Command Palette
Search for a command to run...
Bereitstellung Von VideoLLaMA3-7B Mit Einem Klick
Datum
Größe
2.09 GB
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial


Dieses Tutorial verwendet eine einzelne RTX 4090-Rechenressource, stellt das Modell VideoLLaMA3-7B-Image bereit und bietet zwei Beispiele zum Verstehen von Videos und Bildern. Darüber hinaus bietet es vier Notebook-Skript-Tutorials zu den Themen „Einzelbildverständnis“, „Mehrbildverständnis“, „Visueller Referenzausdruck und -positionierung“ und „Videoverständnis“.
VideoLLaMA3 ist ein multimodales Basismodell, das im Februar 2025 vom Alibaba DAMO Academy Natural Language Processing Team (DAMO-NLP-SG) als Open Source veröffentlicht wurde und sich auf Bild- und Videoanalyseaufgaben konzentriert. Dank einer bildzentrierten Architektur und hochwertiger Datenaufbereitung verbessert es die Genauigkeit und Effizienz der Videoanalyse signifikant. Die schlanke Version (2B) eignet sich für den Einsatz in Edge-Systemen, während das 7B-Modell Spitzenleistung für Forschungsanwendungen bietet. Das 7B-Modell erzielt in drei Hauptaufgaben Bestleistungen: allgemeine Videoanalyse, zeitliches Schließen und Analyse