Command Palette
Search for a command to run...
PlayDiffusion: Open Source-Modell Zur Lokalen Audiobearbeitung
Datum
Größe
1.35 MB
Tags
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

Hauptmerkmale:
- Partielle Audiobearbeitung: unterstützt das teilweise Ersetzen, Ändern oder Löschen von Audiodaten, ohne das gesamte Audiosegment neu zu generieren, sodass die Stimme natürlich und nahtlos bleibt.
- Effizientes TTS: Beim Maskieren des gesamten Audios ist die Inferenzgeschwindigkeit als effizientes TTS-Modell 50-mal schneller als bei herkömmlichem TTS und die Natürlichkeit und Konsistenz der Sprache sind besser.
- Sprachkontinuität wahren: Bewahren Sie beim Bearbeiten den Kontext, um Sprachkontinuität und eine einheitliche Klangfarbe des Sprechers sicherzustellen.
- Dynamische Stimmmodifikation: Passen Sie Aussprache, Ton und Rhythmus der Stimme automatisch an den neuen Text an, geeignet für Szenarien wie Echtzeit-Interaktion.
Technisches Prinzip:
- Audiokodierung: Kodiert die Eingangs-Audiosequenz in eine diskrete Token-Sequenz, wobei jedes Token eine Audioeinheit darstellt. Gilt für echte Sprache und von Text-to-Speech-Modellen generiertes Audio.
- Maskenverarbeitung: Wenn ein Teil des Audios geändert werden muss, markieren Sie den Teil als Maske, um die nachfolgende Verarbeitung zu erleichtern.
