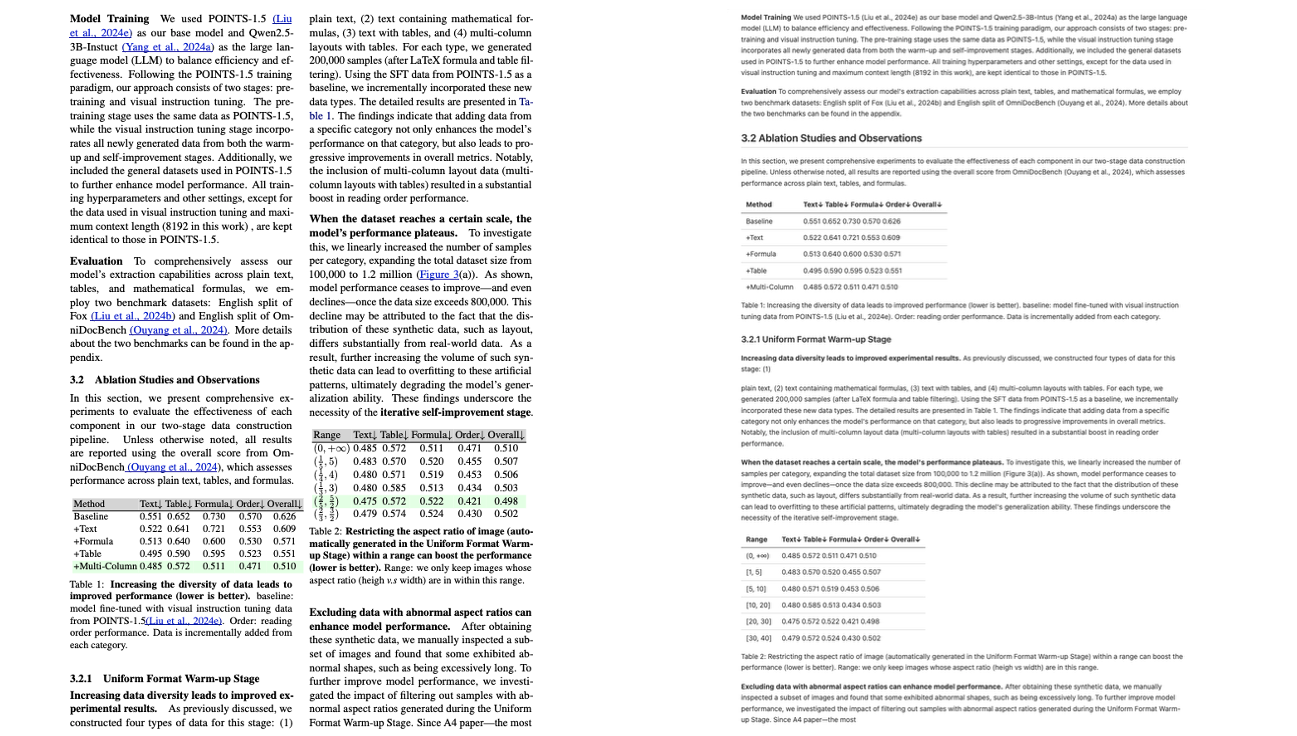
Mehrspaltig mit Tabelle
3. Bedienungsschritte
1. Starten Sie den Container
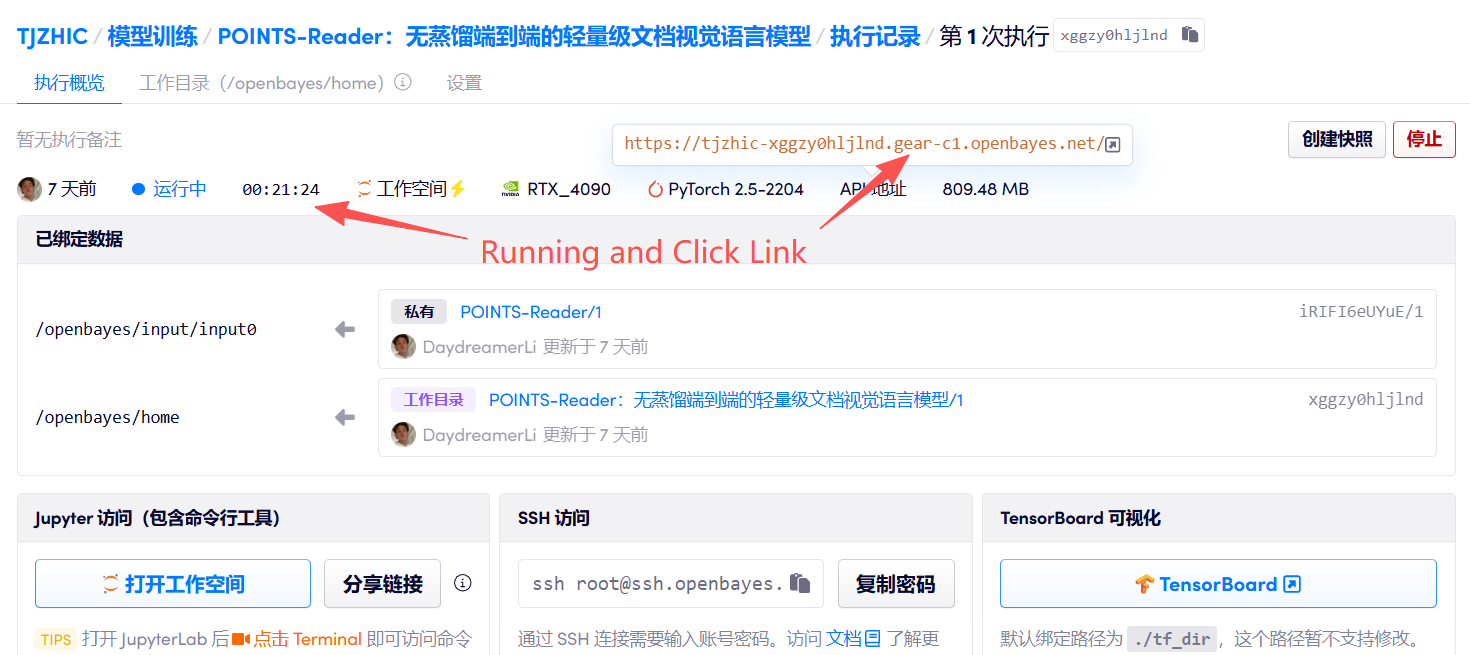
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
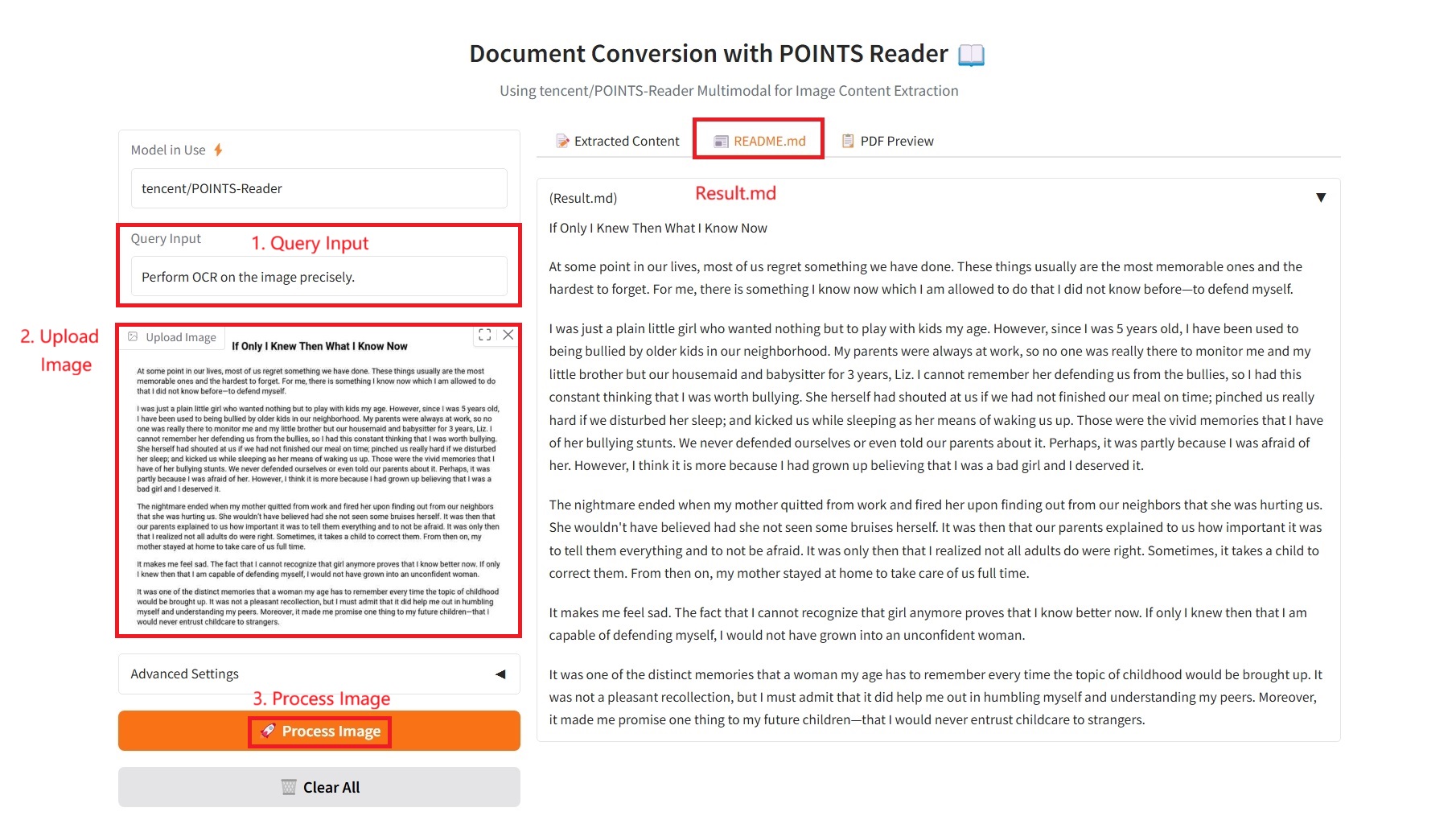
1. Extrahierter Inhalt
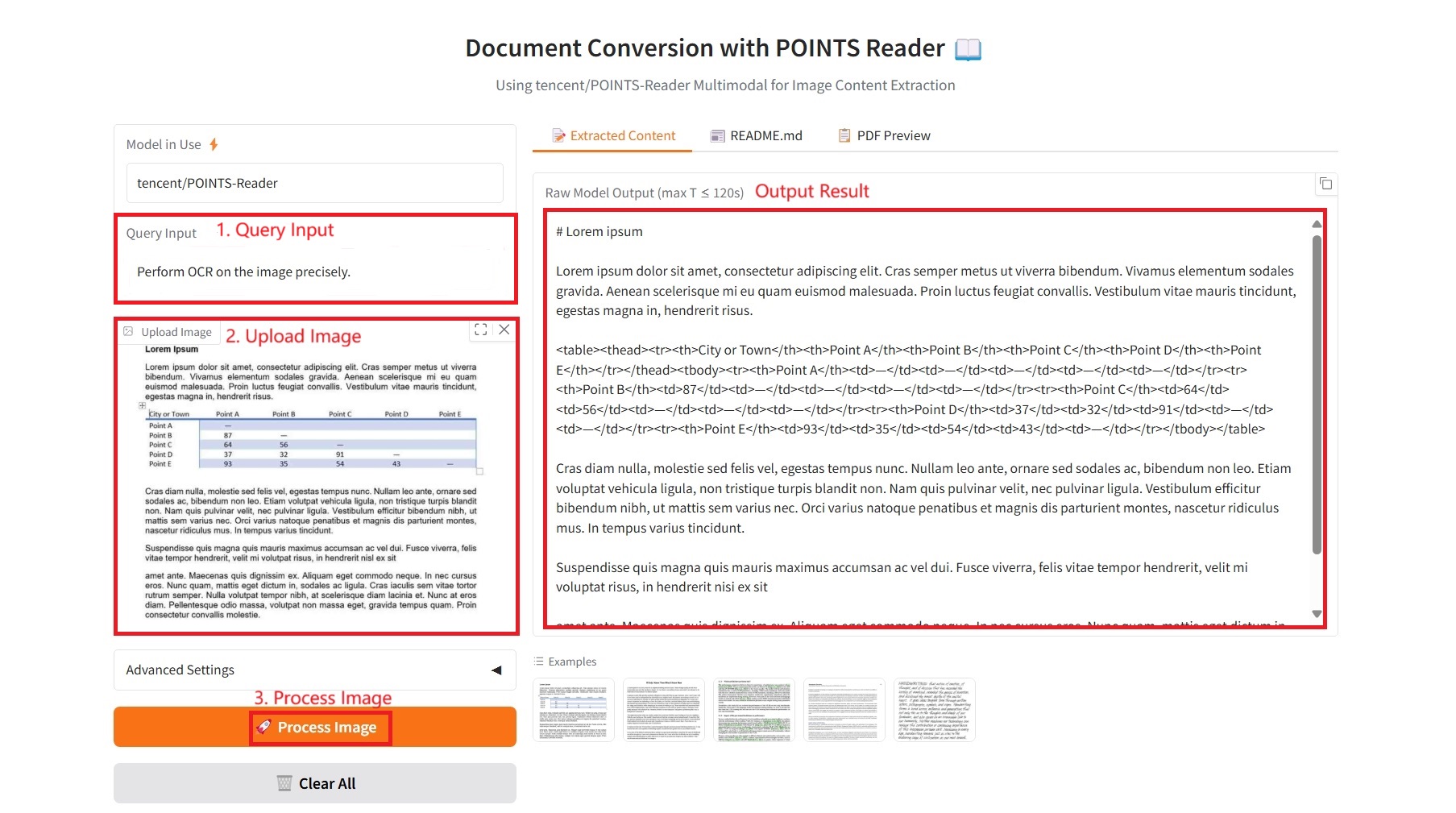
Spezifische Parameter:
- Abfrageeingabe: Geben Sie Textanforderungen ein.
- Bild-Upscale-Faktor: Erhöht die Bildgröße vor der Verarbeitung. Kann die OCR von kleinem Text verbessern. Standard: 1,0 (keine Änderung).