langer Videos. Zugehörige Forschungsarbeiten sind verfügbar. VideoLLaMA 3: Frontier Multimodal Foundation Models für Bild- und Videoverständnis .
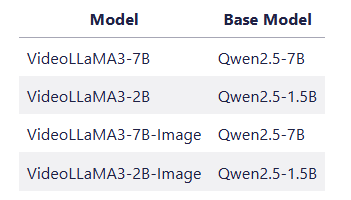
👉 Das Projekt bietet 4 Modellmodelle:
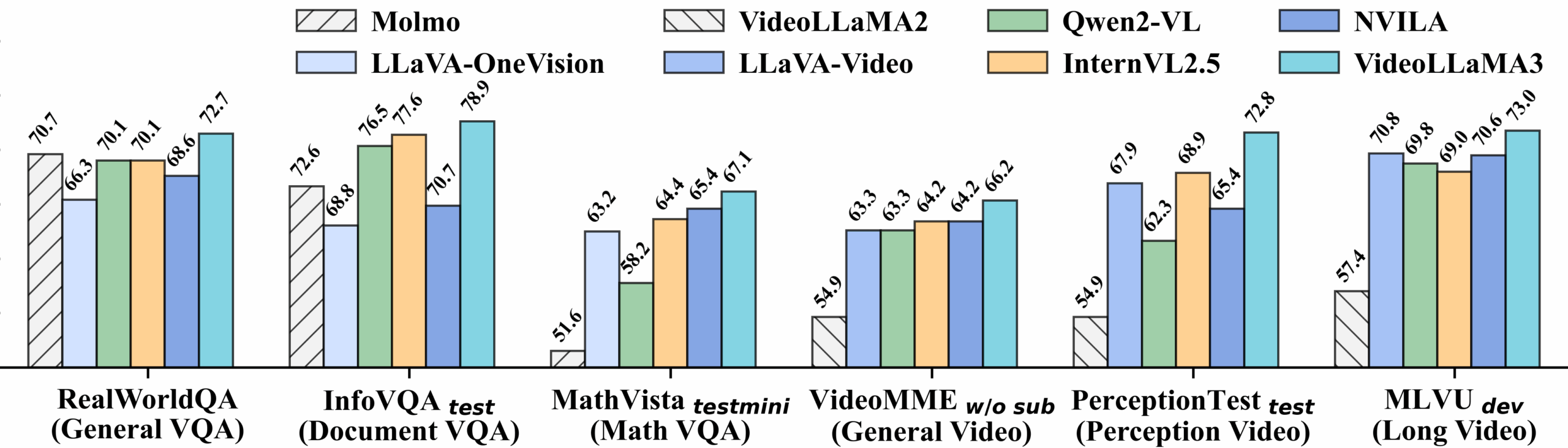
Detaillierte Leistung des Video-Benchmarks:
Sehen Sie sich die detaillierte Leistung der Bild-Benchmarks an:
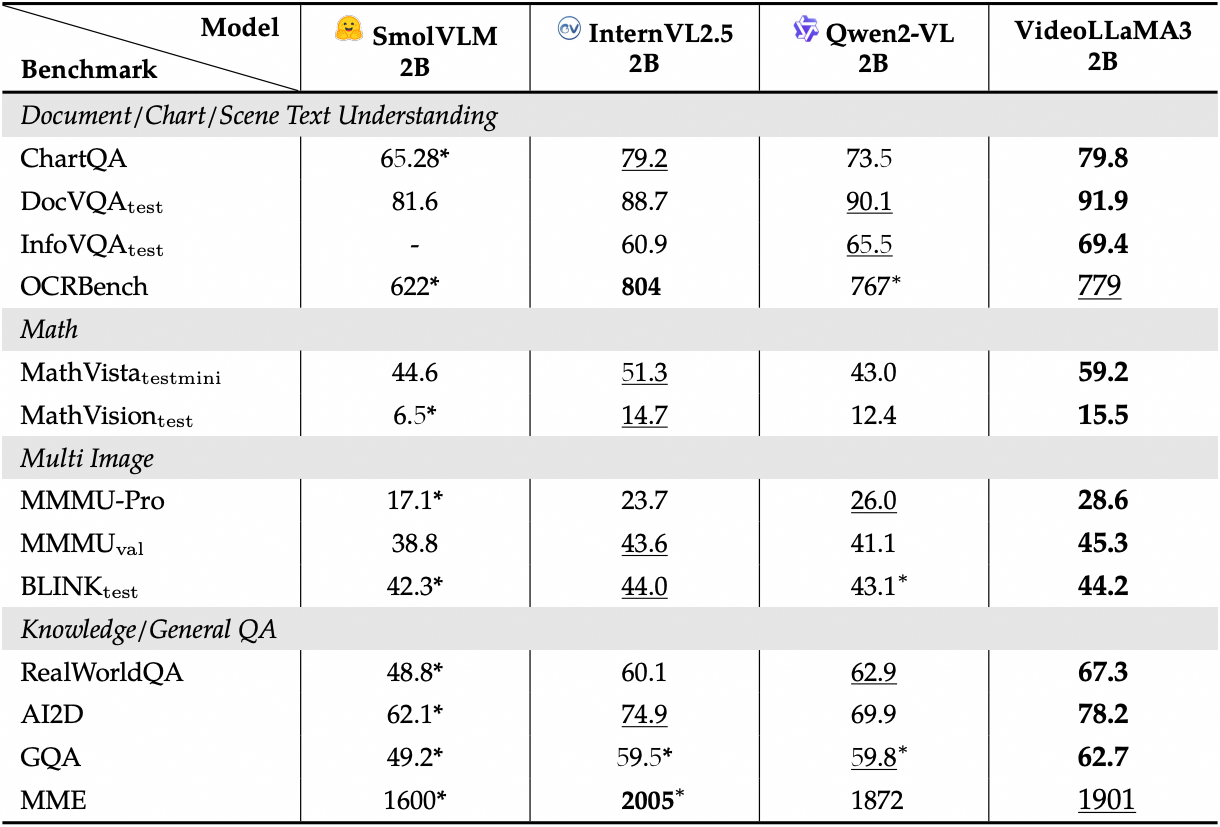
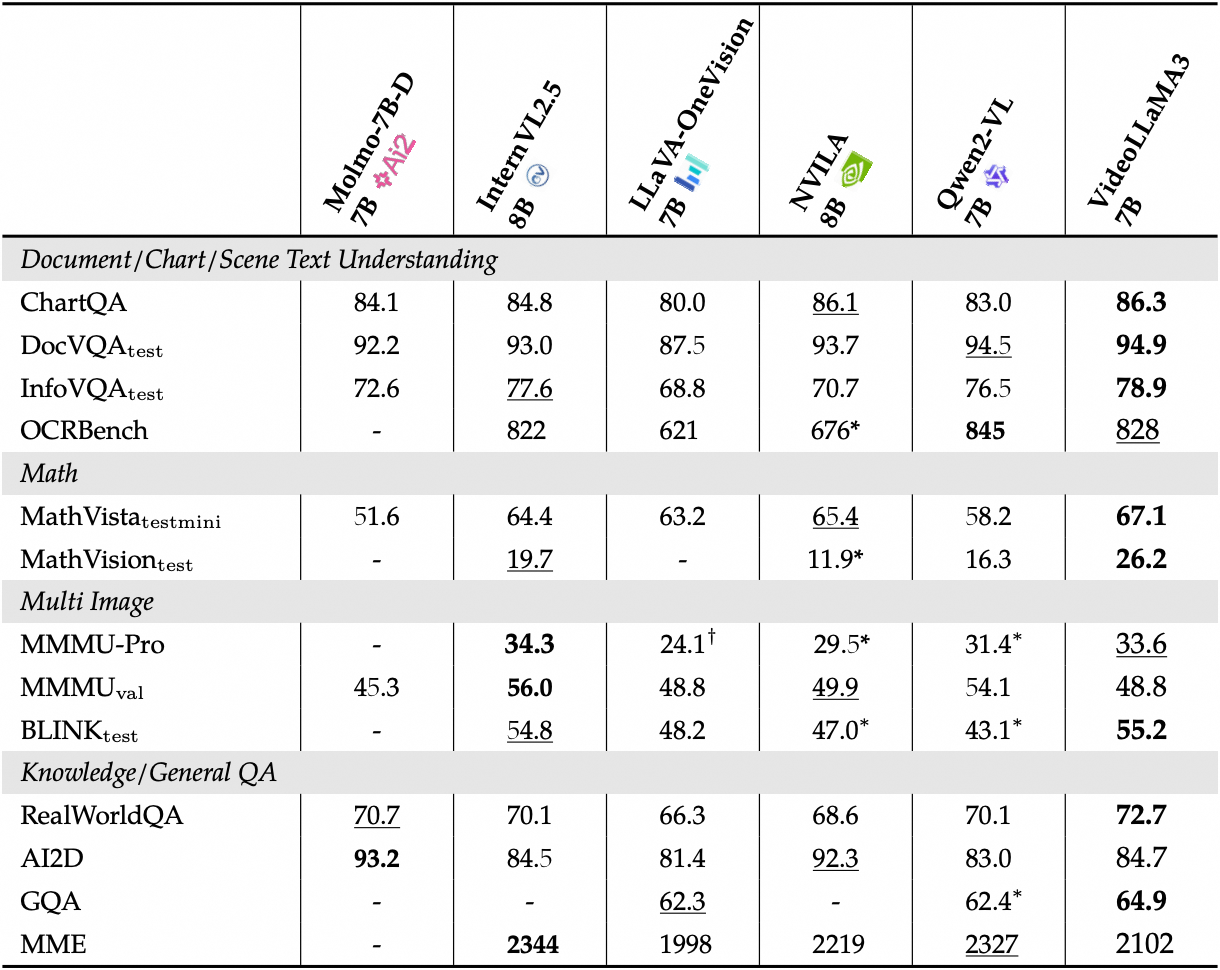
2. Bedienungsschritte
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
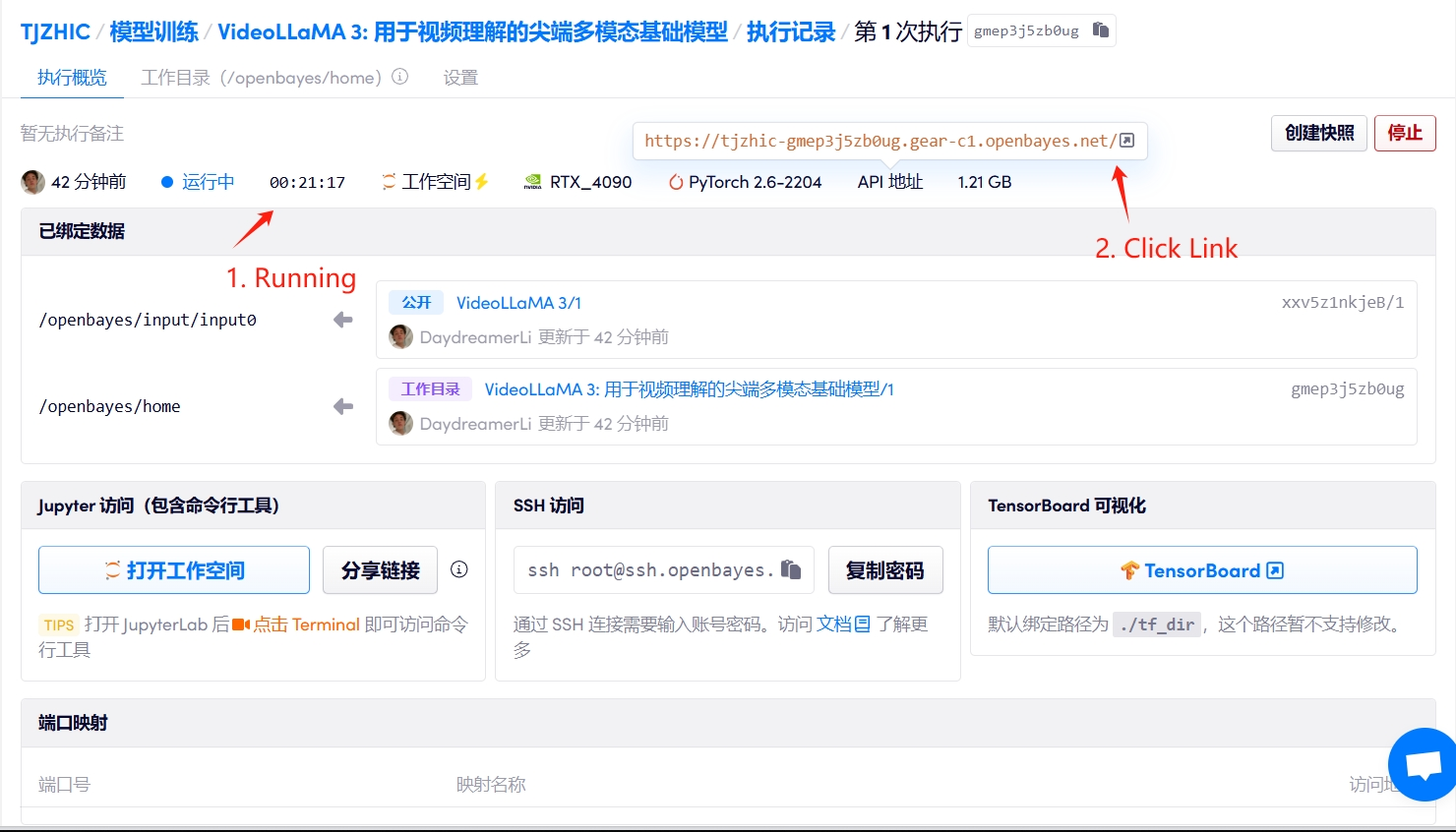