- Rauschunterdrückung mit Diffusionsmodell: Rauschunterdrückung des maskierten Bereichs basierend auf einem Diffusionsmodell, das den Text aktualisiert. Das Diffusionsmodell generiert eine hochwertige Sequenz von Audio-Tokens durch schrittweise Rauschunterdrückung. Alle Tokens werden gleichzeitig mit einer nicht-autoregressiven Methode generiert und anhand einer festen Anzahl von Rauschunterdrückungsschritten verfeinert.
- Dekodierung in Audiowellenform: Die generierte Token-Sequenz wird basierend auf dem BigVGAN-Decodermodell wieder in eine Sprachwellenform umgewandelt, um sicherzustellen, dass die endgültige Ausgabesprache natürlich und kohärent ist.
Dieses Tutorial verwendet eine einzelne RTX A6000-Rechenressource und bietet drei Testbeispiele: Inpaint, Text-to-Speech und Sprachkonvertierung. Dieses Tutorial unterstützt nur Englisch.
2. Effektanzeige
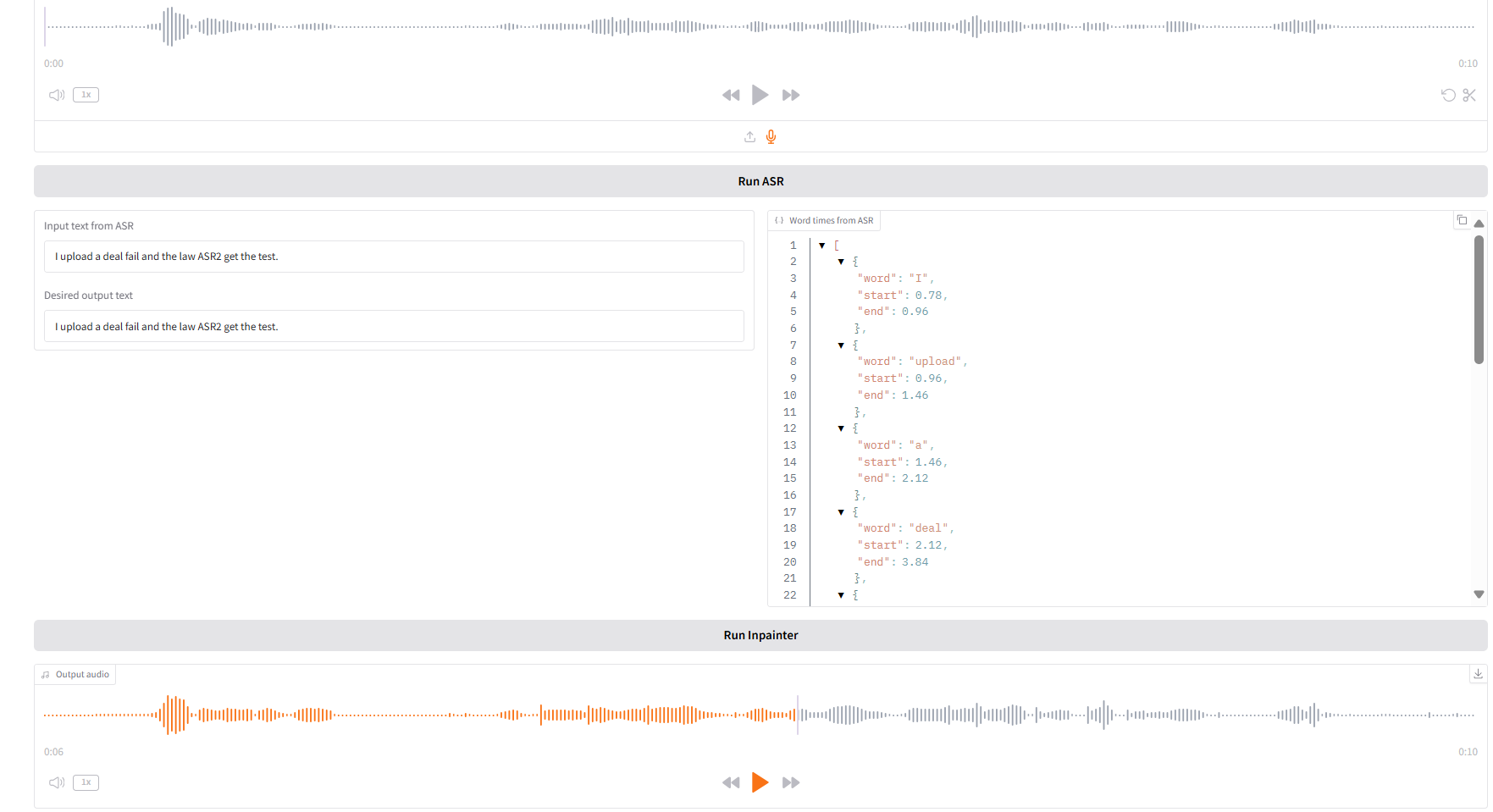
1. Inpaint
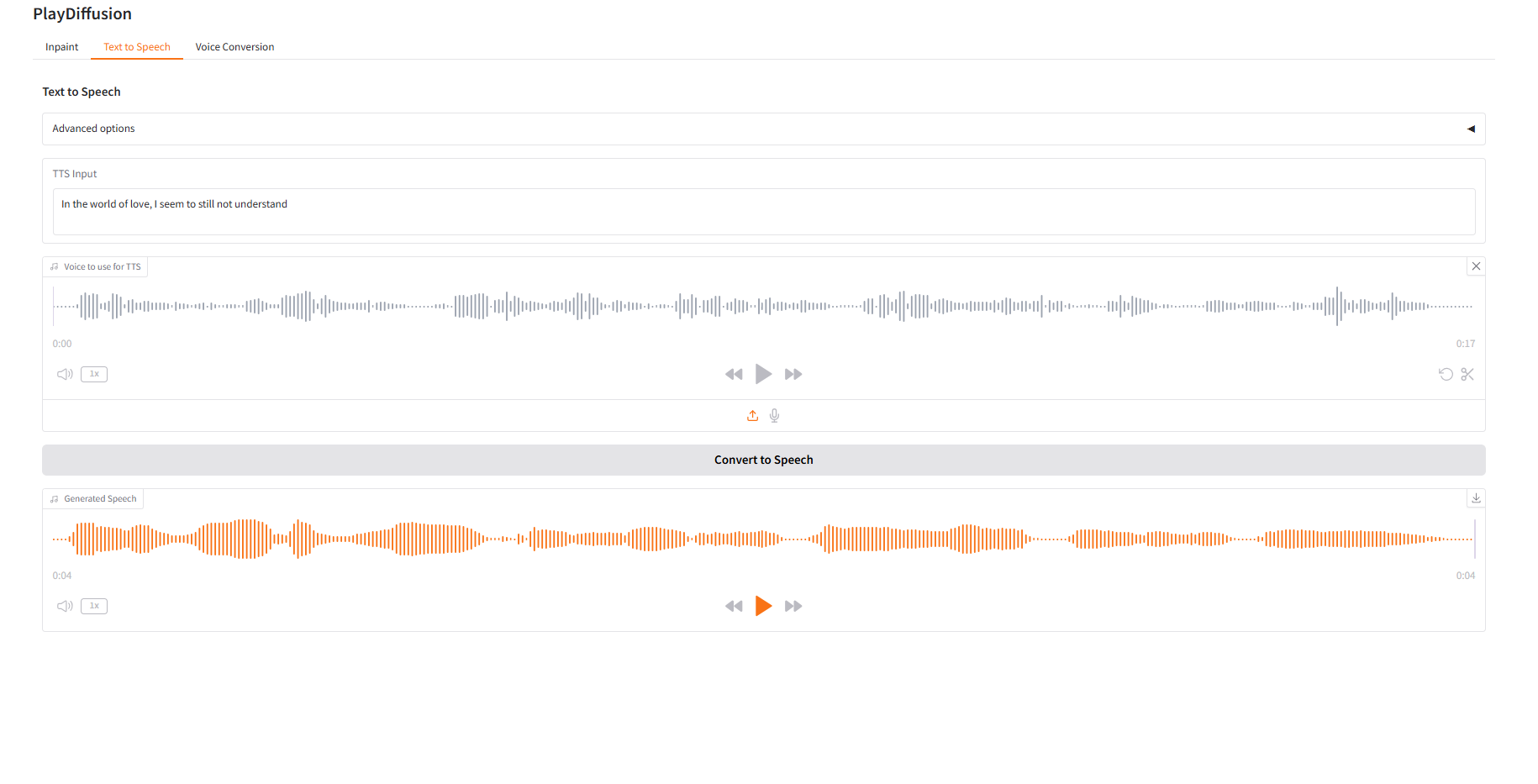
2. Text-to-Speech
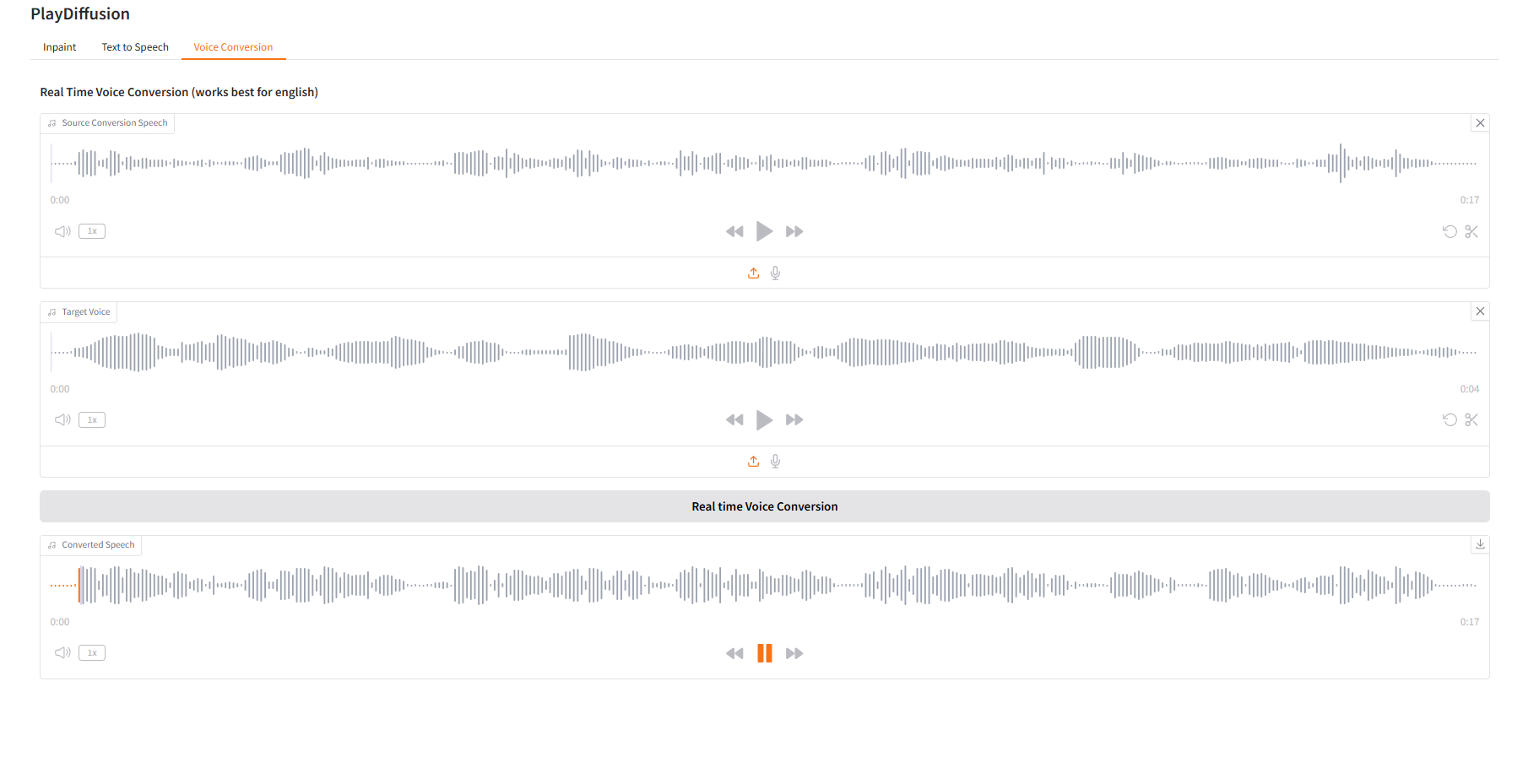
3. Sprachkonvertierung
3. Bedienungsschritte
1. Starten Sie den Container
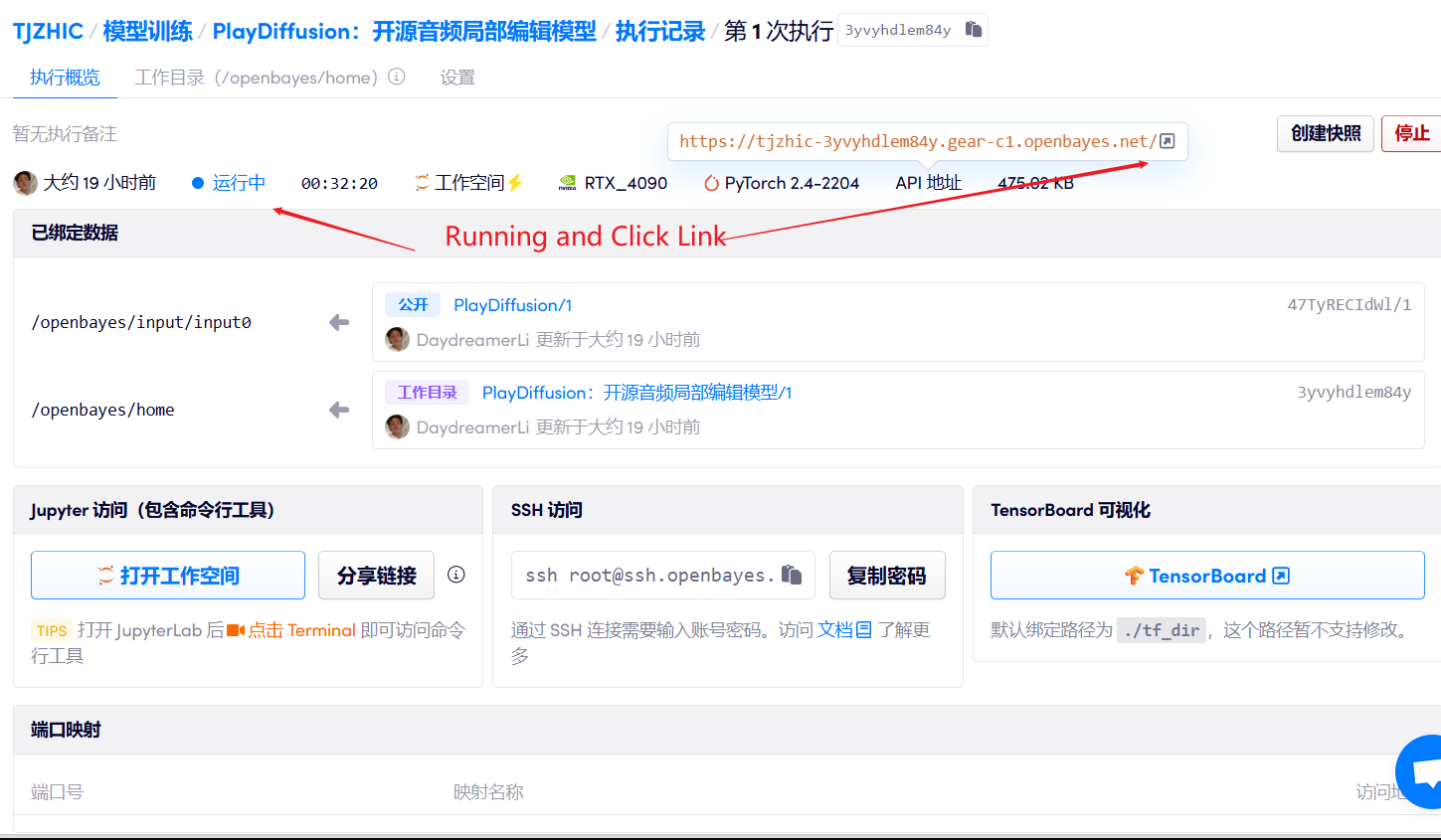
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
1. Inpaint
Dieses Modul kann Audio teilweise ersetzen, ändern oder löschen, ohne das gesamte Audio neu zu generieren, sodass die Sprache natürlich und nahtlos bleibt.