- Max. neue Token: Die maximale Längenbeschränkung des generierten Textes, die die Obergrenze der Wortanzahl im Ausgabeinhalt steuert.
- Top-p (Nukleus-Sampling): Ein Nukleus-Sampling-Parameter, der den minimalen Wortsatz mit einer kumulativen Wahrscheinlichkeit von p für das Sampling auswählt, um die Ausgabediversität zu steuern.
- Top-k: Stichprobe aus den k Kandidatenwörtern mit der höchsten Wahrscheinlichkeit. Je größer der Wert, desto zufälliger die Ausgabe; je kleiner der Wert, desto sicherer die Ausgabe.
- Temperatur: Steuert die Zufälligkeit des generierten Textes. Höhere Werte führen zu einer zufälligeren und vielfältigeren Ausgabe, während niedrigere Werte zu einer deterministischeren und konservativeren Ausgabe führen.
- Wiederholungsstrafe: Ein Wert größer als 1,0 reduziert die Generierung doppelter Inhalte. Je höher der Wert, desto stärker die Strafe.
- PDF-Exporteinstellungen:
- Schriftgröße: Die Schriftgröße des Textes im PDF, die die Lesbarkeit des exportierten Dokuments steuert.
- Zeilenabstand: Der Zeilenabstand zwischen Absätzen in einer PDF-Datei wirkt sich auf die Ästhetik und Lesbarkeit des Dokuments aus.
- Textausrichtung: Die Ausrichtung des Textes in PDF, einschließlich Linksbündig, zentriert, rechtsbündig oder Blocksatz.
- Bildgröße im PDF: Die Größe des im PDF eingebetteten Bildes, einschließlich der Optionen klein, mittel und groß.