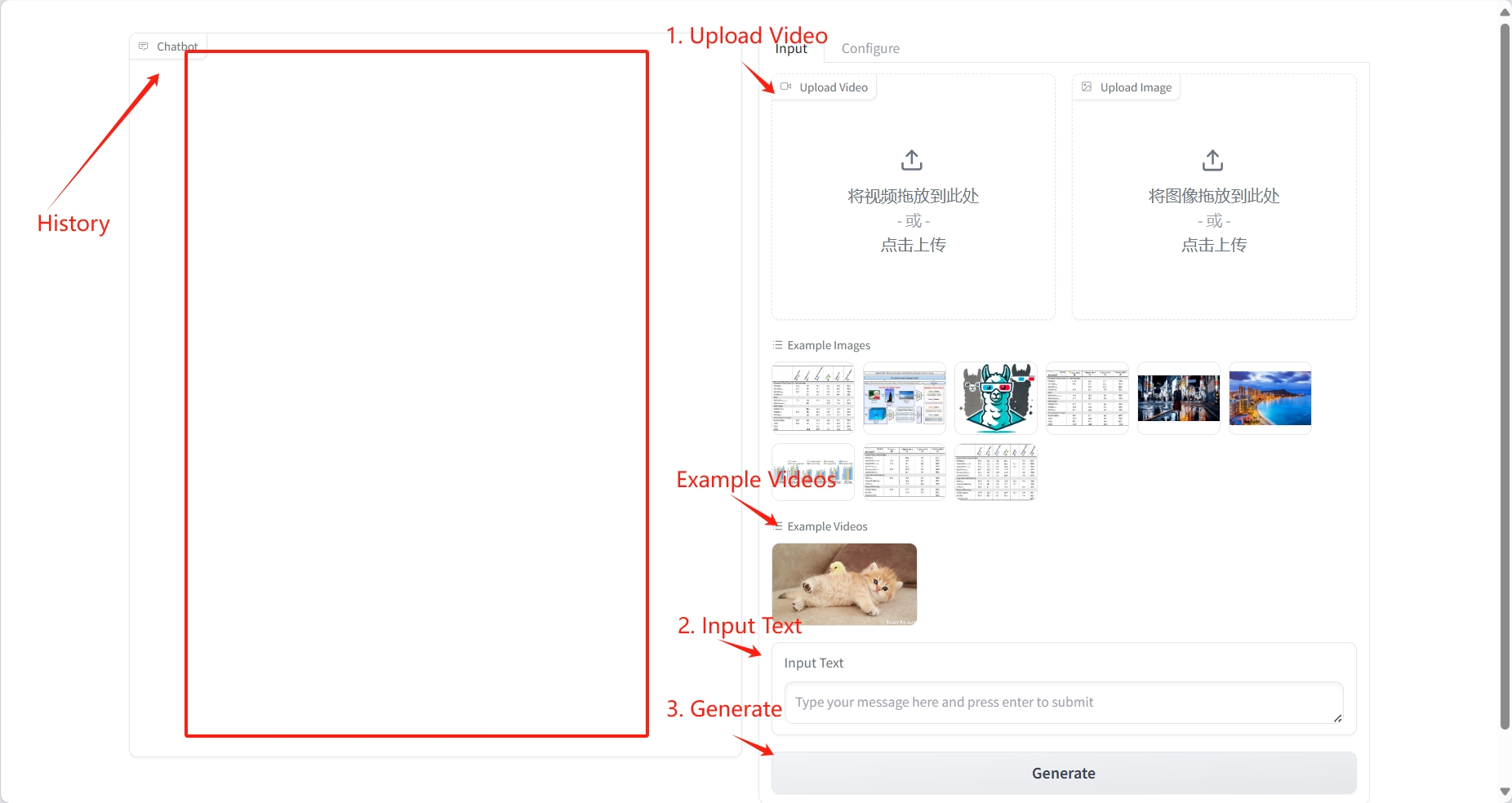
2. Anwendungsschritte
Videoverständnis
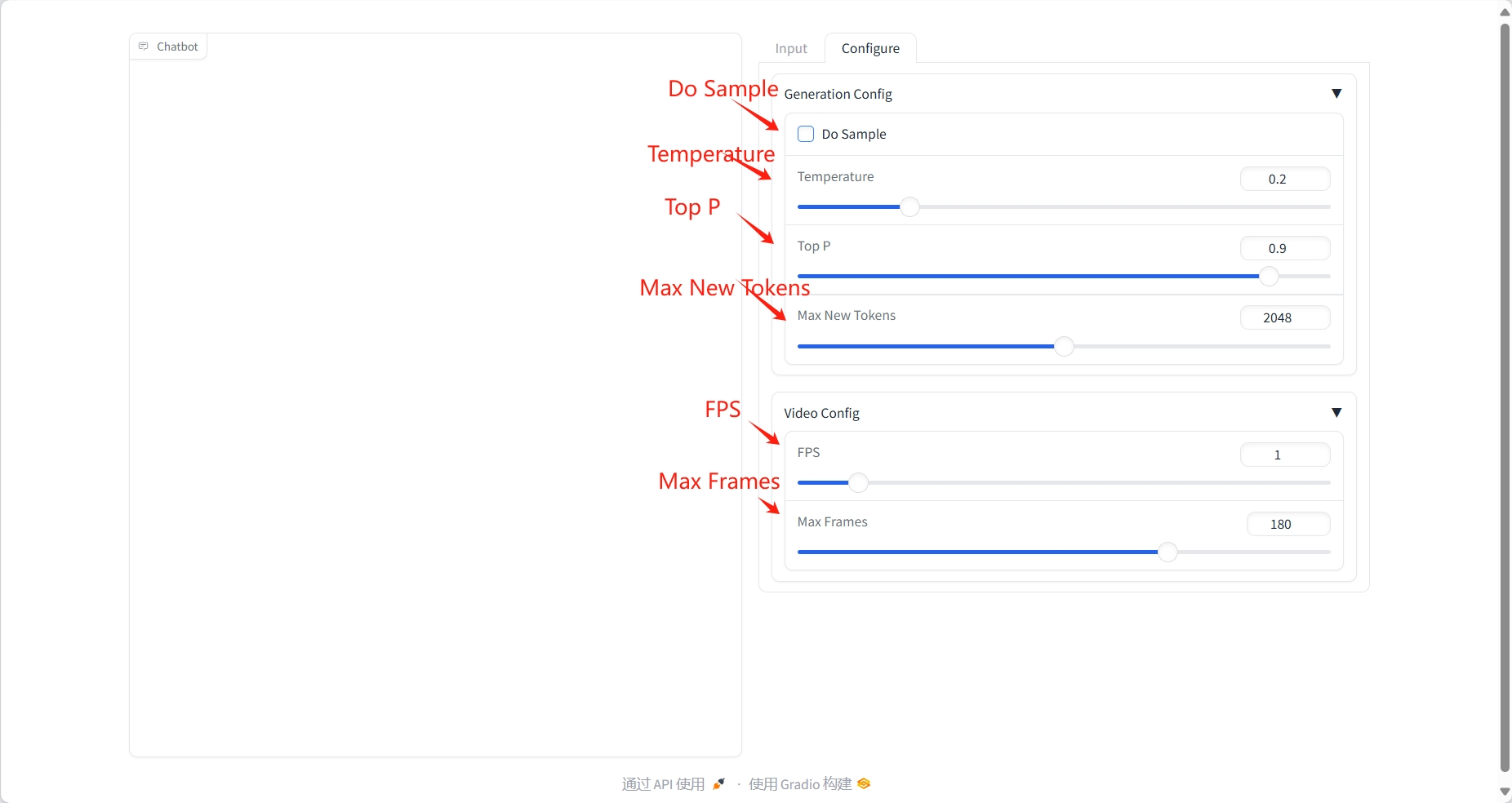
Ergebnis
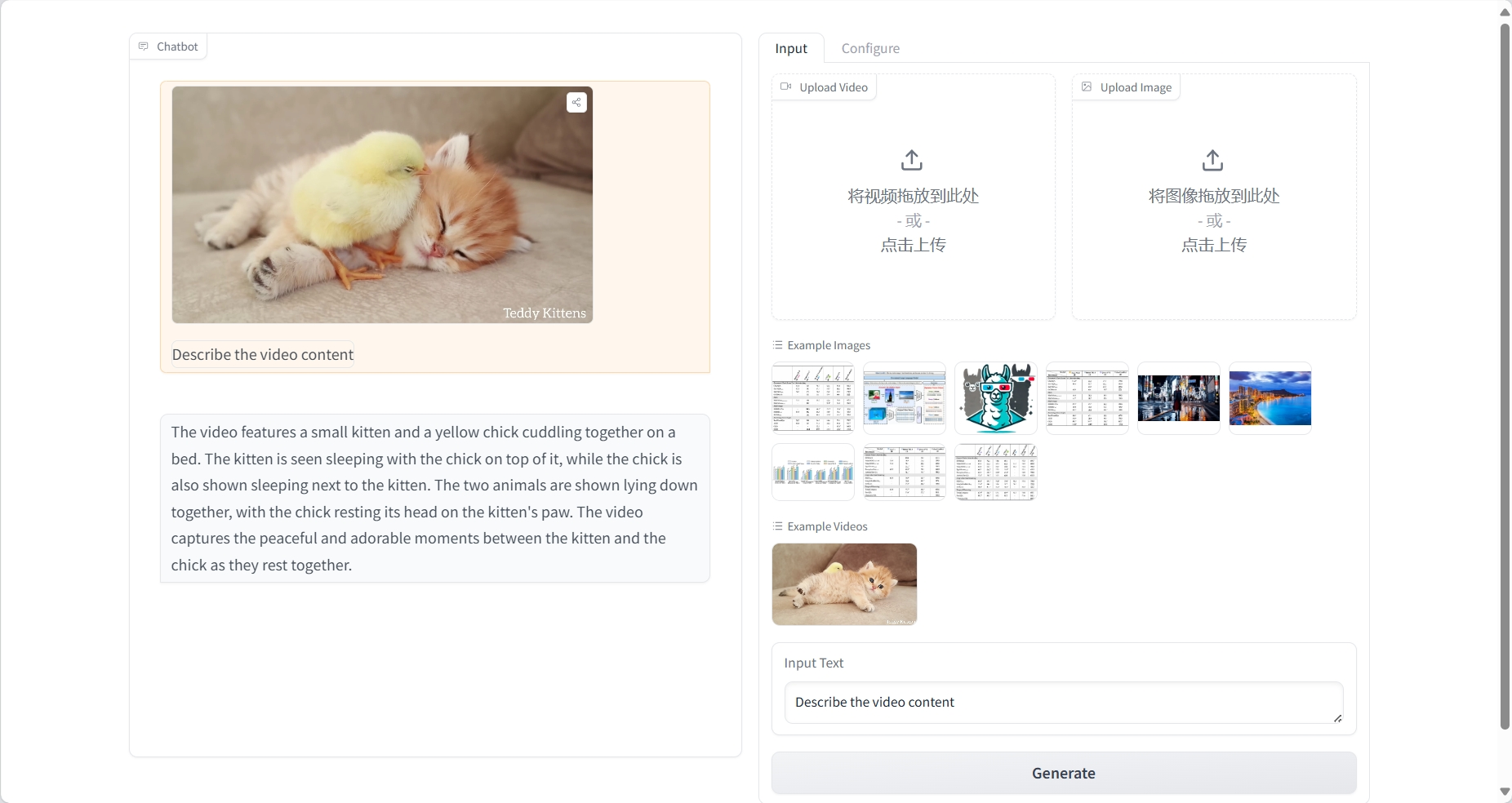
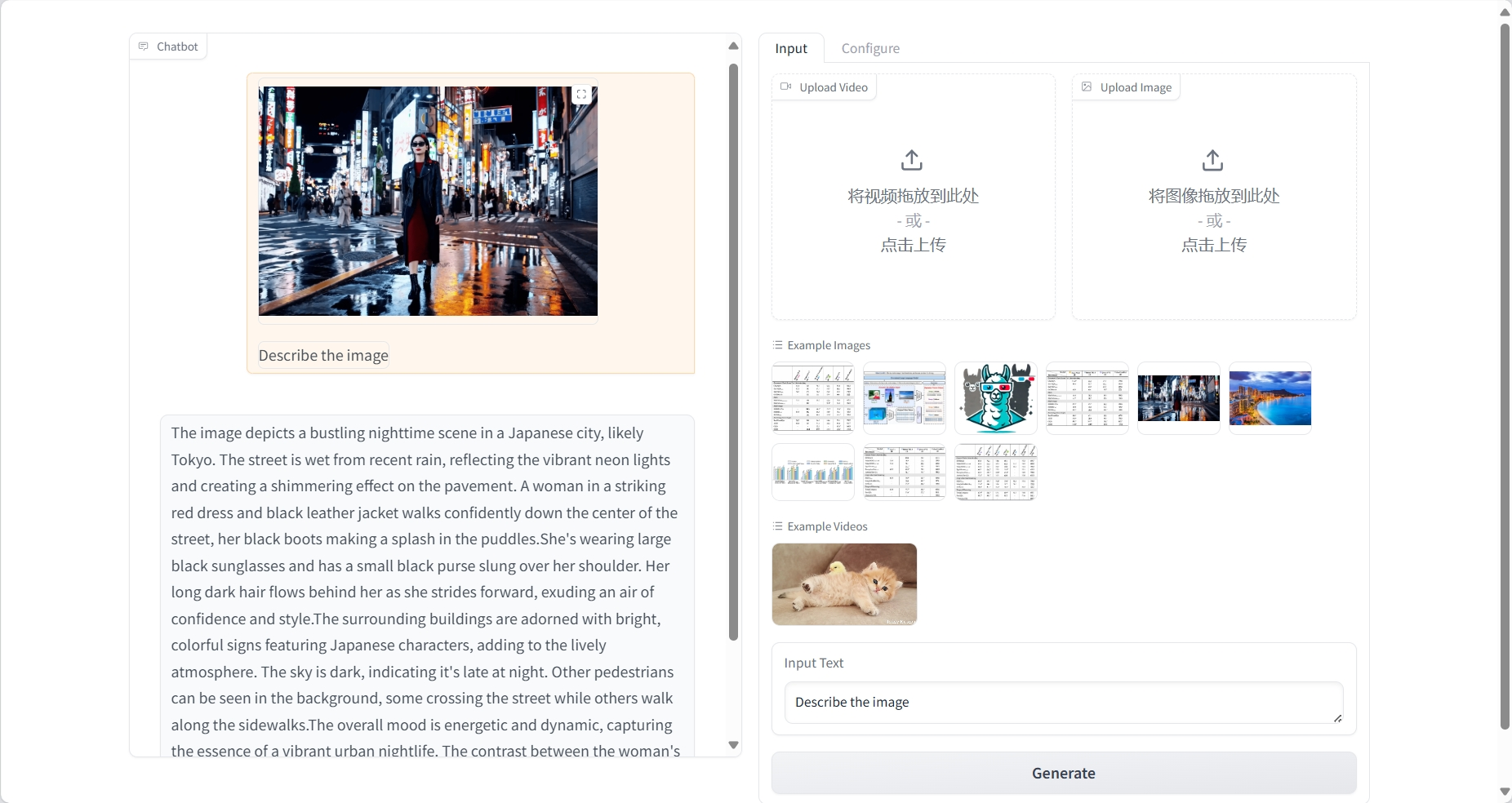
Bildverständnis
Ergebnis
3. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{damonlpsg2025videollama3,
title={VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding},
author={Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao},
journal={arXiv preprint arXiv:2501.13106},
year={2025},
url = {https://arxiv.org/abs/2501.13106}
}
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.