- Laden Sie das Original-Audio hoch, klicken Sie zum Ausführen auf „SAR ausführen“ und ändern und bearbeiten Sie dann den Audioinhalt, den Sie unter „Gewünschter Ausgabetext“ ausgeben möchten.
- Klicken Sie dann auf „Inpainter ausführen“, um das bearbeitete Audio zu generieren.
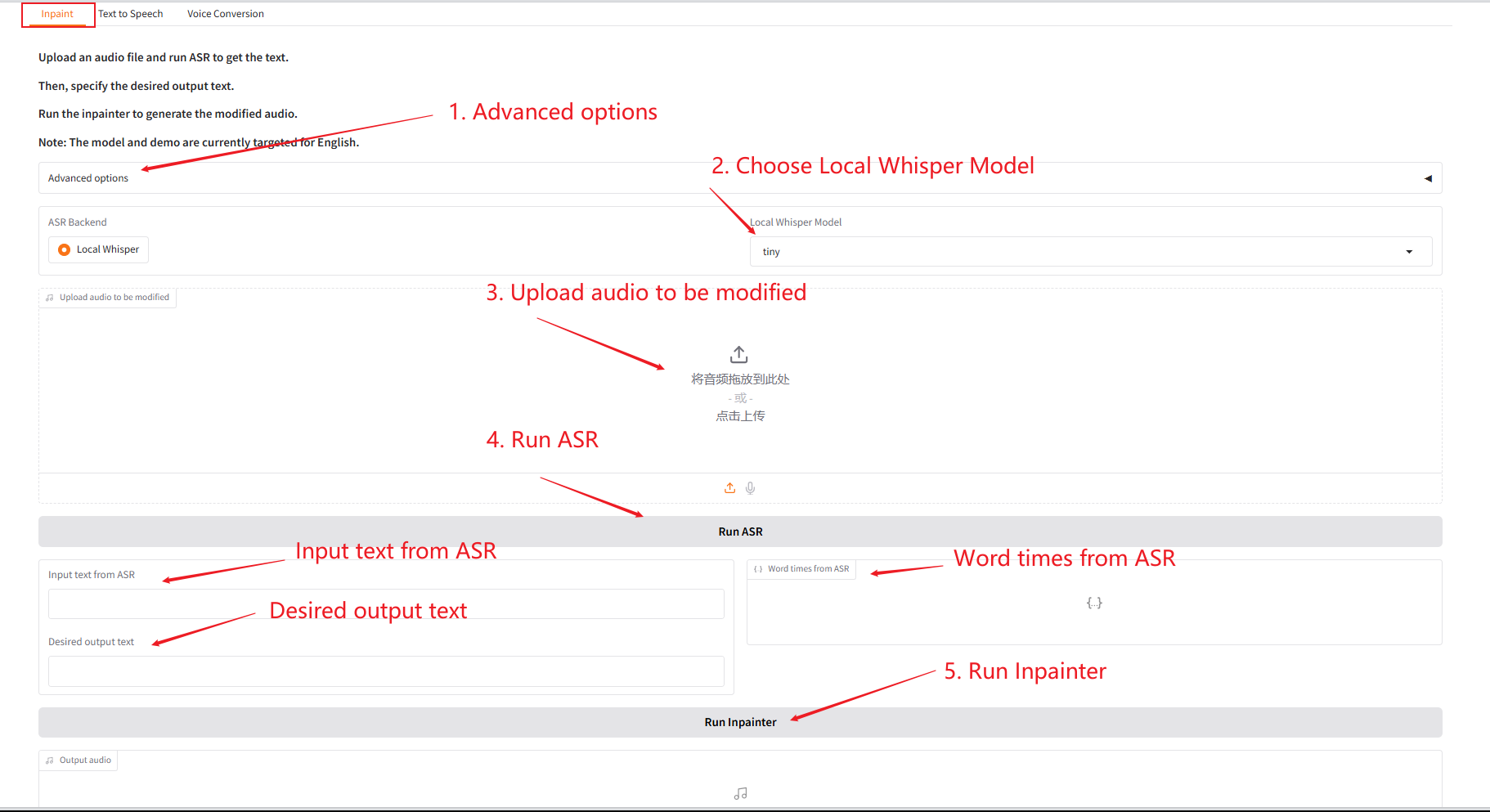
Parameterbeschreibung:
- Anzahl der Sampling-Schritte: Die Anzahl der Iterationen im Diffusionsmodell-Generierungsprozess. Je mehr Schritte, desto höher die Generierungsqualität, aber auch desto länger die Zeit.
- Codebuch: Ein Wörterbuch diskreter Symbole in der Vektorquantisierungsschicht, das zum Zuordnen kontinuierlicher Merkmale zu diskreten Darstellungen verwendet wird.
- Anfangstemperatur: Ein Parameter, der die Zufälligkeit der Probenahme steuert. Je höher der Wert, desto größer die Diversität, und je niedriger der Wert, desto sicherer das Ergebnis.
- Anfängliche Diversität: Parameter, die den Grad der Variation in generierten Stichproben steuern, um die Generierung zu ähnlicher Ergebnisse zu vermeiden.
- Anleitung: Passt den Einflussgrad bedingter Informationen (z. B. Text) auf die generierten Ergebnisse an.
- Führungsskalierungsfaktor: Das Gewichtsverhältnis, das zum Ausgleich zwischen bedingter Führung und unbedingter Generierung verwendet wird.
- Stichprobenziehung aus den Top-k-Logits: Wählen Sie nur aus den K Kandidaten mit der höchsten Wahrscheinlichkeit aus, um die Generierungsqualität zu verbessern.
