Command Palette
Search for a command to run...
USO: Ein Einheitliches, Stil- Und Themenorientiertes Bildgenerierungsmodell
Datum
Größe
699.93 MB
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

USO, im August 2025 vom UXO-Team von ByteDance eingeführt, ist ein einheitliches Framework zur Entkopplung und Rekombination von Inhalt und Stil. Es ermöglicht die freie Kombination beliebiger Themen und Stile in jeder Szene und generiert so Bilder mit hoher Motivkonsistenz, starker Stiltreue und einem natürlichen, authentischen Erscheinungsbild. USO erstellt einen umfangreichen Triplet-Datensatz, verwendet ein Entkopplungslernverfahren zur gleichzeitigen Ausrichtung von Stilmerkmalen und Trennung von Inhalt und Stil und führt Style Reward Learning (SRL) ein, um die Modellleistung weiter zu verbessern. USO hat den USO-Bench-Benchmark-Test veröffentlicht, der Stilähnlichkeit und Motivtreue umfassend evaluiert. Experimente zeigen, dass USO in Bezug auf Motivkonsistenz und Stilähnlichkeit Bestleistungen unter den Open-Source-Modellen erzielt. Zugehörige Forschungsarbeiten sind verfügbar. USO: Einheitlicher Stil und themenorientierte Generierung durch entwirrtes und belohnendes Lernen .
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne RTX 4090-Karte.
2. Effektanzeige
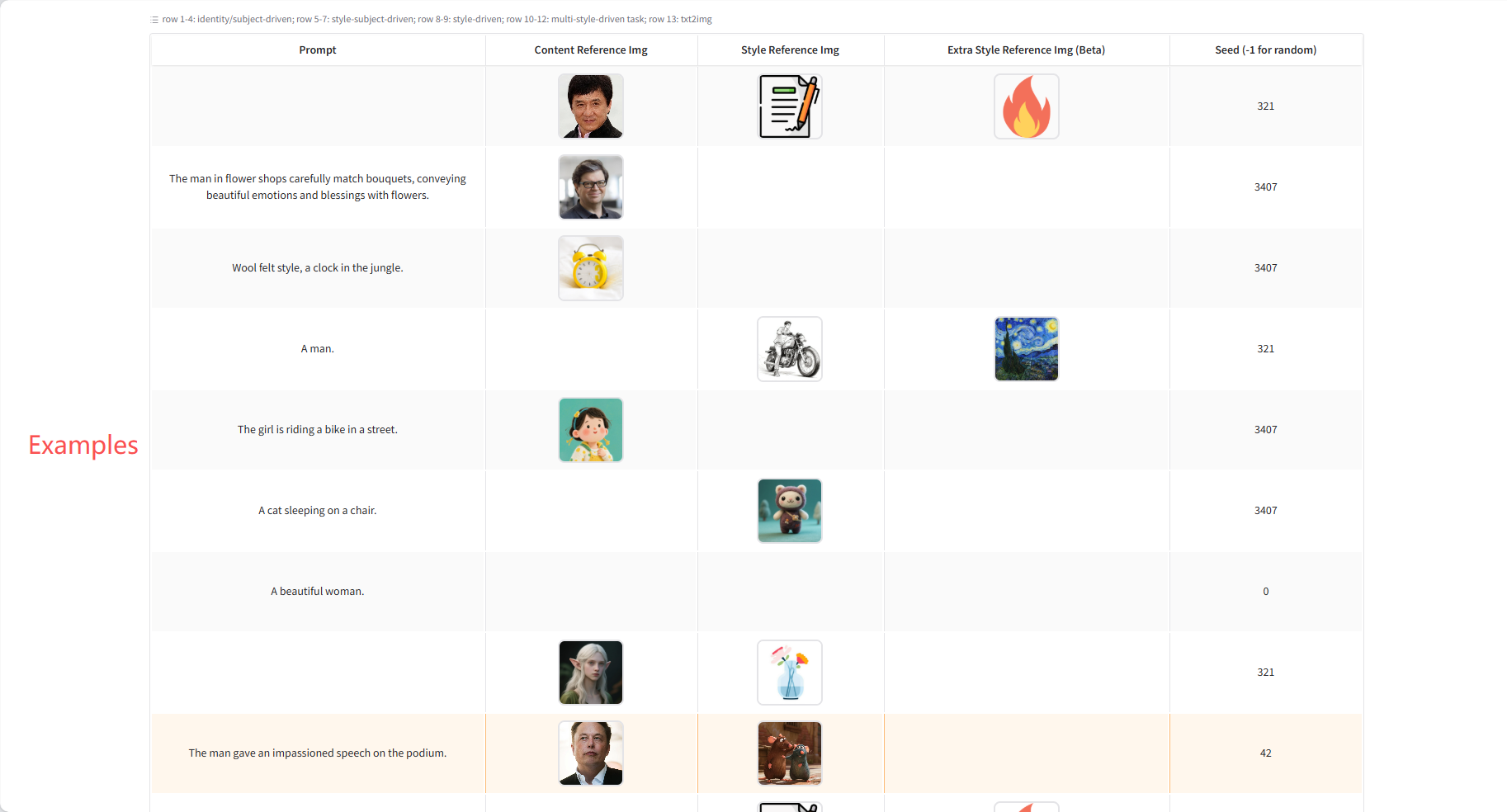
Themen-/Identitätsorientierte Generation
Wenn Sie das Motiv in eine neue Szene einfügen möchten, verwenden Sie natürliche Sprache, z. B. „Der Hund/Mann/die Frau macht …“. Wenn Sie nur den Stil übertragen und das Layout beibehalten möchten, verwenden Sie Hinweise, z. B. „Übertragen Sie den Stil auf den Stil von …“. Bei der Porträtgenerierung zeichnet sich USO durch die Generierung von Bildern mit hoher Hautdetailliertheit aus. Praktische Anleitung: Verwenden Sie für Halbkörper-Hinweise Halbkörper-Nahaufnahmen; verwenden Sie Ganzkörperbilder, wenn sich Pose oder Bildausschnitt deutlich ändern.

