Command Palette
Search for a command to run...
vLLM + Open WebUI Deploy NVIDIA-Nemotron-Nano-9B-v2
1. Einführung in das Tutorial
NVIDIA-Nemotron-Nano-9B-v2 ist ein ressourcenschonendes Sprachmodell für große Textmengen, das am 19. August 2025 vom NVIDIA-Team veröffentlicht wurde. Als optimierte Hybridarchitektur der Nemotron-Serie integriert dieses Modell auf innovative Weise die effiziente Verarbeitung langer Textsequenzen von Mamba mit den leistungsstarken semantischen Modellierungsfähigkeiten von Transformer. Es unterstützt 128.000 extrem lange Kontexte mit nur 9 Milliarden (9 Milliarden) Parametern. Seine Inferenzeffizienz und Leistung auf Edge-Computing-Geräten (wie GPUs der RTX 4090-Klasse) sind vergleichbar mit denen aktueller Modelle ähnlicher Parametergrößen. Dies stellt einen bedeutenden Durchbruch für die ressourcenschonende Bereitstellung und das Verständnis langer Texte für große Sprachmodelle dar. Zugehörige Forschungsarbeiten sind verfügbar. NVIDIA Nemotron Nano 2: Ein genaues und effizientes hybrides Mamba-Transformer-Reasoning-Modell .
Dieses Tutorial verwendet eine einzelne RTX A6000-Karte als Ressource.
2. Projektbeispiele
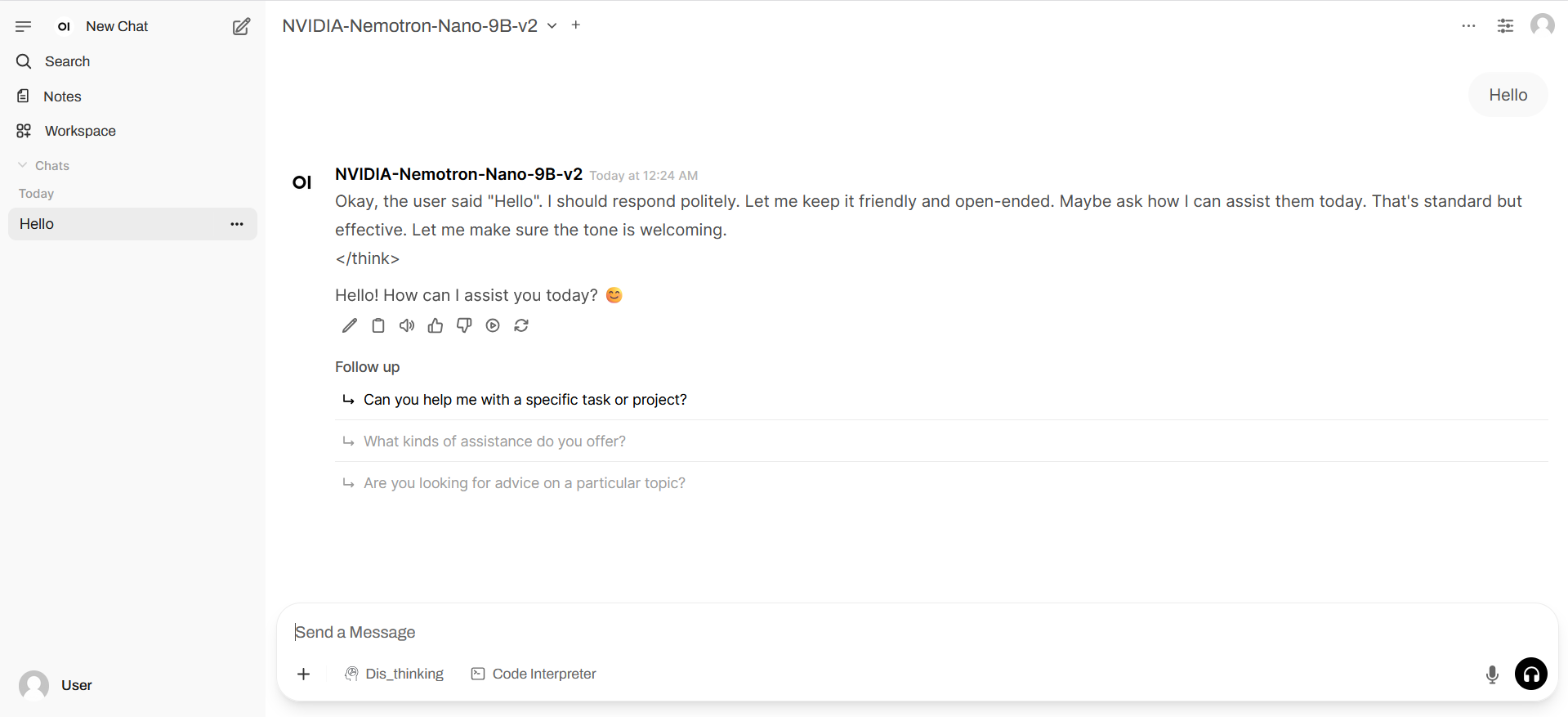
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
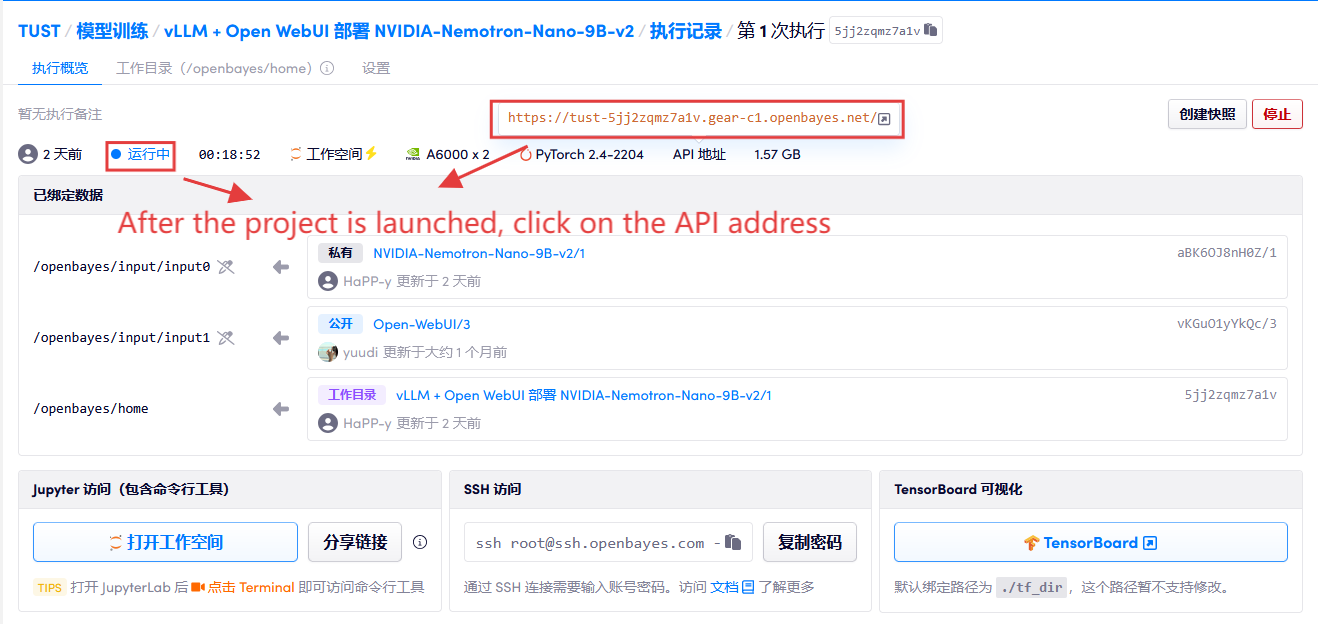
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2-3 Minuten und aktualisieren Sie die Seite.
Anwendung
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.