Command Palette
Search for a command to run...
Ein-Klick-Bereitstellung GLM-4.1V-9B-Thinking
1. Einführung in das Tutorial

GLM-4.1V-9B-Thinking ist ein Open-Source-Modell für visuelle Sprache, das am 2. Juli 2025 von Zhipu AI in Zusammenarbeit mit einem Team der Tsinghua-Universität veröffentlicht wurde. Es wurde speziell für komplexe kognitive Aufgaben entwickelt und unterstützt multimodale Eingaben wie Bilder, Videos und Dokumente. Basierend auf dem Basismodell GLM-4-9B-0414 führt GLM-4.1V-9B-Thinking ein Denkparadigma ein und erweitert die Fähigkeiten des Modells durch Curriculum Sampling (RLCS) umfassend. Dadurch erzielt es die höchste Leistung unter den Modellen für visuelle Sprache mit 10 Milliarden Parametern. In 18 Leaderboard-Aufgaben erreicht oder übertrifft es sogar Qwen-2.5-VL-72B, das die achtfache Anzahl an Parametern aufweist. Zugehörige Forschungsarbeiten sind verfügbar. GLM-4.1V-Denken: Auf dem Weg zu vielseitigem multimodalem Denken mit skalierbarem Verstärkungslernen .
Die Rechenressourcen dieses Tutorials nutzen eine einzelne RTX A6000-Karte. Dieses Tutorial unterstützt das Verständnis von Textkonversationen, Bildern, Videos, PDF und PPT.
2. Effektanzeige
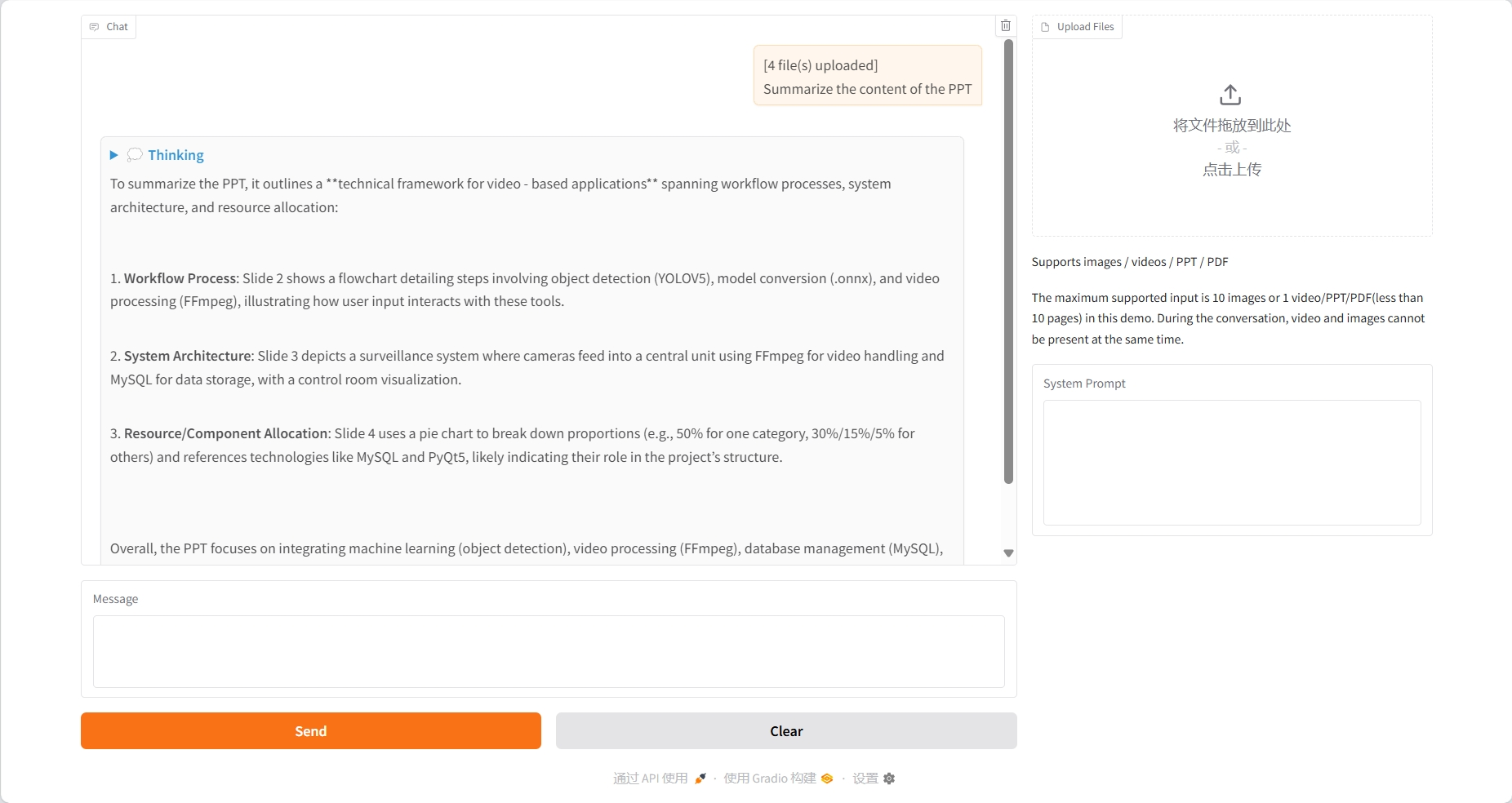
Textkonversation
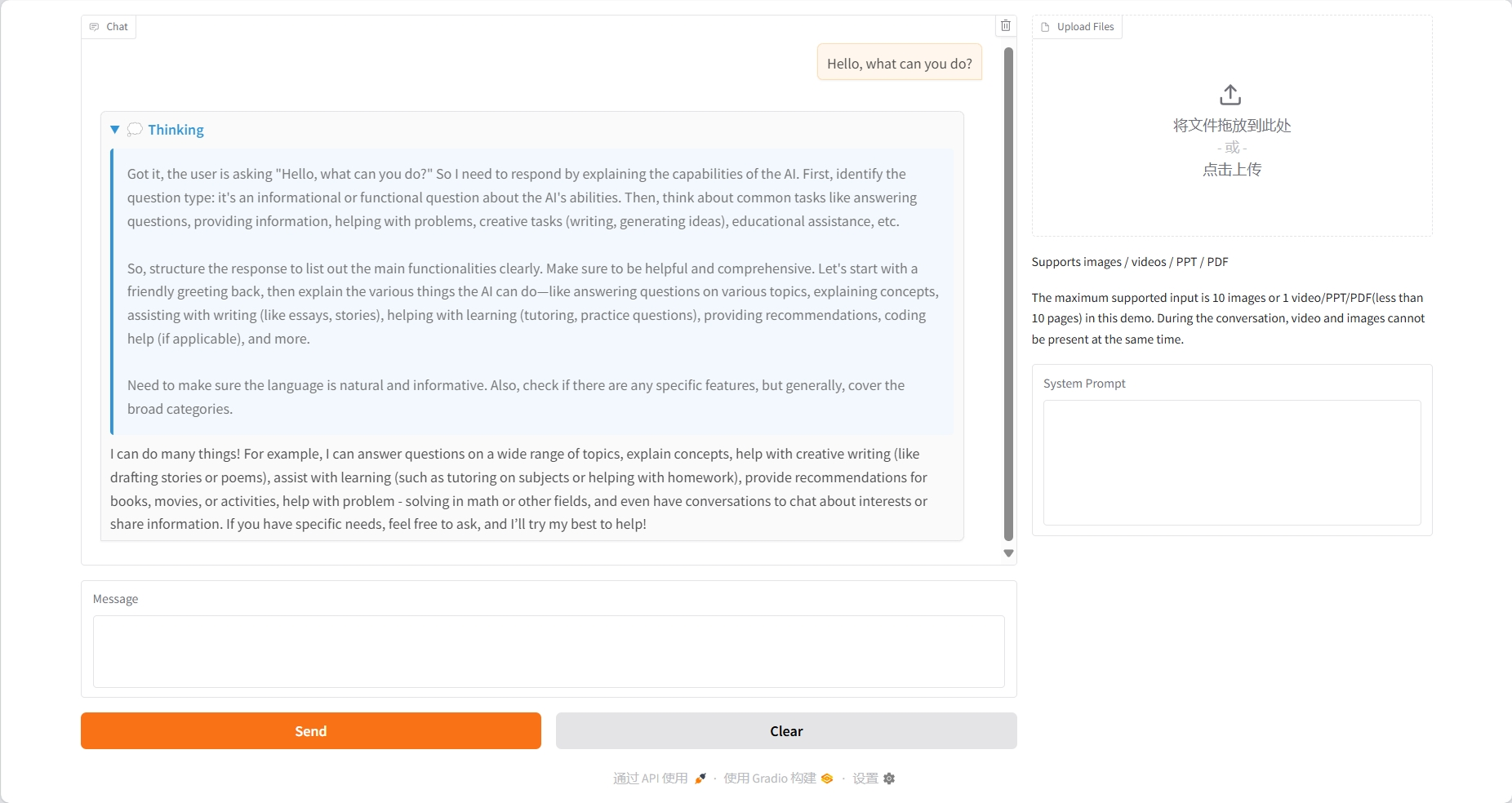
Bildverständnis
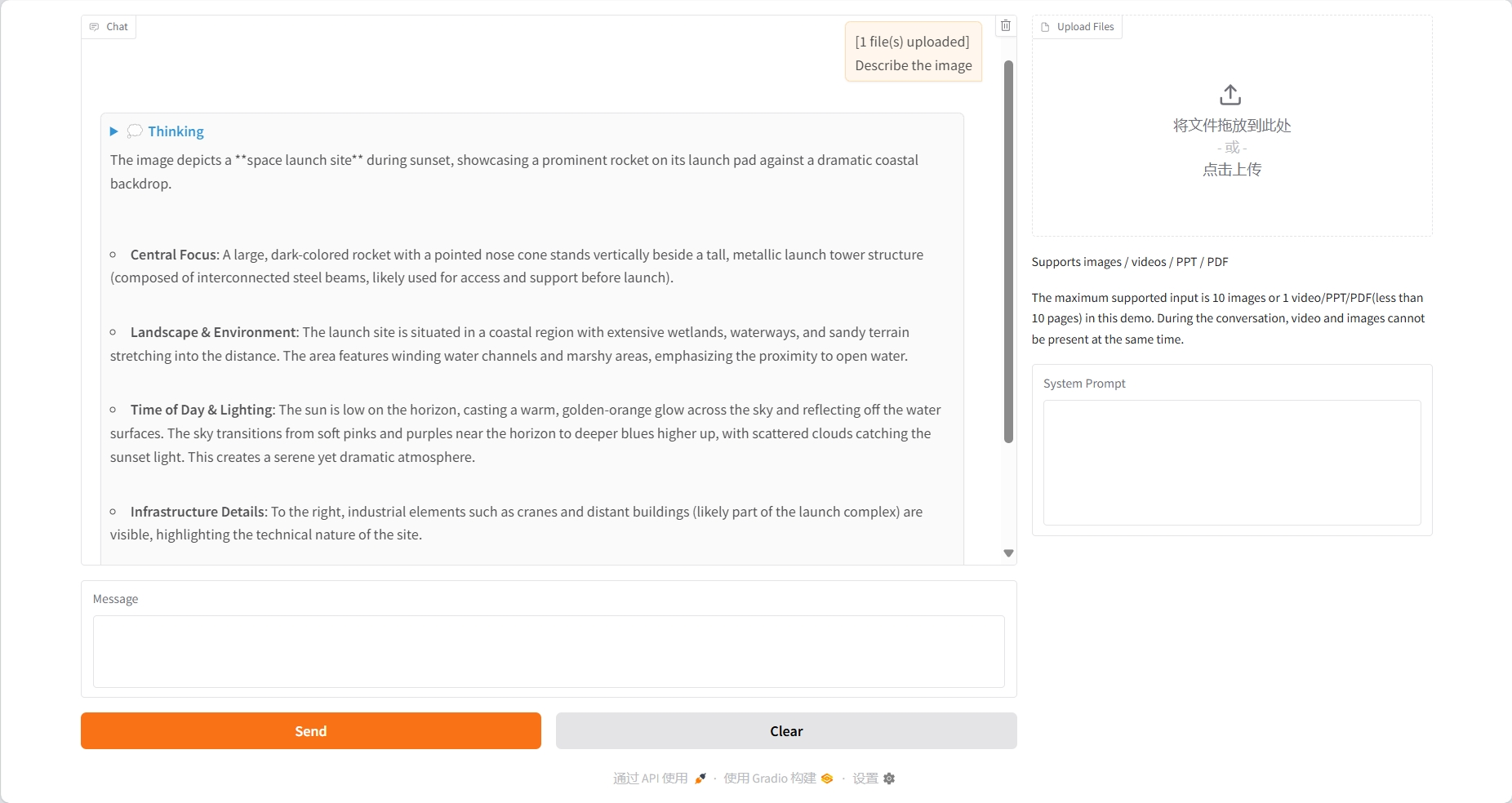
