Command Palette
Search for a command to run...
IndexTTS-2: Die Engpässe Der Autoregressiven TTS-Dauer Und Emotionskontrolle Überwinden
Datum
Größe
111.82 MB
Tags
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

IndexTTS-2 ist ein neuartiges Text-to-Speech-Modell (TTS), das im Juni 2025 vom Bilibili Voice Team als Open Source veröffentlicht wurde. Das Modell erzielt bedeutende Fortschritte in der Emotionsdarstellung und der Dauersteuerung und ist das erste autoregressive TTS-Modell, das eine präzise Dauersteuerung ermöglicht. Es unterstützt Zero-Sample Voice Cloning, wodurch Klangfarbe, Rhythmus und Sprechstil aus einer einzigen Audiodatei exakt repliziert werden, und unterstützt mehrere Sprachen. IndexTTS-2 implementiert eine Emotions-Klangfarben-Trennung, sodass Benutzer Klangfarbe und Emotionsquellen unabhängig voneinander festlegen können. Das Modell bietet multimodale Eingabemöglichkeiten für Emotionen und unterstützt die Emotionssteuerung durch Referenzaudio, beschreibenden Text oder Emotionsvektoren. Zugehörige Forschungsarbeiten sind verfügbar. IndexTTS2: Ein Durchbruch in der emotional ausdrucksstarken und dauerkontrollierten autoregressiven Zero-Shot-Text-to-Speech .
Dieses Tutorial verwendet eine einzelne RTX 5090-Grafikkarte als Rechenressource.
2. Effektanzeige
Dasselbe wie die Sprachreferenz
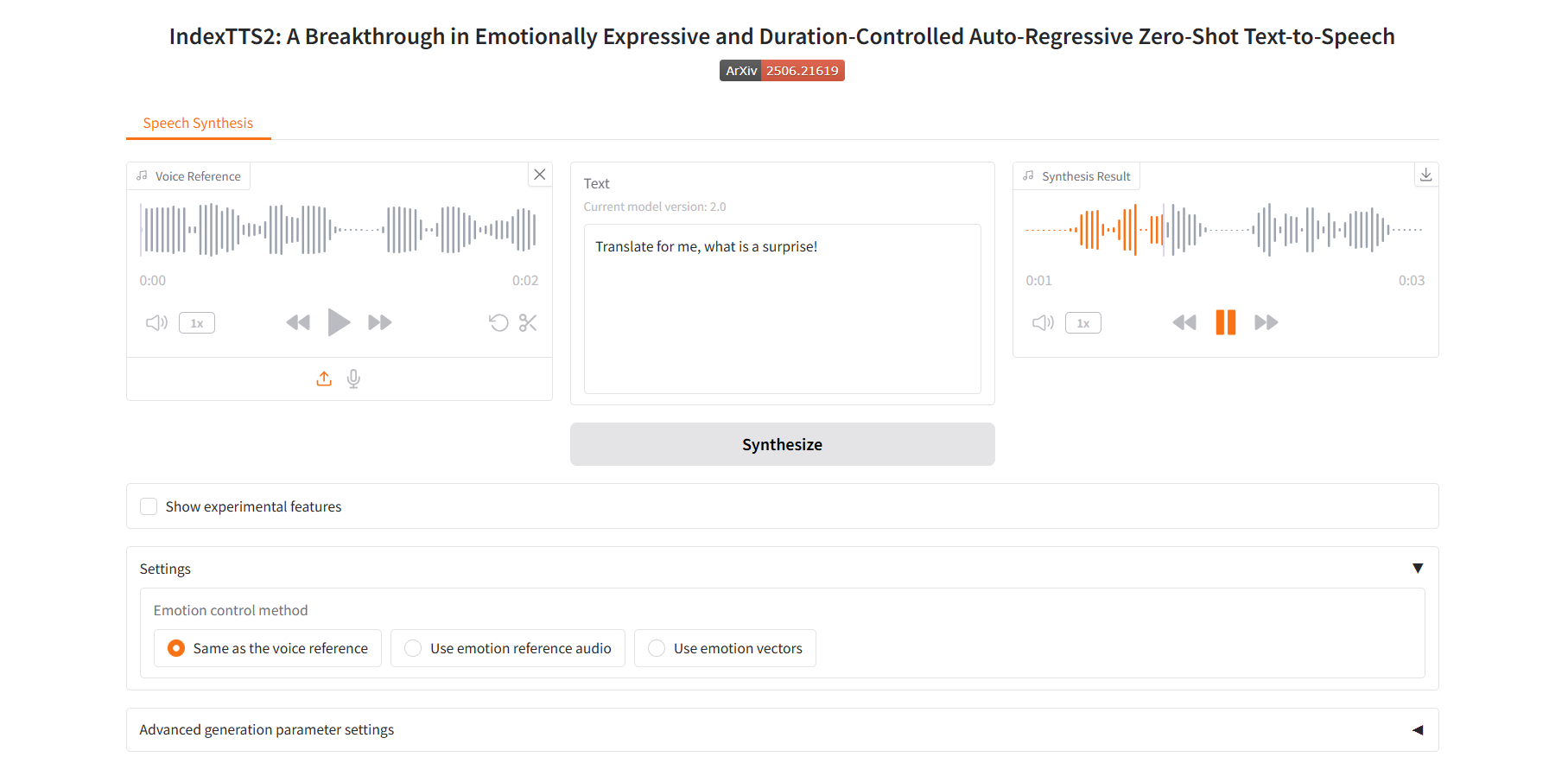
Verwenden Sie Audio mit Emotionsreferenzen
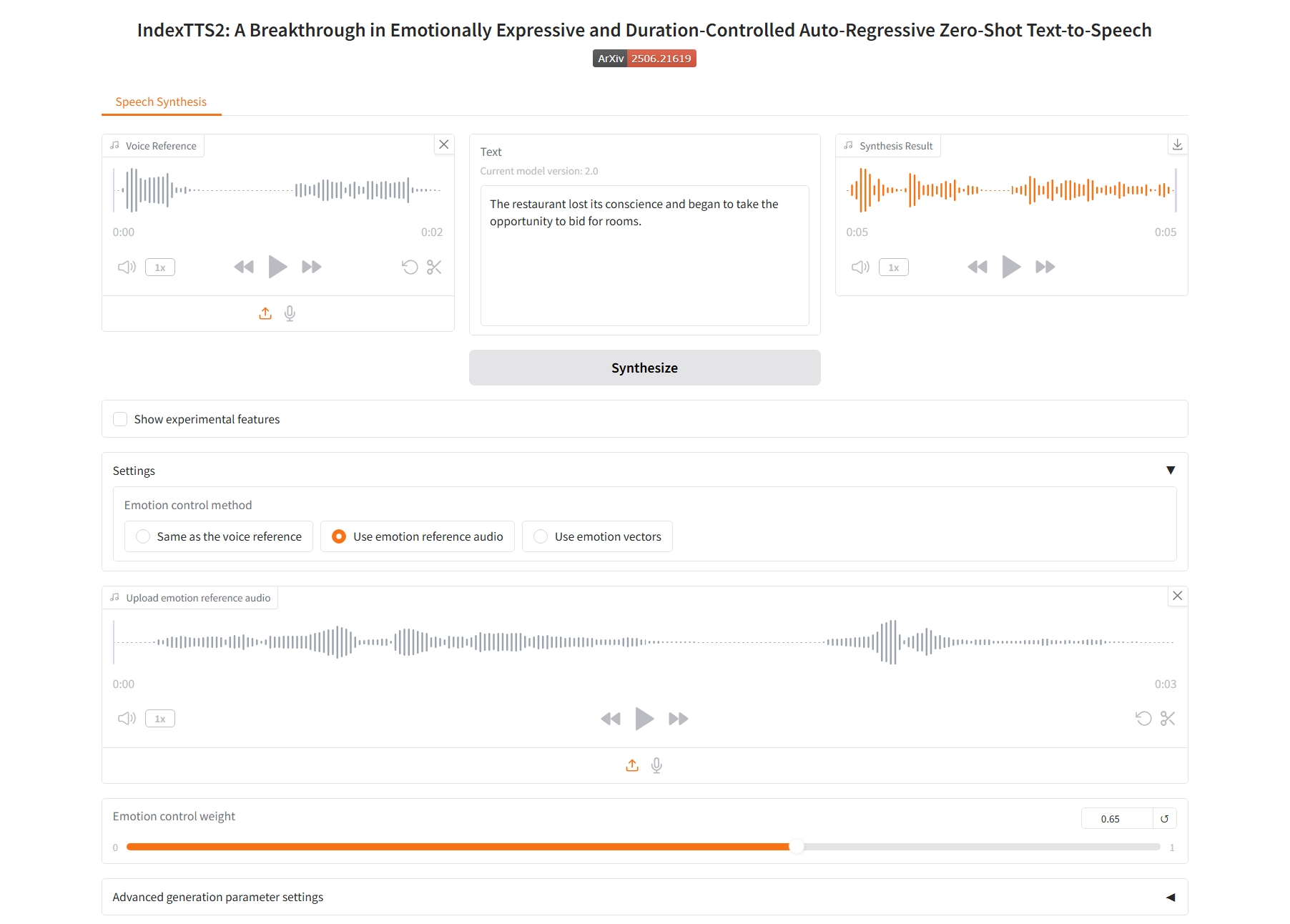
Verwenden Sie Emotionsvektoren
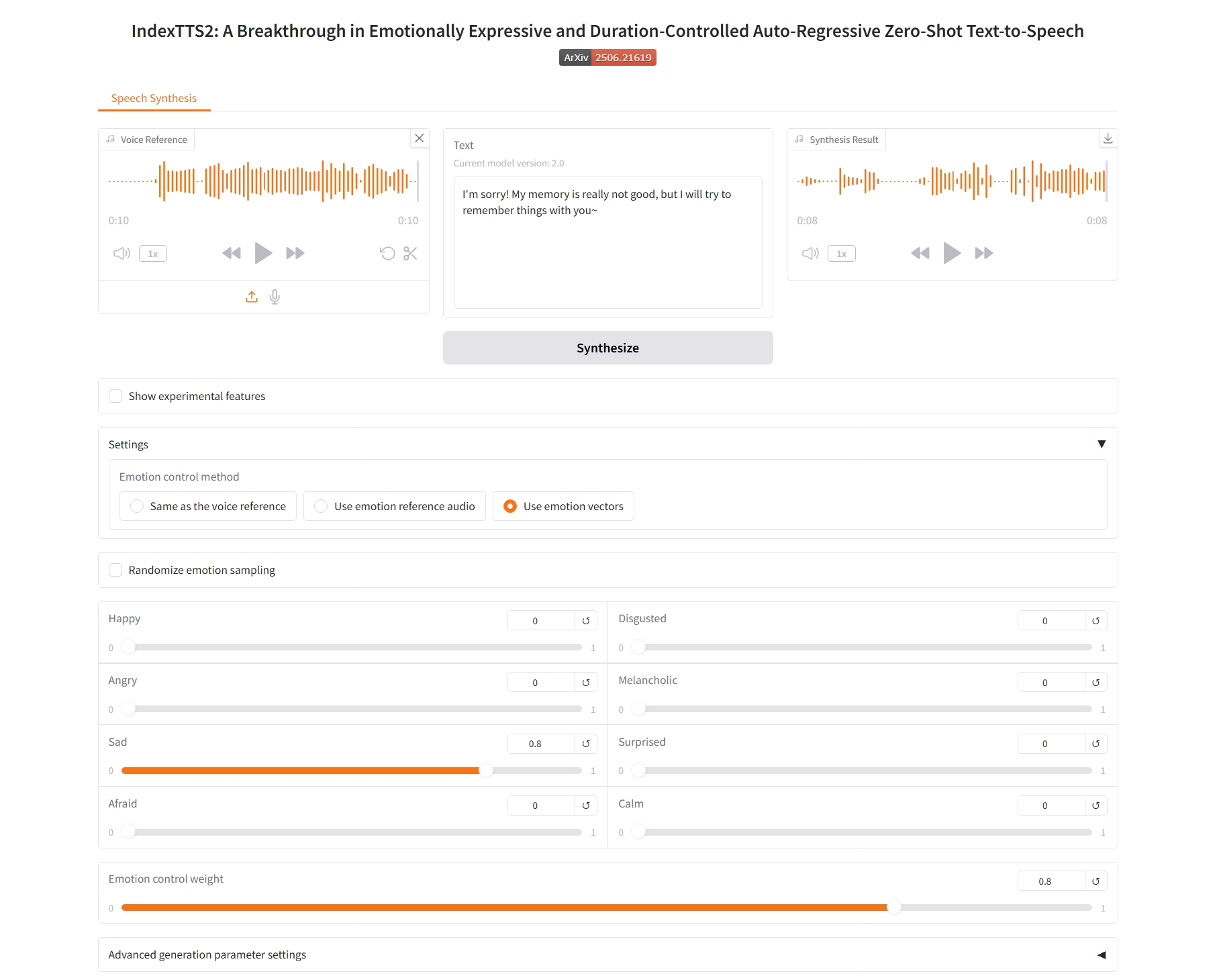