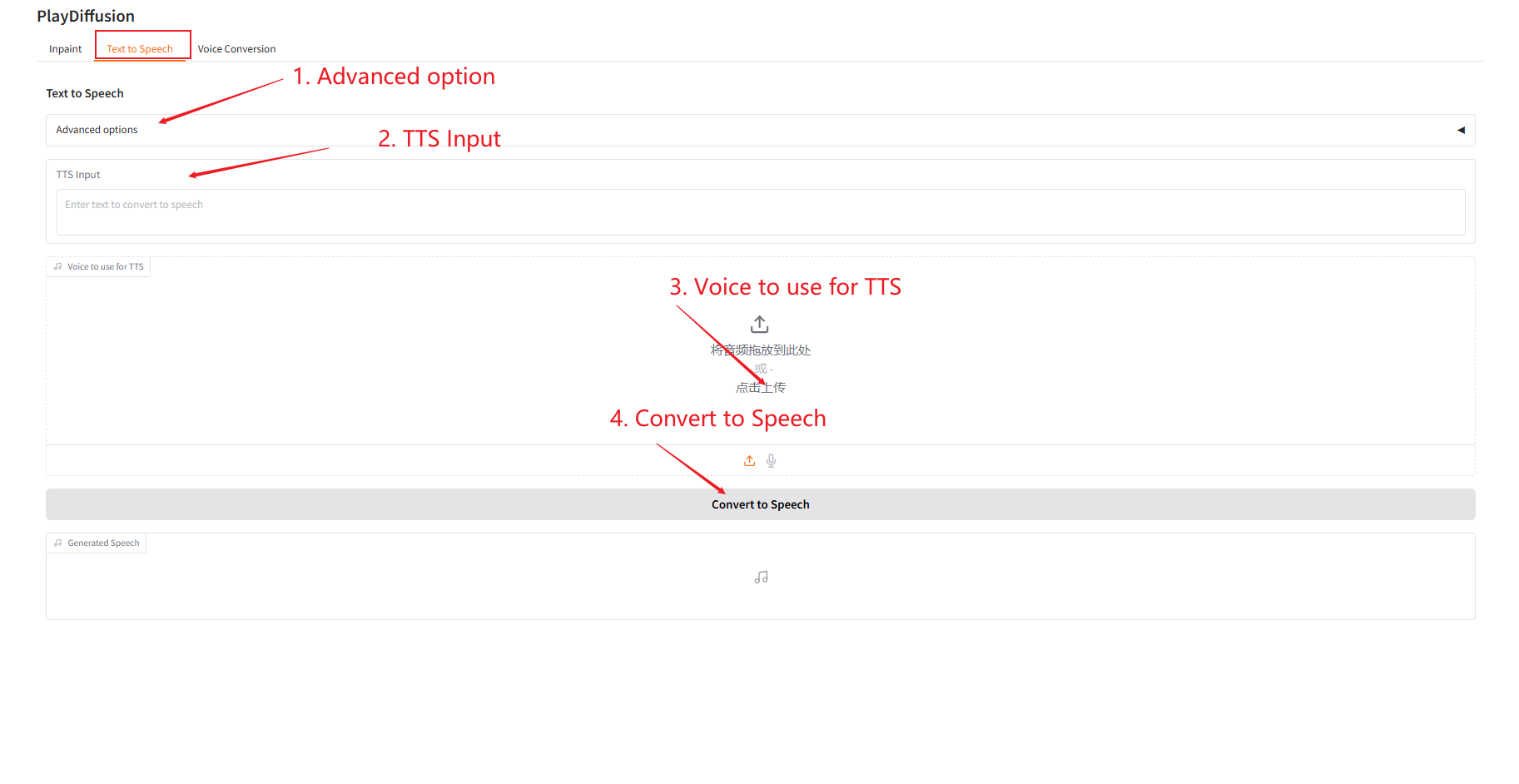
2. Text-to-Speech
Als effizientes TTS-Modell ist seine Inferenzgeschwindigkeit 50-mal schneller als bei herkömmlichem TTS und seine Sprachnatürlichkeit und -konsistenz sind besser.
- Geben Sie in „TTS-Eingabe“ den Textinhalt ein, für den Sie Audio generieren möchten, und laden Sie dann das Zielaudio hoch.
- Klicken Sie dann auf „In Sprache konvertieren“, um Audio zu generieren.