Videoverständnis
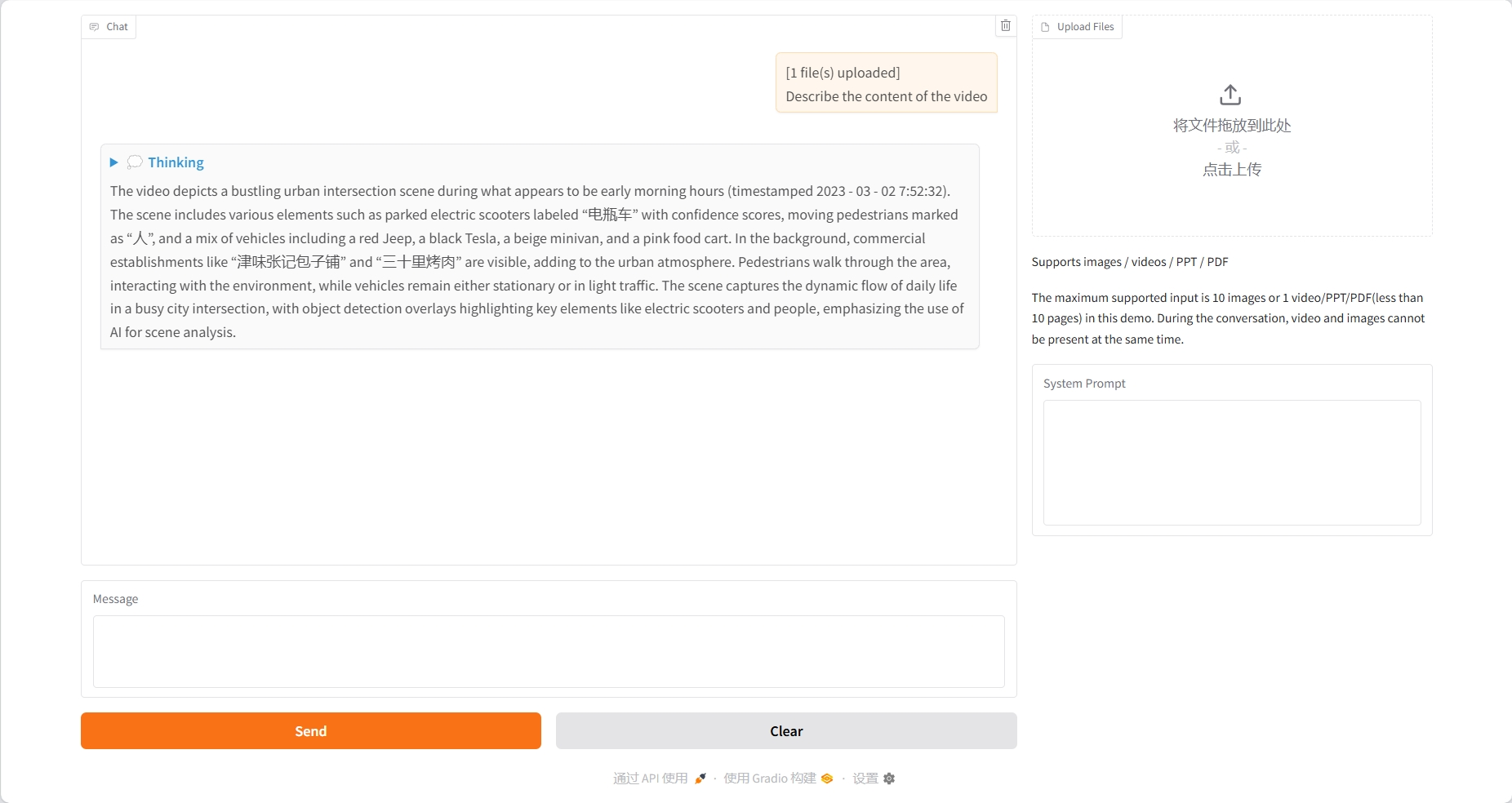
PDF-Verstehen
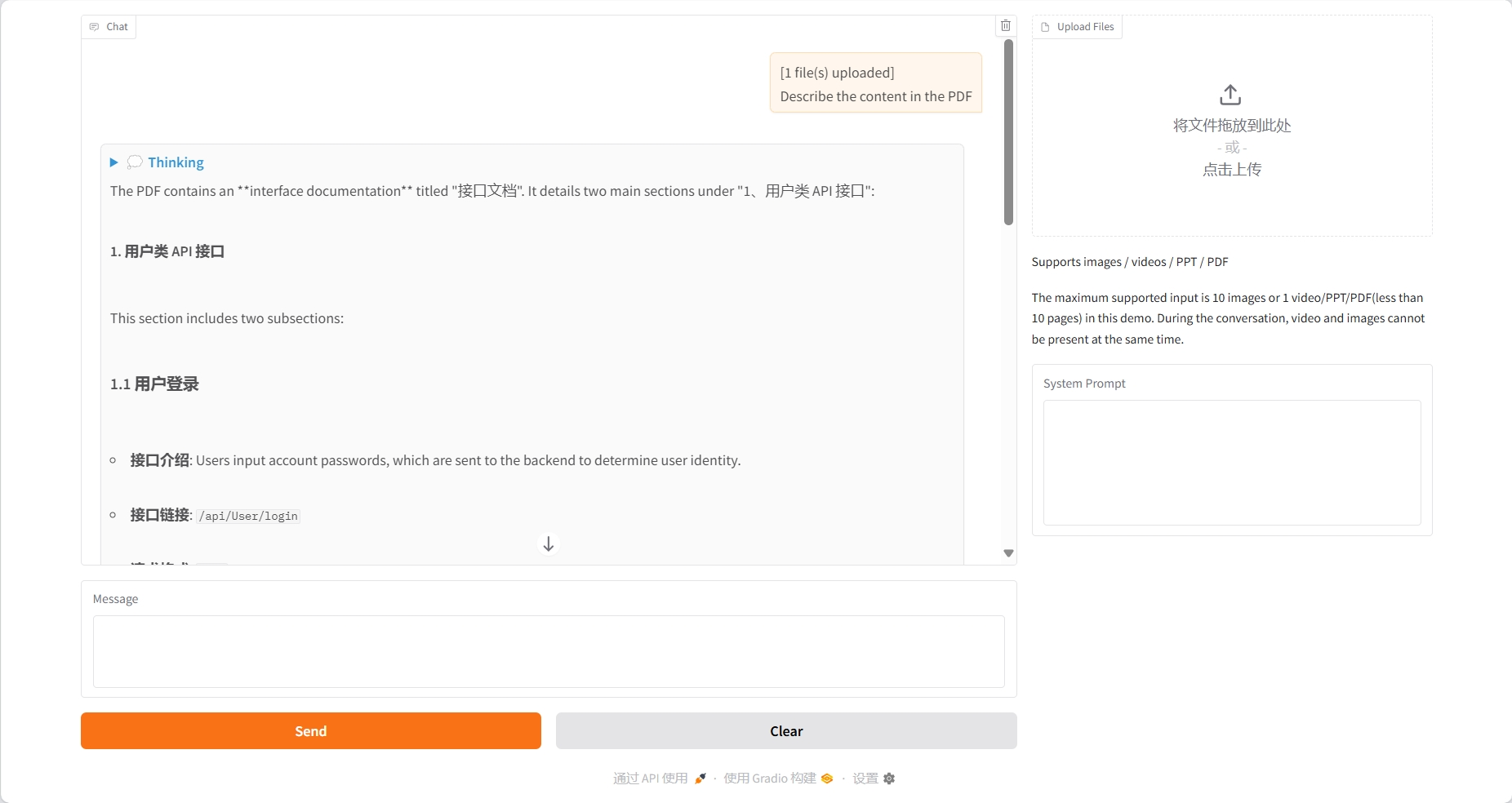
PPT-Verständnis
3. Bedienungsschritte
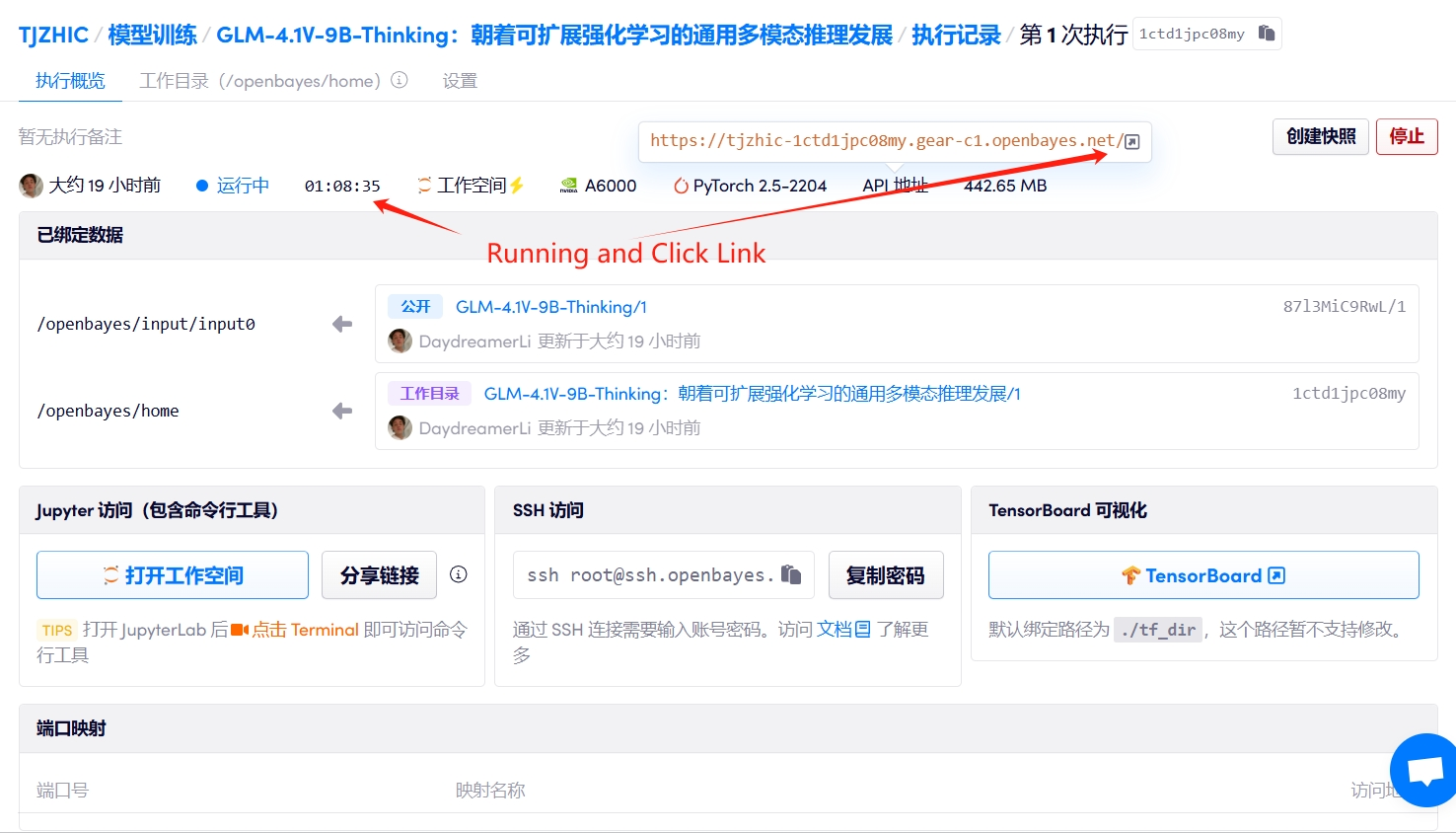
1. Starten Sie den Container
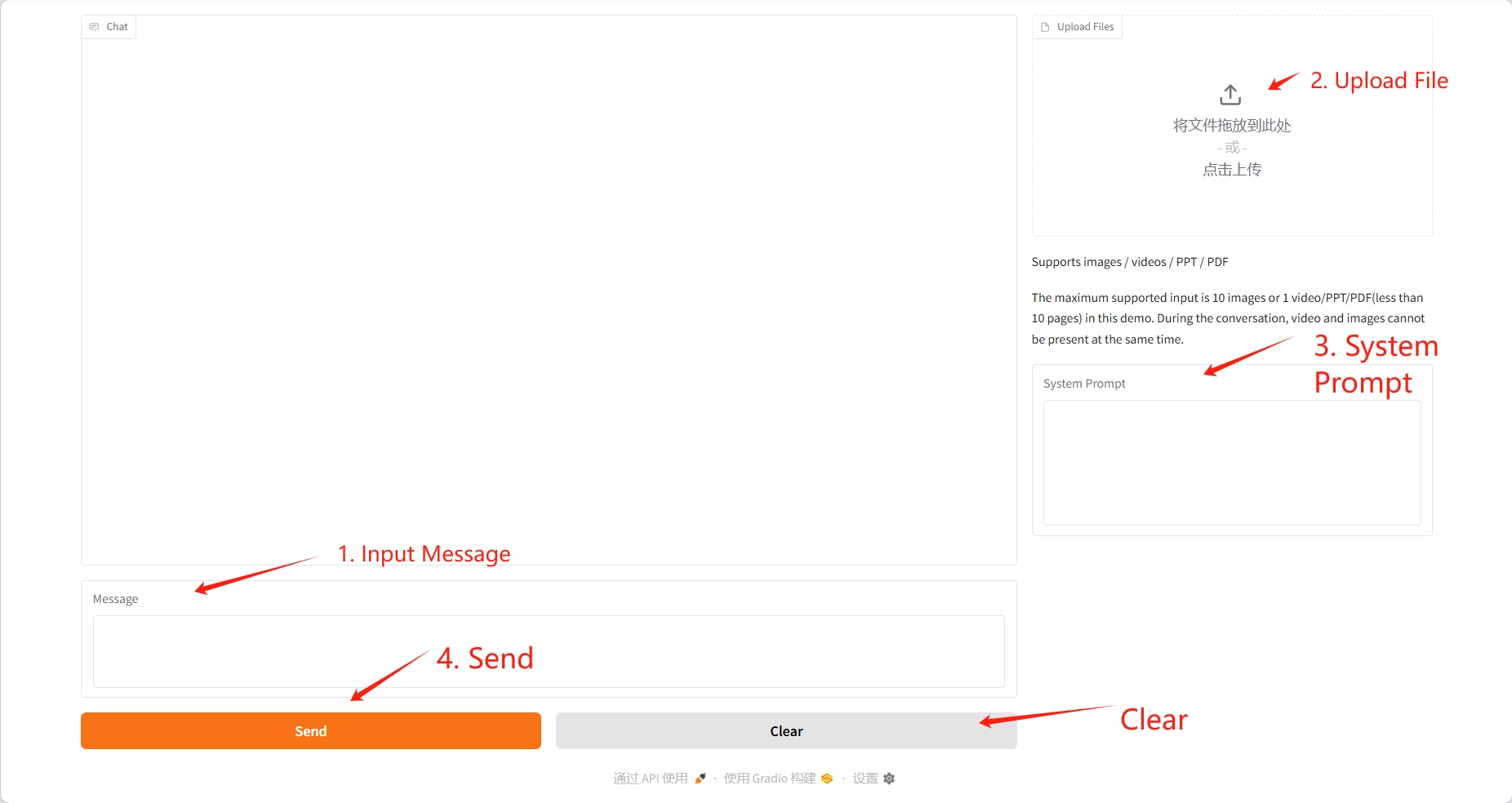
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
Das hochgeladene Video sollte maximal 10 Sekunden lang sein, die PDF- und PPT-Dateien maximal 10 Seiten. Video und Bild können während der Konversation nicht gleichzeitig vorhanden sein. Es wird empfohlen, den Vorgang nach jeder Konversation zu löschen.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{glmvteam2025glm41vthinkingversatilemultimodalreasoning,
title={GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={GLM-V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Wenkai Li and Wei Jia and Xin Lyu and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuxuan Zhang and Zhanxiao Du and Zhenyu Hou and Zhao Xue and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.