Command Palette
Search for a command to run...
Sa2VA: Auf Dem Weg Zum Dichten Perzeptuellen Verständnis Von Bildern Und Videos
Datum
Größe
465.62 MB
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

Sa2VA, ein Gemeinschaftsprojekt von Forschungsteams der UC Merced, ByteDance Seed, der Wuhan-Universität und der Peking-Universität, wurde am 7. Januar 2025 veröffentlicht. Sa2VA ist das erste einheitliche Modell für das umfassende perzeptuelle Verständnis von Bildern und Videos. Im Gegensatz zu bestehenden multimodalen Sprachmodellen, die typischerweise auf bestimmte Modalitäten und Aufgaben beschränkt sind, unterstützt Sa2VA ein breites Spektrum an Bild- und Videoaufgaben, darunter algebraische Segmentierung und Dialogverarbeitung, und erfordert nur minimale Feinabstimmung einzelner Anweisungen. Die zugehörigen Forschungsergebnisse sind wie folgt: Sa2VA: Kombination von SAM2 und LLaVA für ein umfassendes Verständnis von Bildern und Videos .
Dieses Tutorial verwendet Ressourcen für eine einzelne Karte A6000.
2. Projektbeispiele



3. Bedienungsschritte
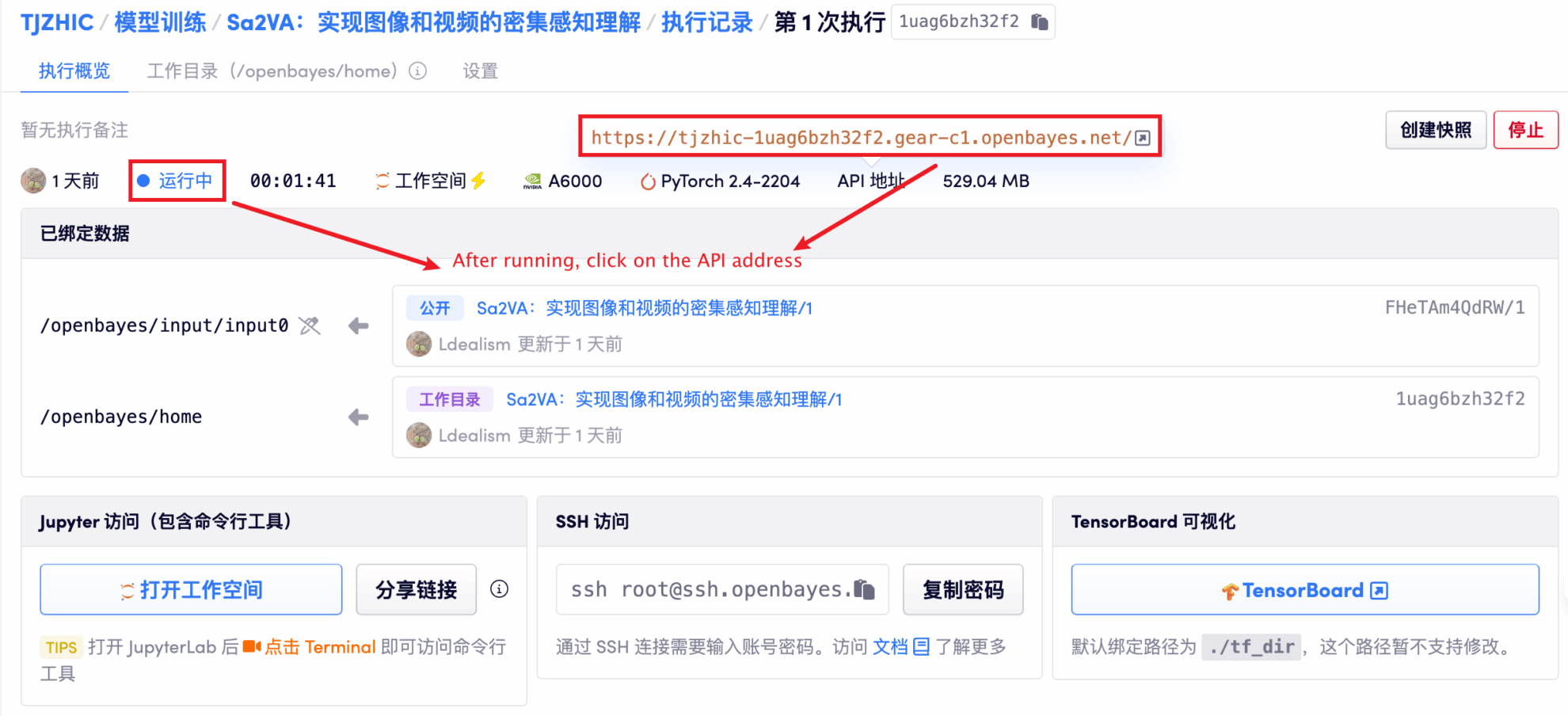
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
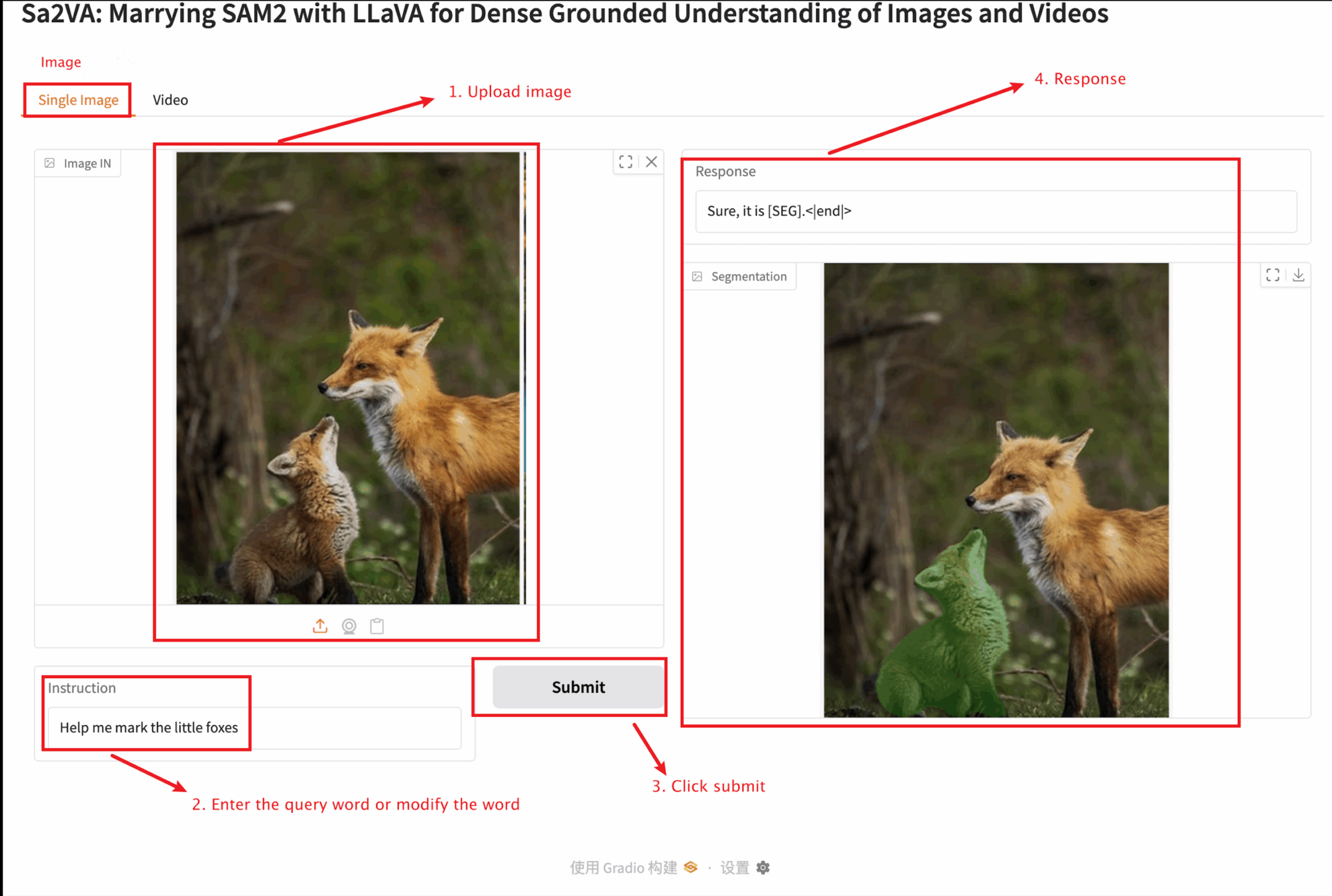
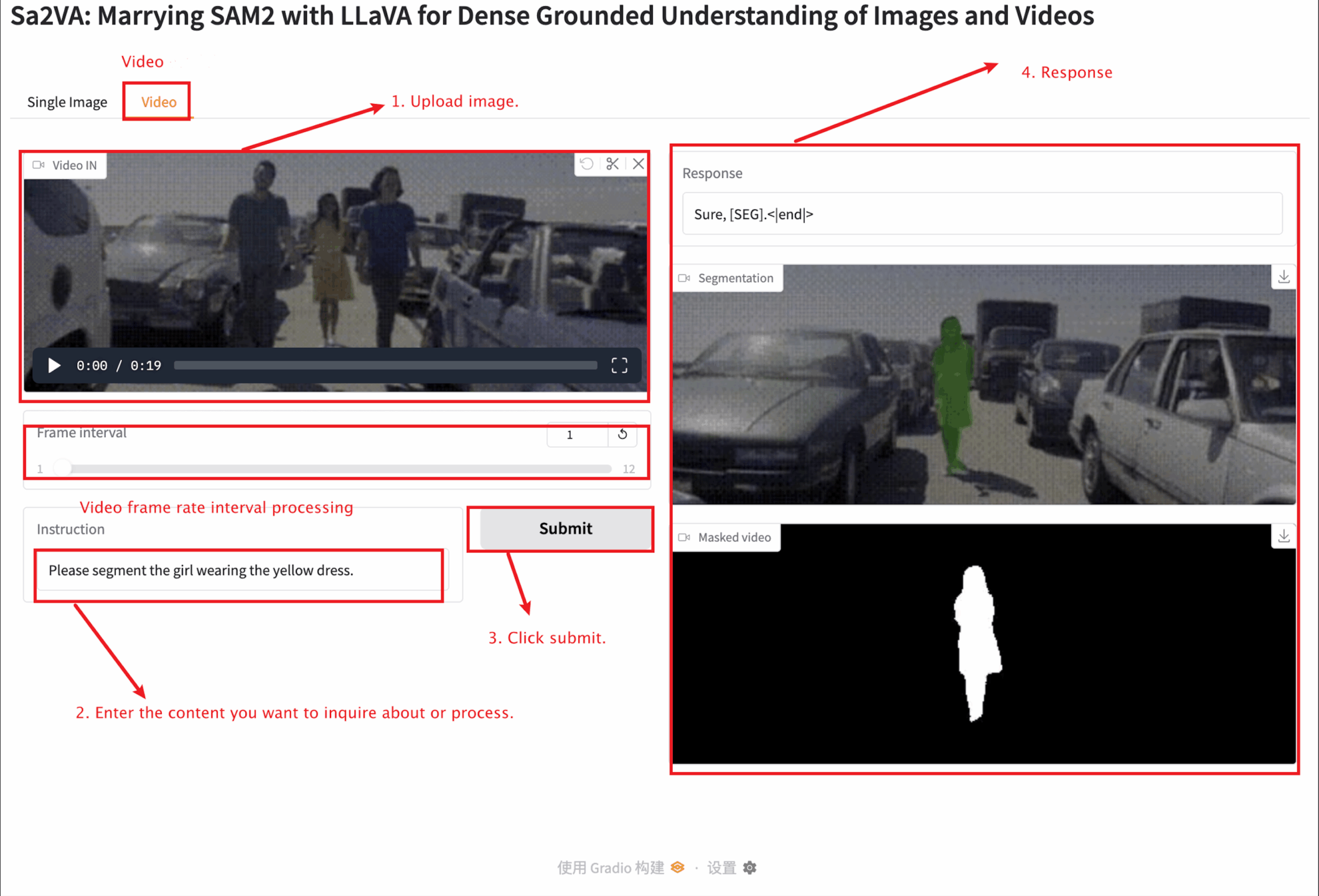
2. Sobald Sie die Webseite betreten, können Sie mit dem Modell interagieren
Dieses Tutorial bietet zwei Modultests: Einzelbild- und Videomodule.
Die Größe des hochgeladenen Bildes sollte 10 MB nicht überschreiten, die Länge des hochgeladenen Videos sollte 1 Minute nicht überschreiten und die Videogröße sollte 50 MB nicht überschreiten, da es sonst dazu kommen kann, dass das Modell langsam läuft oder Fehler meldet.
Wichtige Parameterbeschreibung:
Einzelbild
Video
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

V. Zitationsinformationen
Dank an den Github-Benutzer zhangjunchang Für die Bereitstellung dieses Lernprogramms lauten die Projektreferenzinformationen wie folgt:
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.