Command Palette
Search for a command to run...
Higgs Audio V2: Die Ausdruckskraft Der Sprachgenerierung Neu Definieren
Datum
Größe
410.43 MB
Tags
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

Dieses Tutorial verwendet eine einzelne RTX 4090-Grafikkarte. Es bietet sechs Beispiele zum Testen: Voice-Clone, Smart-Voice, Multispeaker-Voice-Description, Single-Speaker-Voice-Description, Single-Speaker-ZH und Single-Speaker-BGM. Die Systemeingabeaufforderung unterstützt nur Englisch.
2. Projektbeispiele
Sprachklon
Smart Voice
Multispeaker-Sprachbeschreibung
Einzelsprecher-Sprachbeschreibung
Einzellautsprecher-zh
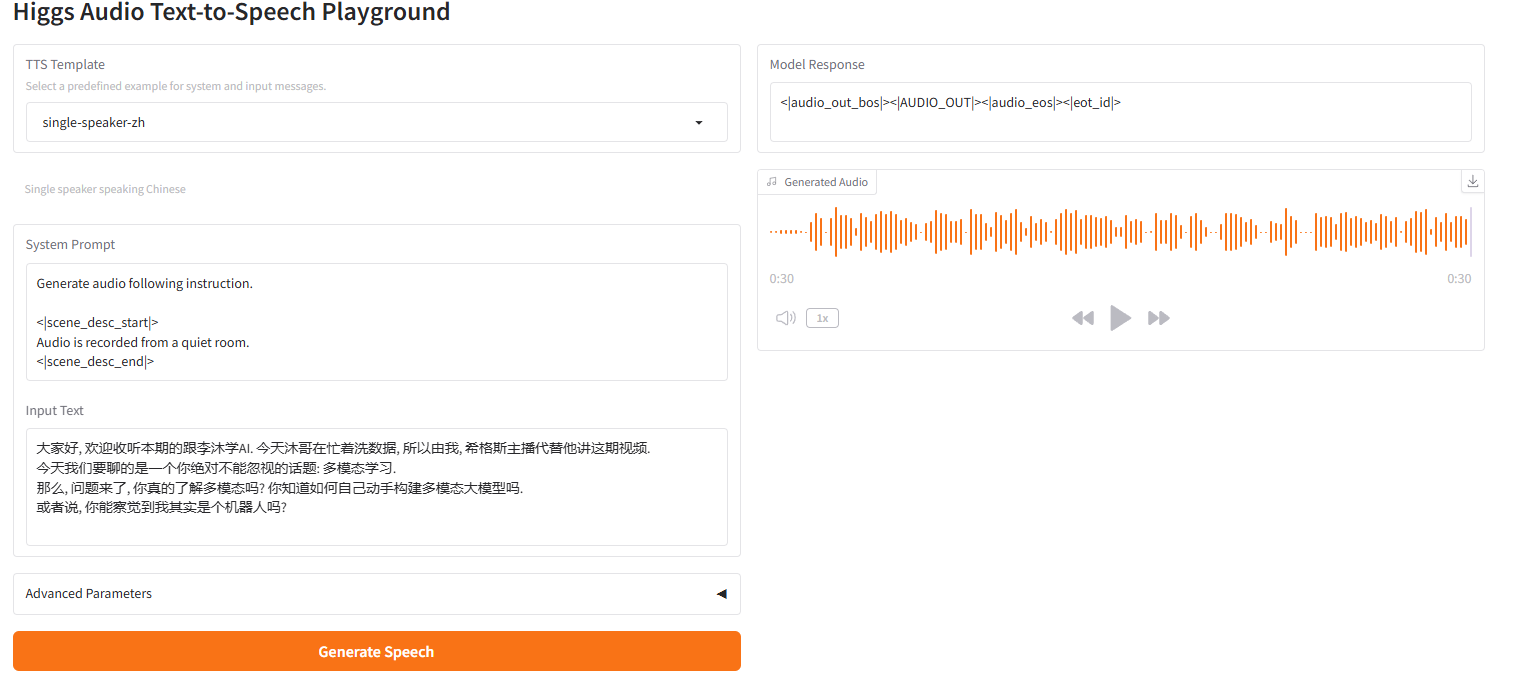
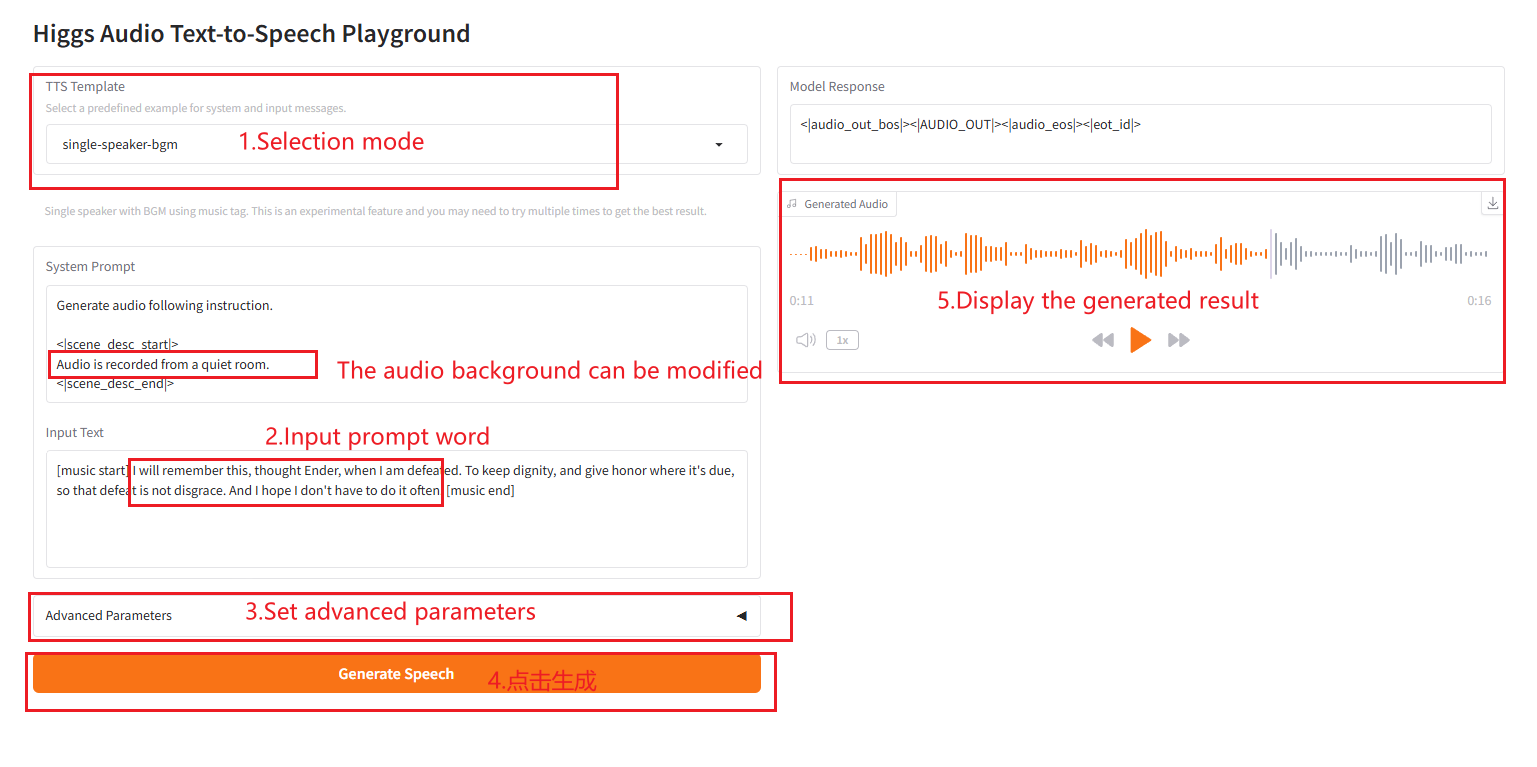
Einzellautsprecher-Hintergrundmusik
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
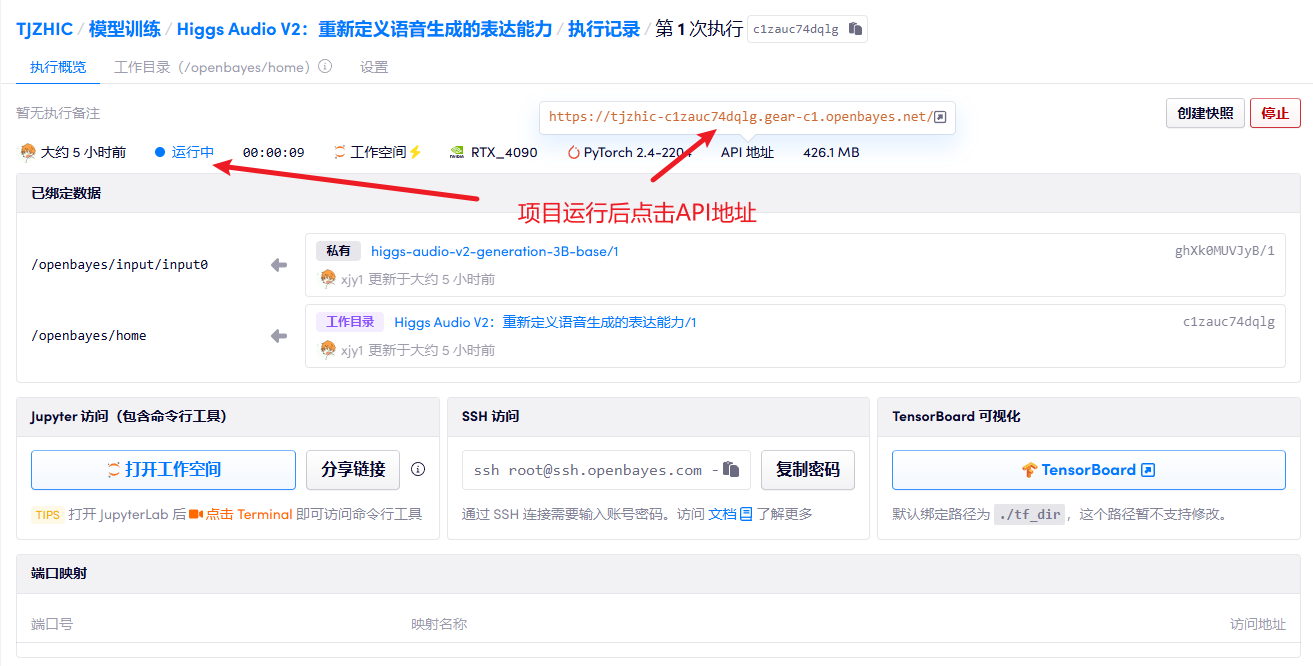
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite. Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
2.1 Sprachklon
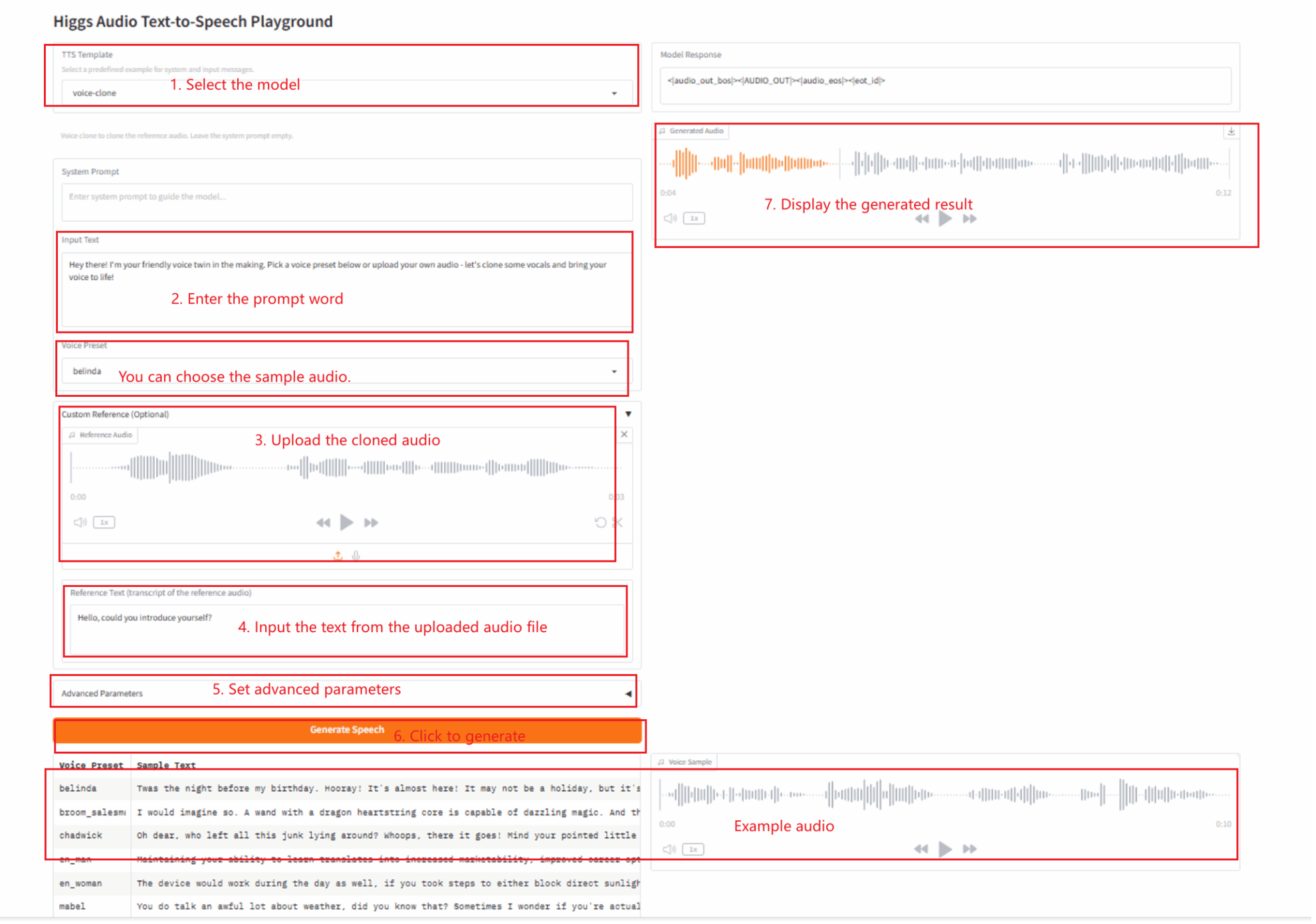
Parameterbeschreibung
- Erweiterte Parameter:
- Max. Vervollständigungstoken: Begrenzt die Länge des generierten Audiotextes (in Token). Je größer der Wert, desto länger kann der generierte Audiotext sein.
- Temperatur: Steuert die Zufälligkeit der generierten Ausgabe. Niedrige Werte (z. B. 0,1) machen die Ausgabe deterministischer und wiederholbarer; hohe Werte (z. B. 1,0) machen die Ausgabe abwechslungsreicher und kreativer, aber möglicherweise inkohärent.
- Top P: Begrenzt den Bereich der Bezeichnungen (kumulative Wahrscheinlichkeiten), die das Modell bei jedem Schritt berücksichtigt. Niedrige Werte (z. B. 0,5) führen zu einer stärkeren Konzentration der Ausgabe, hohe Werte (z. B. 0,95) zu einer stärkeren Diversifizierung der Ausgabe.
- Top K: Schränkt das Modell ein, sodass bei jedem Schritt nur die K wahrscheinlichsten Marker ausgewählt werden. Niedrige Werte machen die Ausgabe sicherer; hohe Werte (oder -1 zum Deaktivieren) machen die Ausgabe vielfältiger.
- RAS-Fensterlänge: Aktiviert die Funktion zur Duplikatsvermeidung und definiert die Größe des Textfensters zur Duplikatsprüfung. Setzen Sie den Wert auf 0, um diese Funktion zu deaktivieren.