Stilorientierte Generation
Laden Sie einfach ein oder zwei Bilder in Ihrem Stil hoch und erstellen Sie mithilfe natürlicher Sprache das gewünschte Bild. USO folgt Ihren Anweisungen und generiert Bilder, die zu dem von Ihnen hochgeladenen Stil passen.

Stilthema-gesteuerte Generierung
USO kann eine einzelne Inhaltsreferenz mithilfe von ein oder zwei Stilreferenzen formatieren. Für layouterhaltende Builds setzen Sie den Hinweis einfach auf „leer“.
Layouterhaltende Builds

Layout-Offset-Generierung

3. Bedienungsschritte
1. Starten Sie den Container
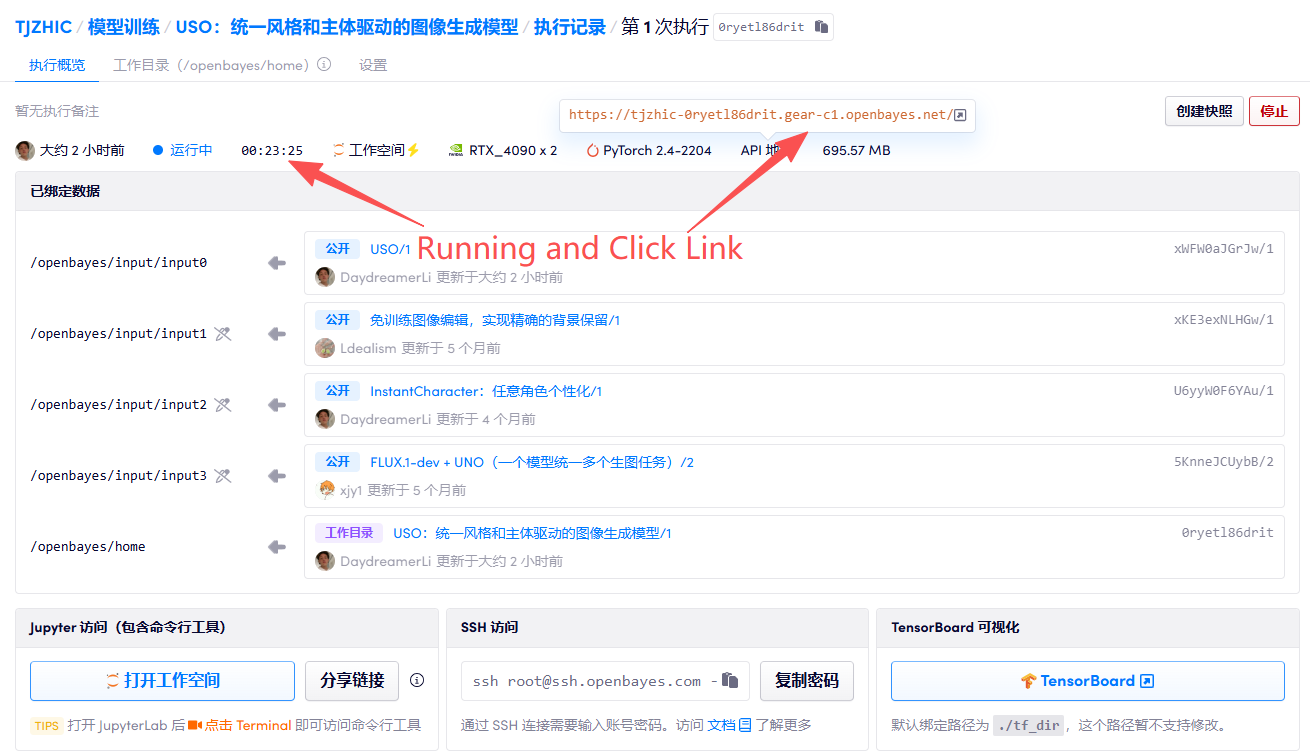
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
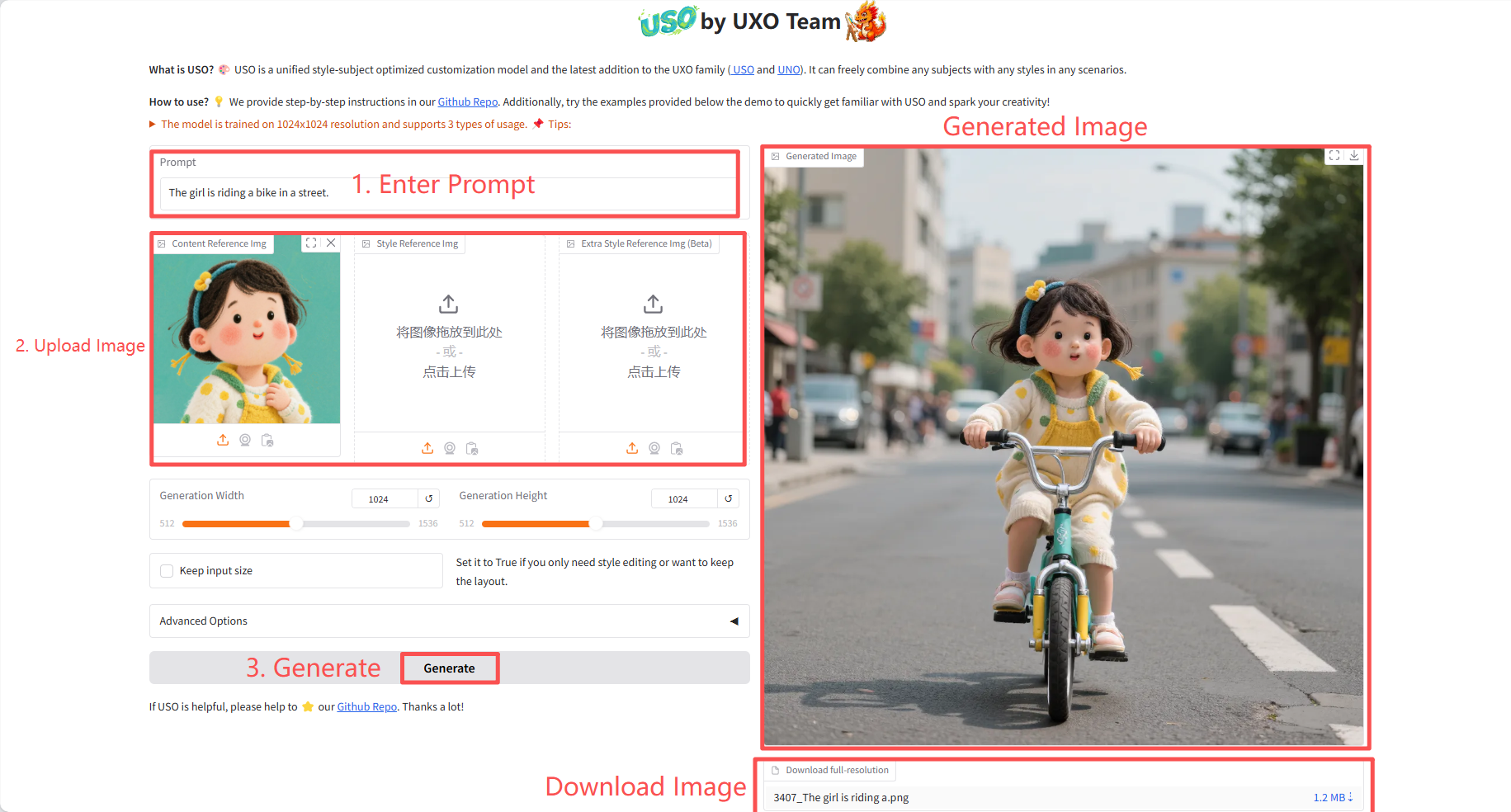
Spezifische Parameter:
- Generierungsbreite: Bildbreite generieren.
- Generierungshöhe: Die Höhe des generierten Bildes.
- Eingabegröße beibehalten: Setzen Sie dies auf „True“, wenn Sie nur die Stilbearbeitung benötigen oder das Layout beibehalten möchten.
- Erweiterte Optionen:
- Anzahl der Schritte: Steuert die Anzahl der Iterationen bei der Generierung des Diffusionsmodells. Eine höhere Anzahl von Schritten führt theoretisch zu einer höheren Bildqualität, erhöht aber auch die Generierungszeit.
- Anleitung: Steuert, inwieweit das generierte Bild dem Eingabewort und dem Referenzbild folgt.
- Größe der Inhaltsreferenz: Bei der Verarbeitung des Inhaltsreferenzbilds kann es vor der Merkmalsextraktion auf diese angegebene längste Seitenlänge skaliert werden (unter Beibehaltung des Seitenverhältnisses).
- Seed (-1 für Zufall): Steuert den Anfangszustand des Zufallszahlengenerators.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{wu2025uso,
title={USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning},
author={Shaojin Wu and Mengqi Huang and Yufeng Cheng and Wenxu Wu and Jiahe Tian and Yiming Luo and Fei Ding and Qian He},
year={2025},
eprint={2508.18966},
archivePrefix={arXiv},
primaryClass={cs.CV},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.