Verwenden Sie Textbeschreibungen, um Emotionen zu steuern
3. Bedienungsschritte
1. Starten Sie den Container
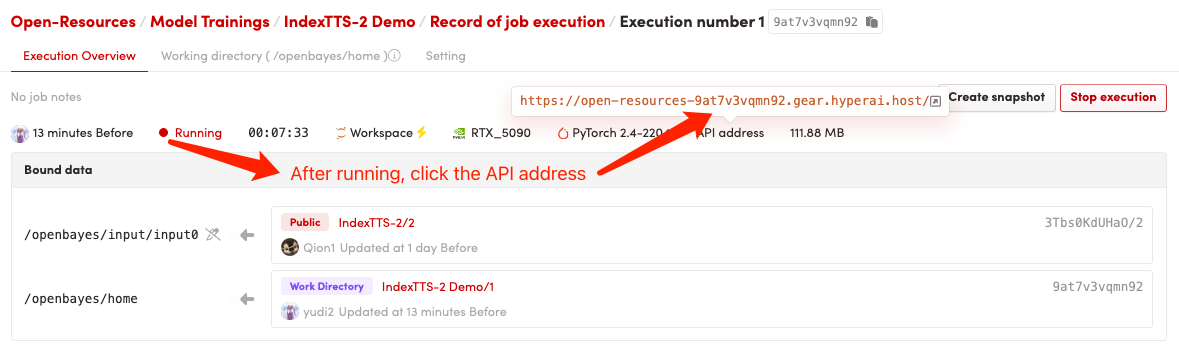
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
1. Gleich wie die Sprachreferenz

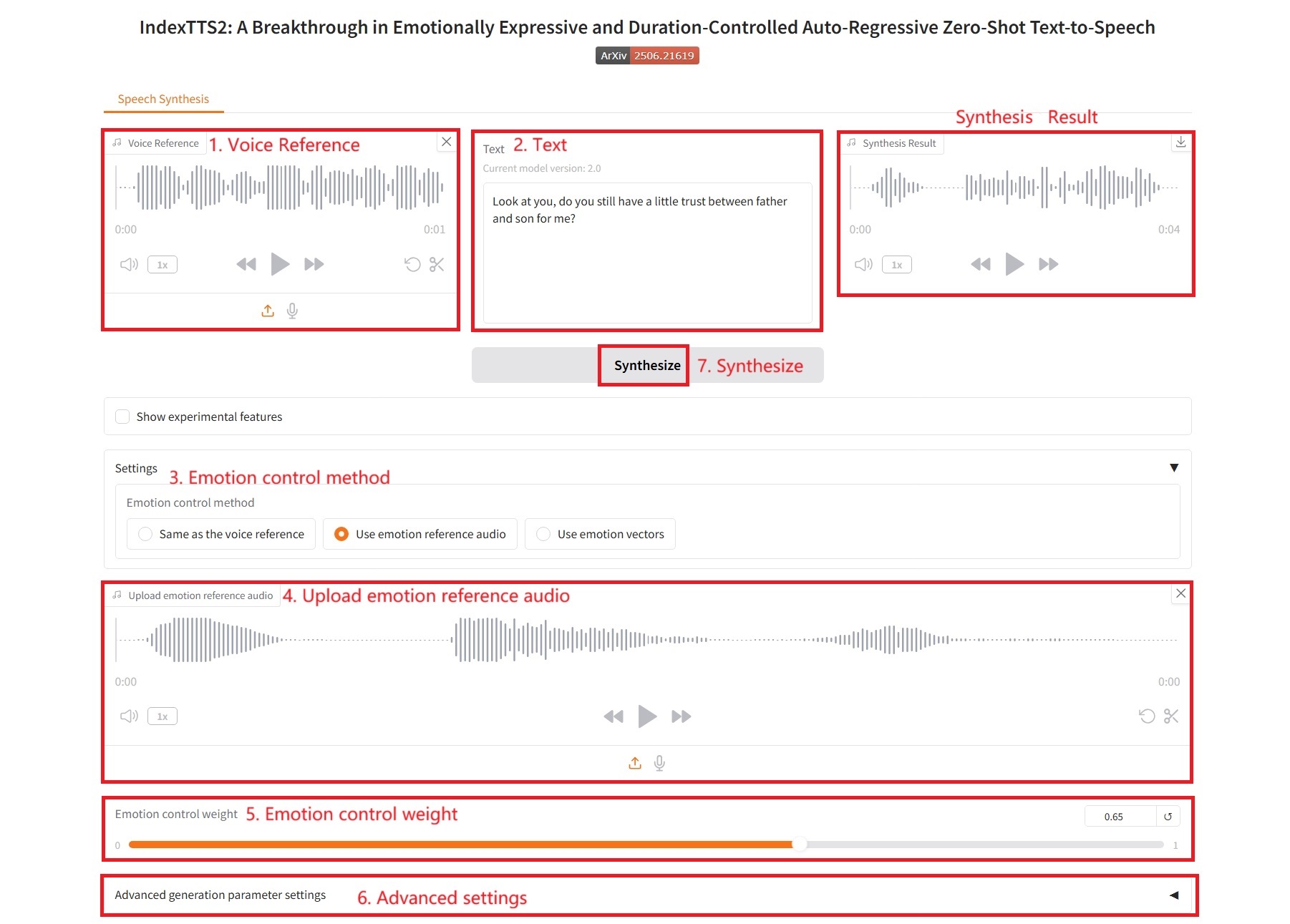
Spezifische Parameter:
- Erweiterte Parametereinstellungen:
- do_sample: ob eine Stichprobennahme durchgeführt werden soll.
- Temperatur: steuert die Glätte der Wahrscheinlichkeitsverteilung während der Stichprobennahme.
- top_p: Kernel-Sampling.
- top_k: Bei jedem Generierungsschritt werden nur die K Token mit der höchsten Wahrscheinlichkeit berücksichtigt.
- num_beams: Strahlsuchbreite.
- repetition_penalty: Wiederholungsstrafe, die die Wahrscheinlichkeit verringert, dass das Modell wiederholt dasselbe Token generiert.
- length_penalty: Längenstrafe, die das Modell dazu ermutigt oder davon abhält, längere oder kürzere Sequenzen zu generieren. Dies ist hauptsächlich dann effektiv, wenn num_beams > 1 verwendet wird.
- max_mel_tokens: Die maximale Anzahl generierter Token.