- RAS Max Num Repeat: Definiert in Verbindung mit dem RAS-Fenster die maximale Anzahl von Wiederholungen eines Inhalts innerhalb des Fensters. Ein niedriger Wert reduziert Wiederholungen, während ein hoher Wert natürlichere Wiederholungen ermöglicht.
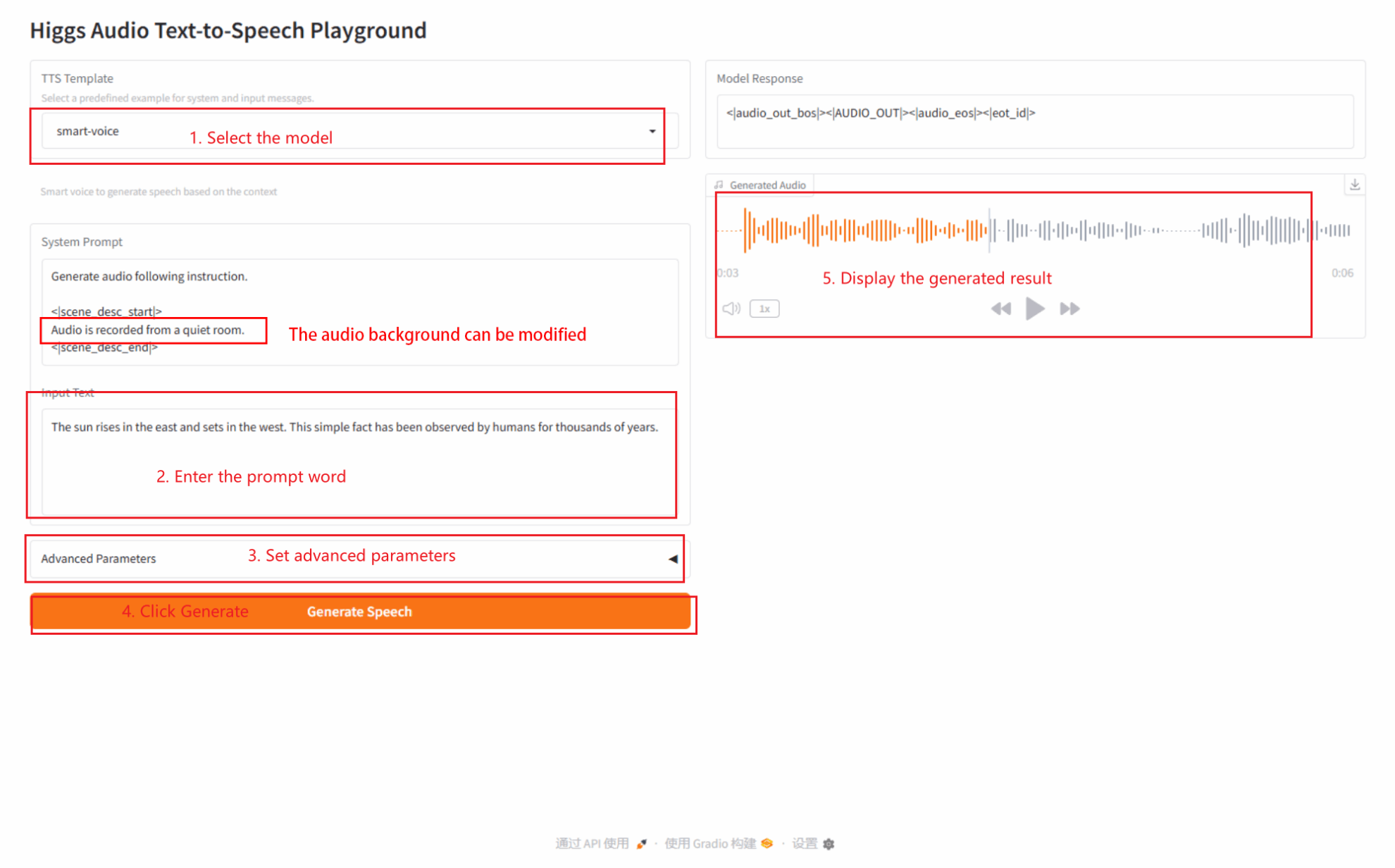
2.2 Smart-Voice
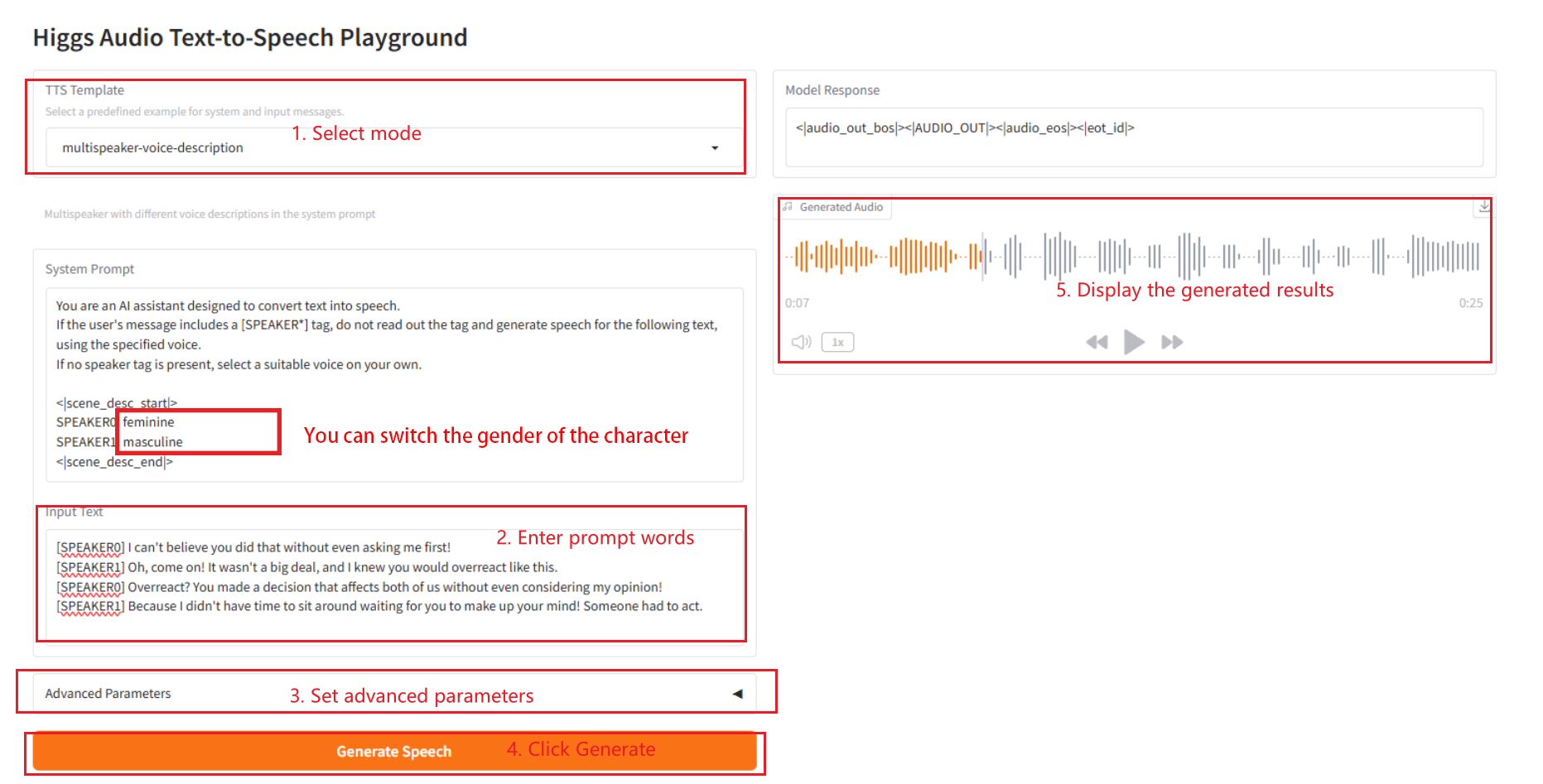
2.3 Multispeaker-Sprachbeschreibung
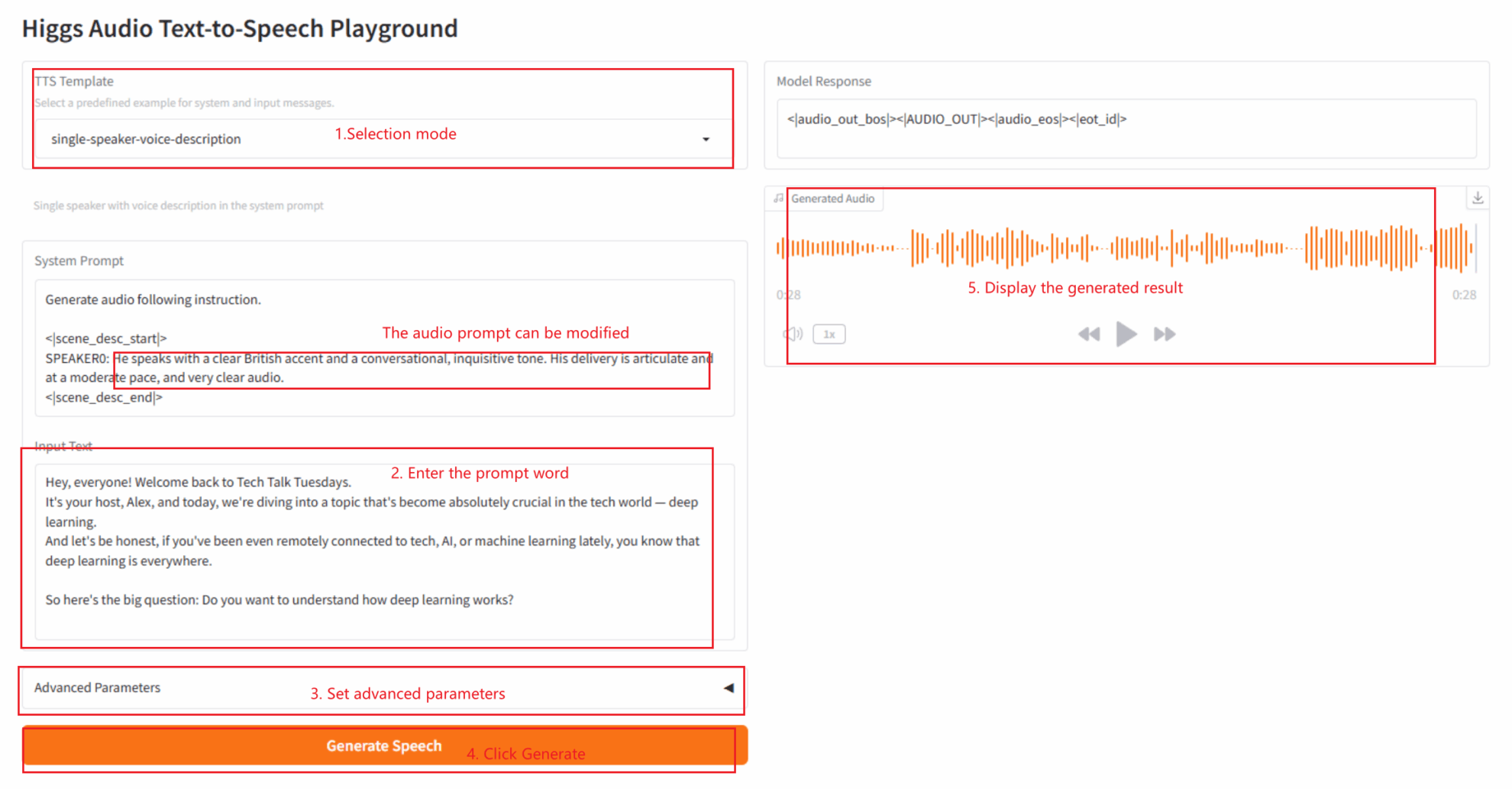
2.4 Einzelsprecher-Sprachbeschreibung
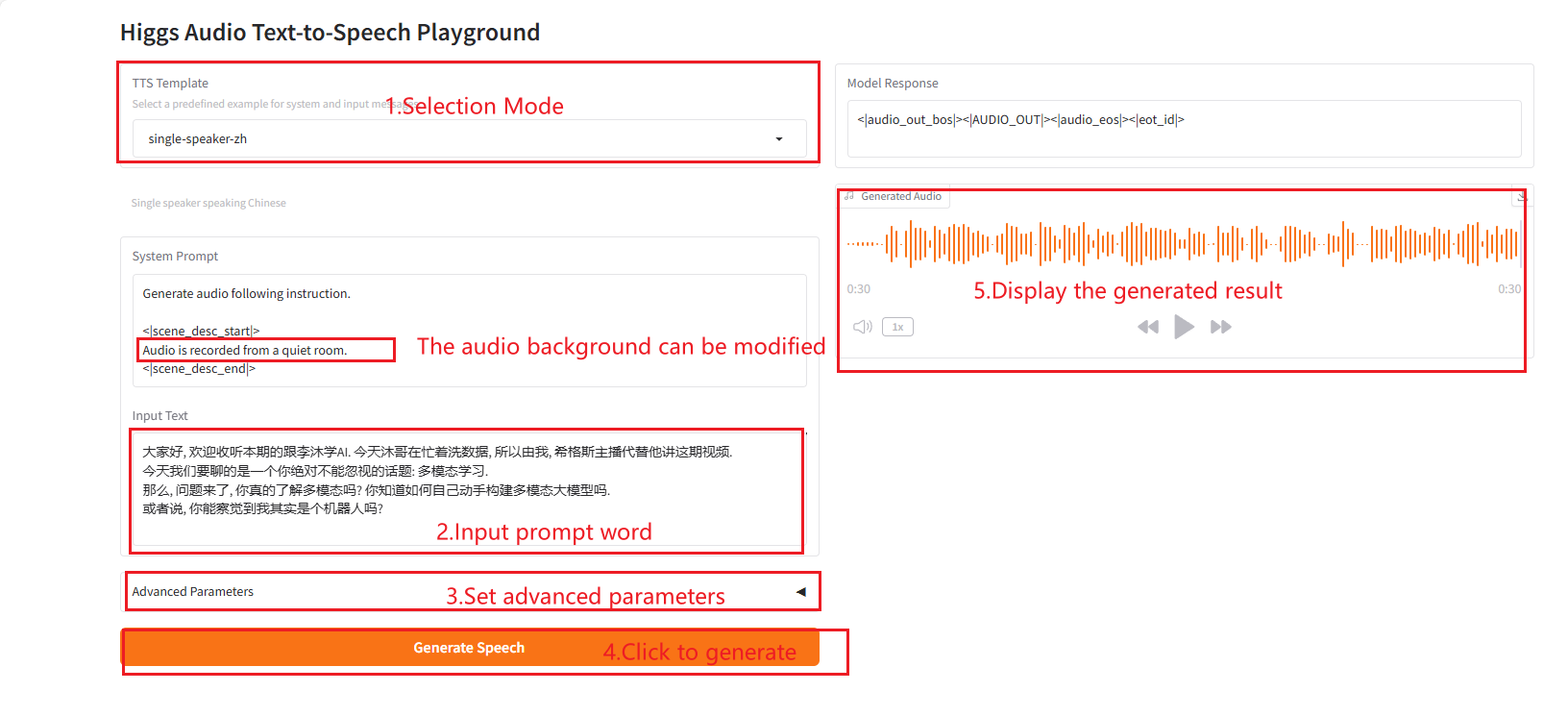
2.5 Einzellautsprecher-zh
2.6 Einzellautsprecher-Hintergrundmusik
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{higgsaudio2025,
author = {{Boson AI}},
title = {{Higgs Audio V2: Redefining Expressiveness in Audio Generation}},
year = {2025},
howpublished = {\url{https://github.com/boson-ai/higgs-audio}},
note = {GitHub repository. Release blog available at \url{https://www.boson.ai/blog/higgs-audio-v2}},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.