Command Palette
Search for a command to run...
LFM2-1.2B: Ein Textgenerierungsmodell Für Eine Effiziente Edge-Bereitstellung
1. Einführung in das Tutorial
LFM2-1.2B ist die zweite Generation des Liquid Foundation Model (LFMs), das Liquid AI am 10. Juli 2025 eingeführt hat. Es handelt sich um ein generatives KI-Modell, das auf einer Hybridarchitektur basiert. Es bietet das branchenweit schnellste On-Device-Erlebnis generativer KI und ist für latenzarme On-Device-Sprachmodell-Workloads konzipiert.
Als Modell mit neuer Hybridarchitektur kombiniert LFM2-1.2B auf innovative Weise Multiplikationsgating und kurze Faltung und enthält 16 Blöcke (10 dual-gated LIV-Faltungsblöcke mit kurzer Reichweite und 6 Gruppenabfrage-Aufmerksamkeitsblöcke). Dadurch werden die Defizite herkömmlicher Modelle hinsichtlich Verarbeitungseffizienz und Leistung behoben. Das Training basiert auf einem vorab trainierten Korpus von 10 Billionen Token und nutzt mehrstufige Trainingsstrategien wie Wissensdestillation, groß angelegte überwachte Feinabstimmung (SFT) und benutzerdefinierte direkte Präferenzoptimierung (DPO). Es übertrifft Modelle derselben Größenordnung in mehreren Benchmark-Kategorien wie Wissen, Mathematik, Anweisungsverfolgung und Mehrsprachigkeit und kann sogar mit Modellen mit größeren Parameterskalen konkurrieren. Gleichzeitig ist die Dekodierungs- und Vorfüllgeschwindigkeit auf der CPU doppelt so schnell wie bei Qwen 3, und die Trainingseffizienz ist dreimal höher als bei der vorherigen LFM-Generation. Es läuft effizient auf CPU-, GPU- und NPU-Hardware und bietet eine flexible und effiziente Lösung für den Einsatz von Edge-Geräten.