2. Verwenden Sie Audio mit Emotionsreferenz
3. Verwenden Sie Emotionsvektoren
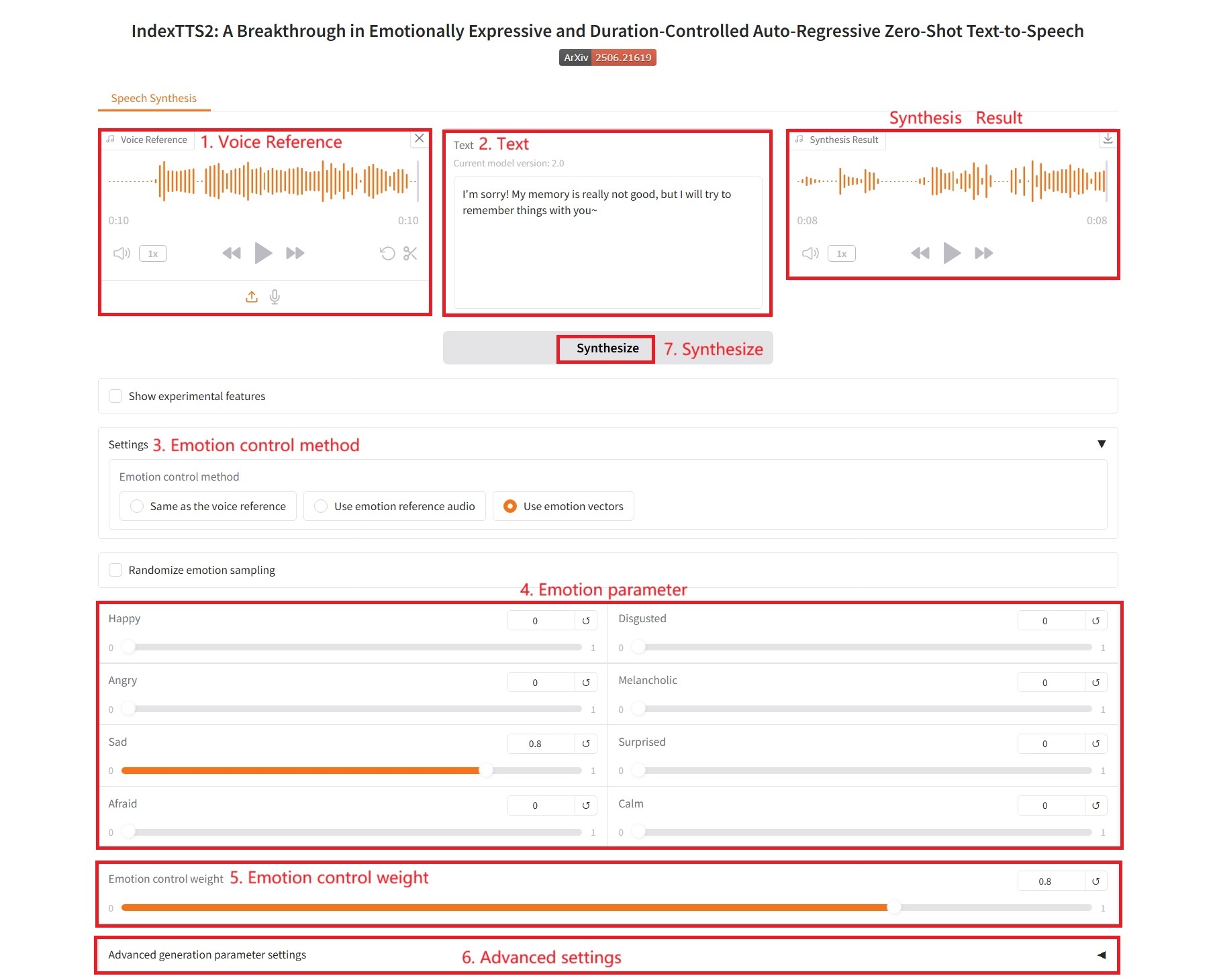
Emotionale Kontrollparameter:
- Glücklich, Angewidert, Wütend, Melancholisch, Traurig, Überrascht, Ängstlich, Ruhig: Diese entsprechen acht grundlegenden emotionalen Dimensionen. Der Wert jedes Schiebereglers (normalerweise zwischen 0,0 und 1,0) gibt die Intensität der Emotion an, die in der endgültigen Rede zum Ausdruck kommen soll.