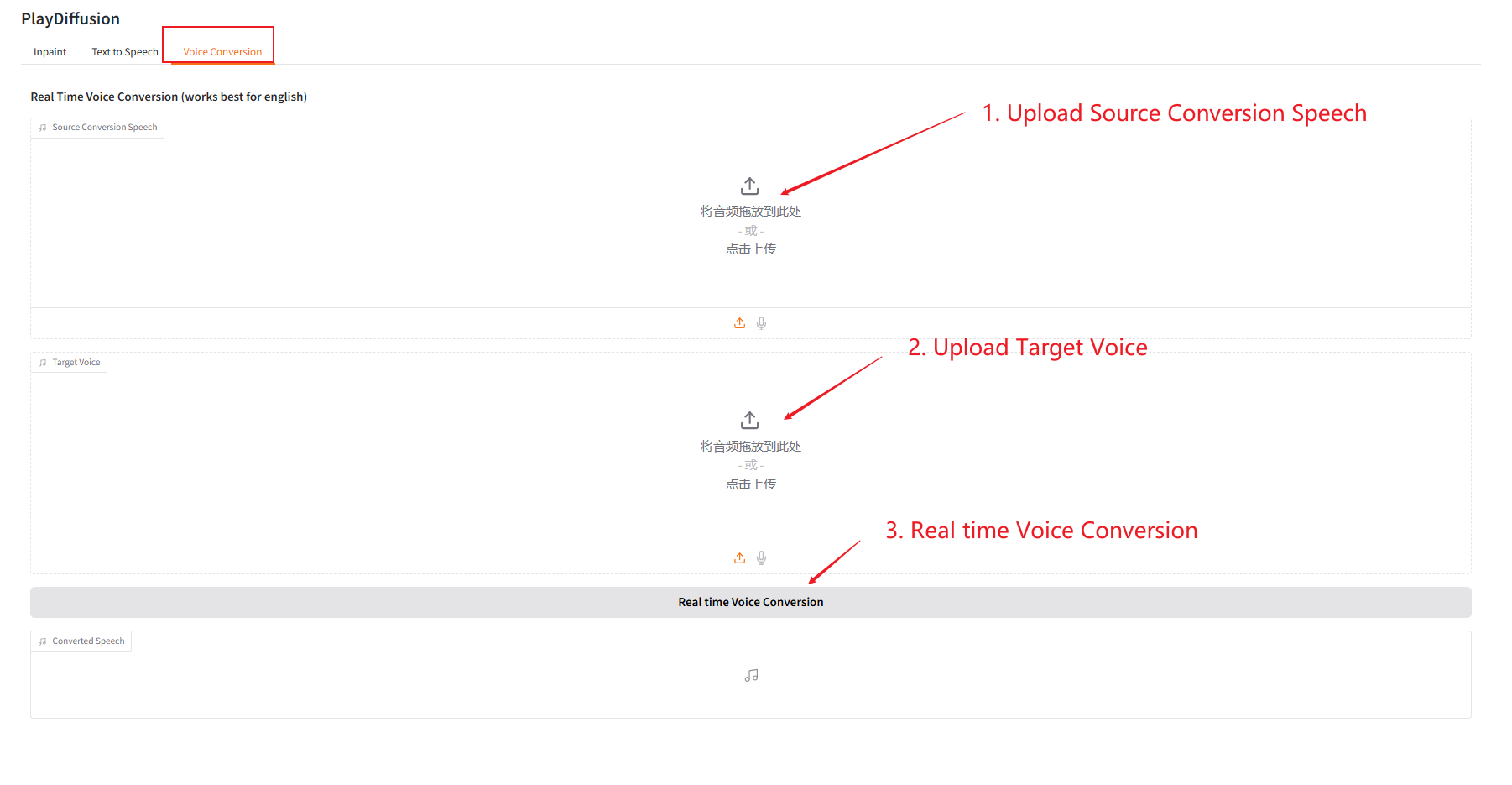
3. Sprachkonvertierung
Passen Sie den Sprachinhalt dynamisch an und Sie können den ursprünglichen Audioinhalt direkt in die Zielklangfarbe klonen.
- Laden Sie den Original-Audiodaten hoch und laden Sie dann den Ziel-Audiodaten hoch.
- Klicken Sie dann auf „Echtzeit-Sprachkonvertierung“, um den ursprünglichen Audioinhalt des Zieltons direkt zu generieren.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.