2. README.md
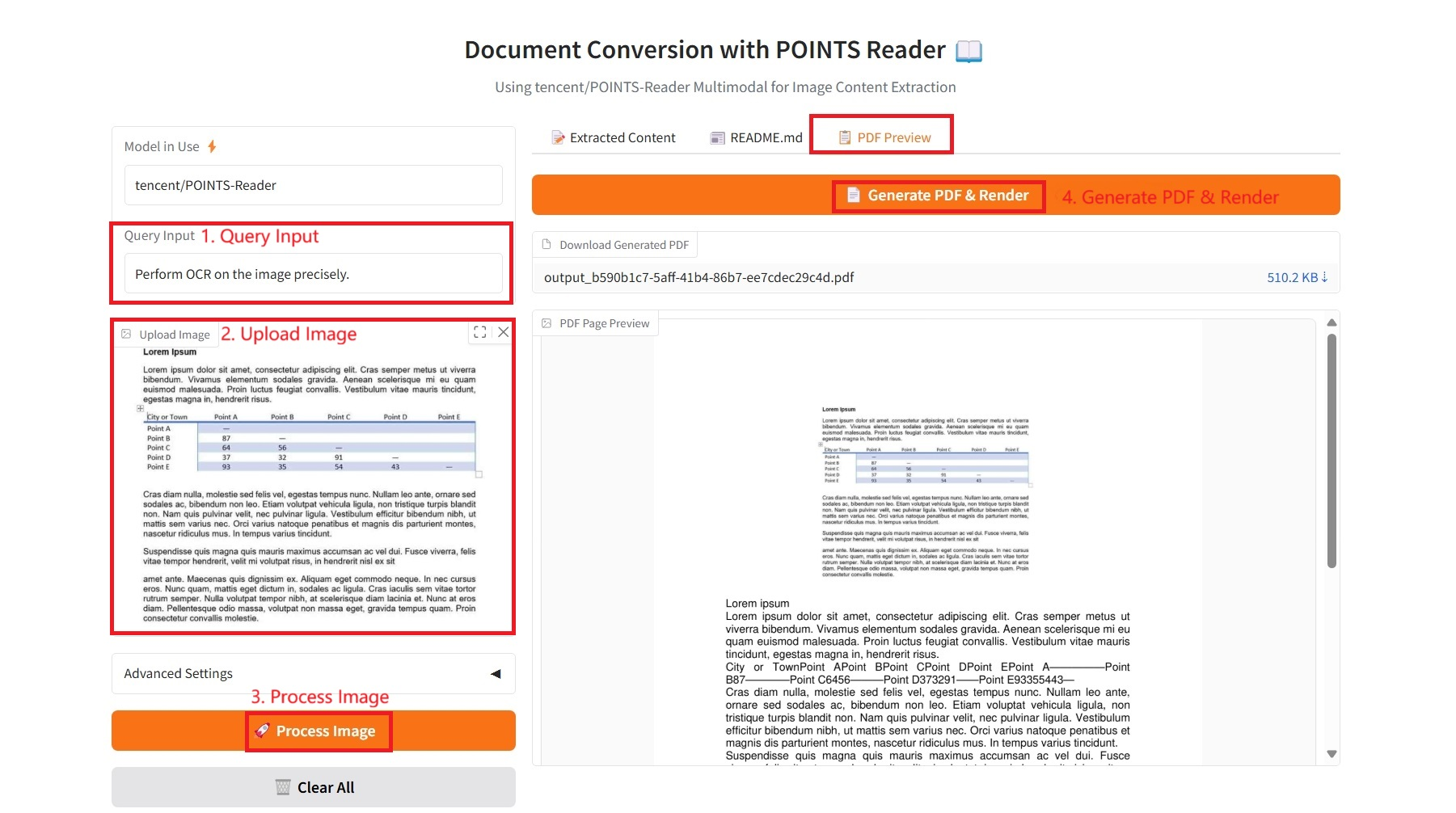
3. PDF-Vorschau
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{points-reader, title={POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion}, author={Liu, Yuan and Zhongyin Zhao and Tian, Le and Haicheng Wang and Xubing Ye and Yangxiu You and Zilin Yu and Chuhan Wu and Zhou, Xiao and Yu, Yang and Zhou, Jie}, journal={EMNLP2025}, year={2025} } @article{liu2024points1,
title={POINTS1. 5: Building a Vision-Language Model towards Real World Applications},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Gao, Xinyu and Yu, Kavio and Yu, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2412.08443},
year={2024}
} @article{liu2024points,
title={POINTS: Improving Your Vision-language Model with Affordable Strategies},
author={Liu, Yuan and Zhao, Zhongyin and Zhuang, Ziyuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2409.04828},
year={2024}
}@article{liu2024rethinking,
title={Rethinking Overlooked Aspects in Vision-Language Models},
author={Liu, Yuan and Tian, Le and Zhou, Xiao and Zhou, Jie},
journal={arXiv preprint arXiv:2405.11850},
year={2024}
}
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.