Dieses Tutorial verwendet LFM2-1.2B als Demonstration und die Rechenressource verwendet RTX 4090. Unterstützte Sprachen: Englisch, Arabisch, Chinesisch, Französisch, Deutsch, Japanisch, Koreanisch und Spanisch.
2. Projektbeispiele
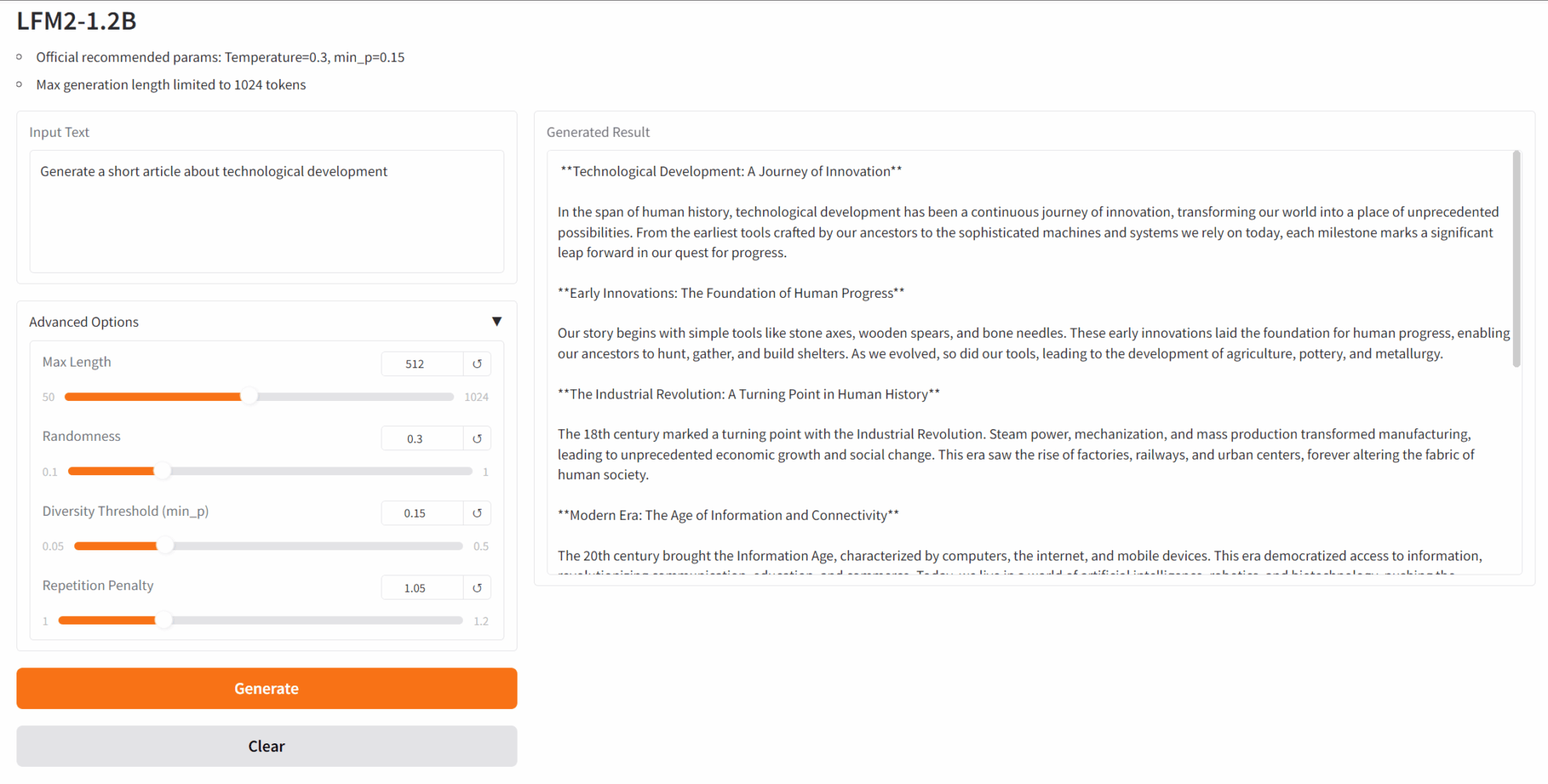
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
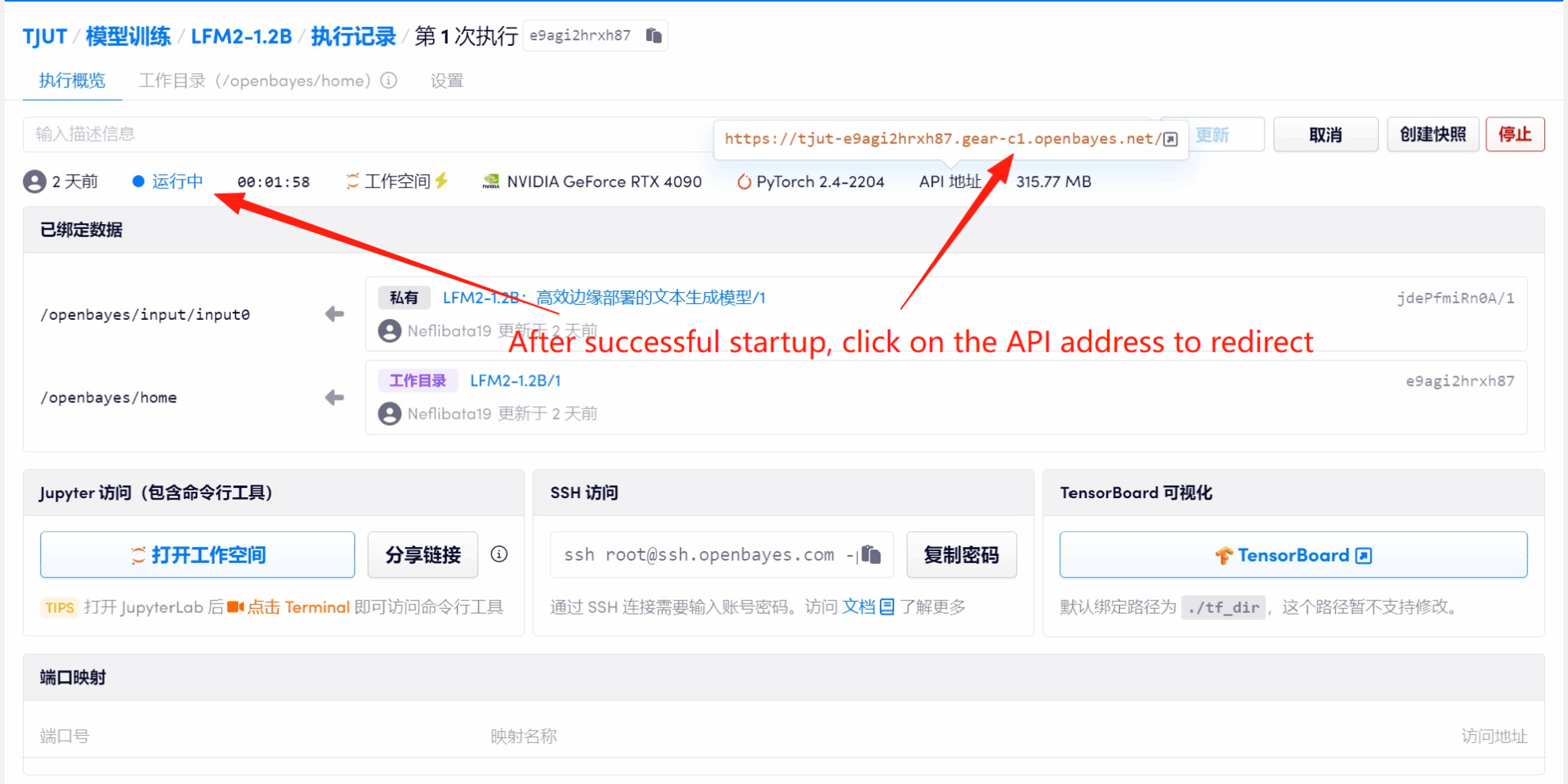
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
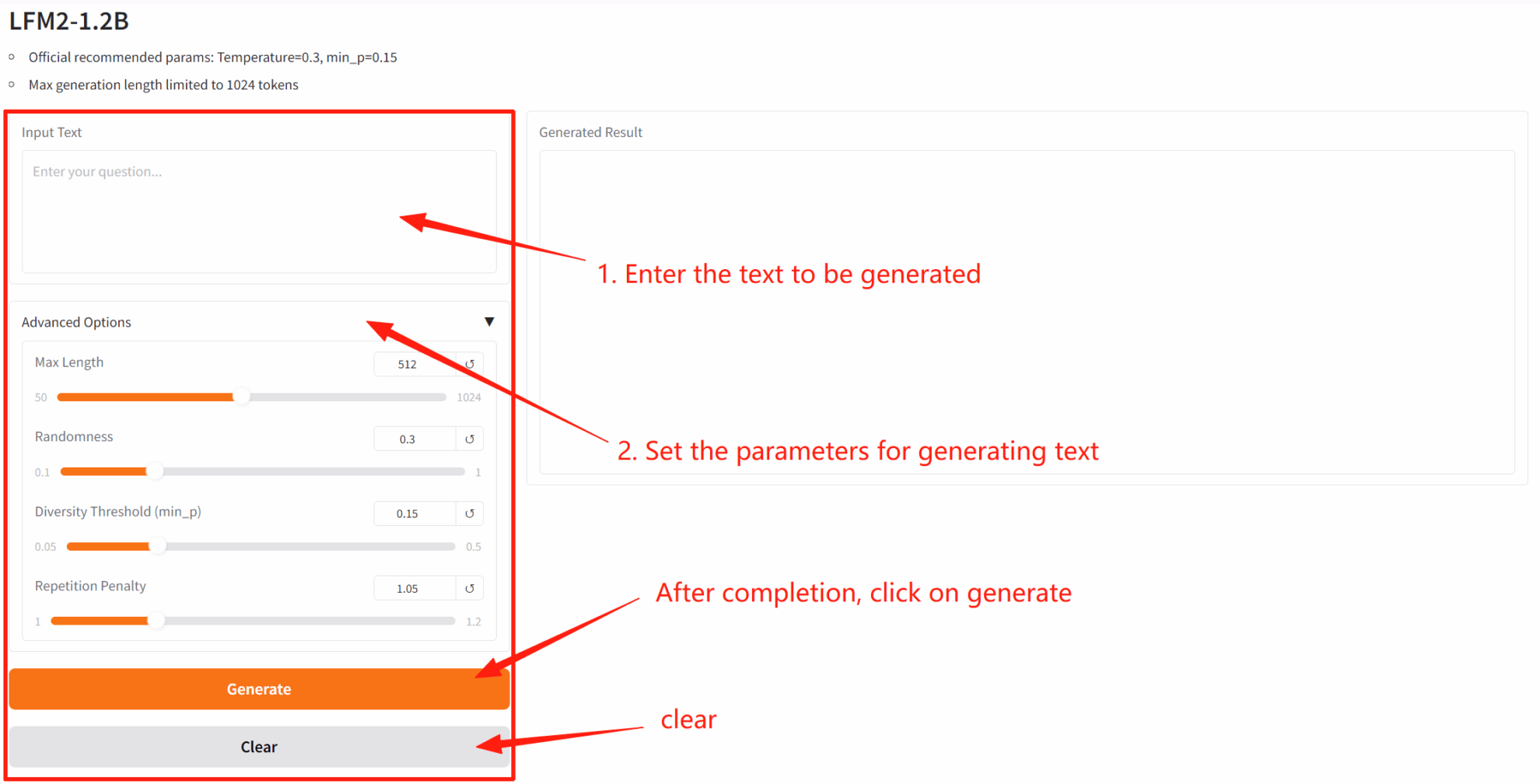
4. Diskussion
Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte eine Nachricht im Hintergrund, um es weiterzuempfehlen! Darüber hinaus haben wir eine Tutorial-Austauschgruppe eingerichtet. Scannen Sie den QR-Code und markieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu diskutieren und Anwendungsergebnisse auszutauschen.

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.