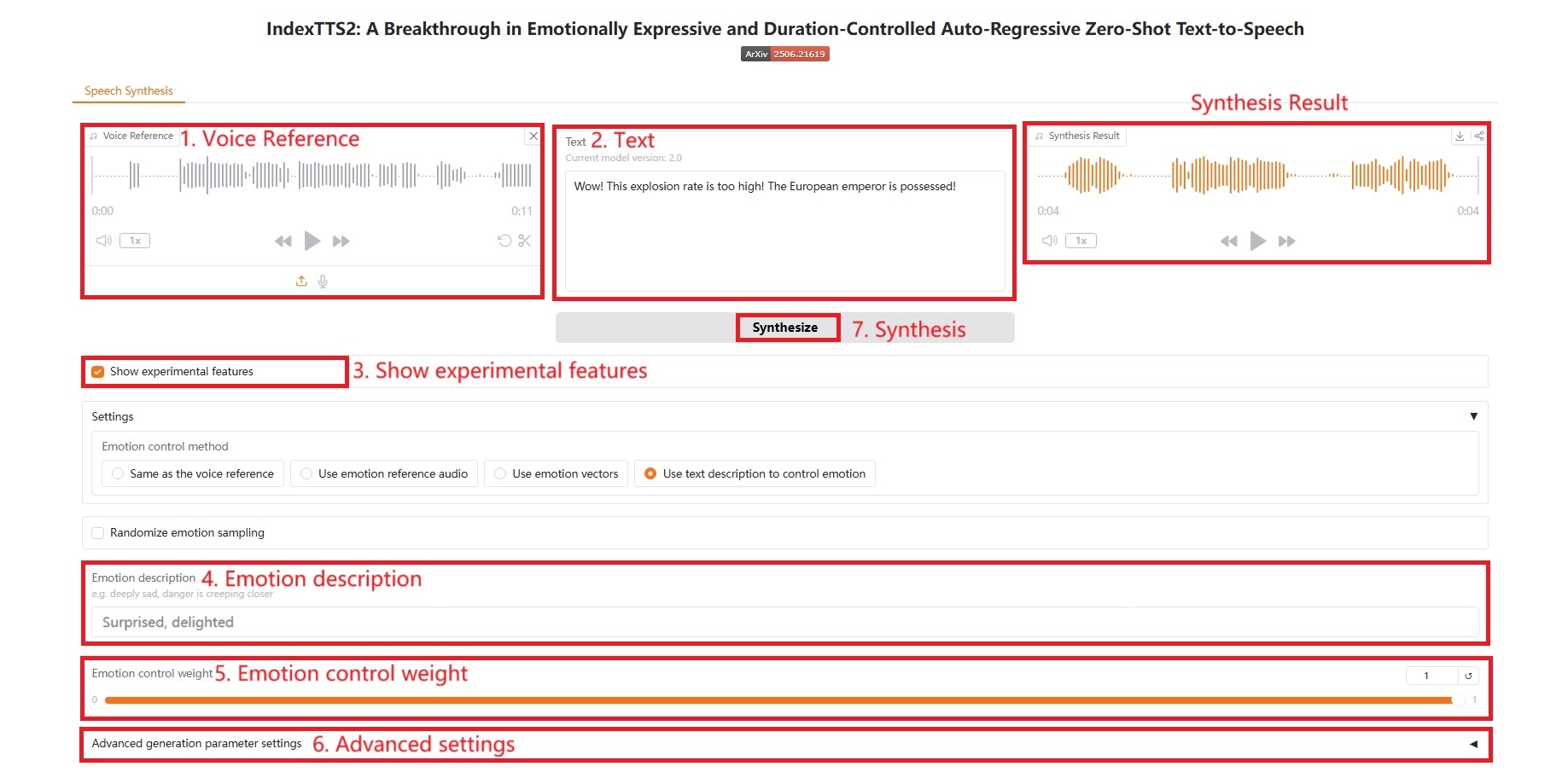
4. Verwenden Sie Textbeschreibungen, um Emotionen zu kontrollieren
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{zhou2025indextts2,
title={IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv preprint arXiv:2506.21619},
year={2025}
}
@article{deng2025indextts,
title={IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv preprint arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.