Dieses Tutorial verwendet eine A6000 mit einer einzelnen Karte als Ressource. Derzeit unterstützt die KI-Interaktion nur Chinesisch und Englisch.
2. Projektbeispiele
3. Bedienungsschritte
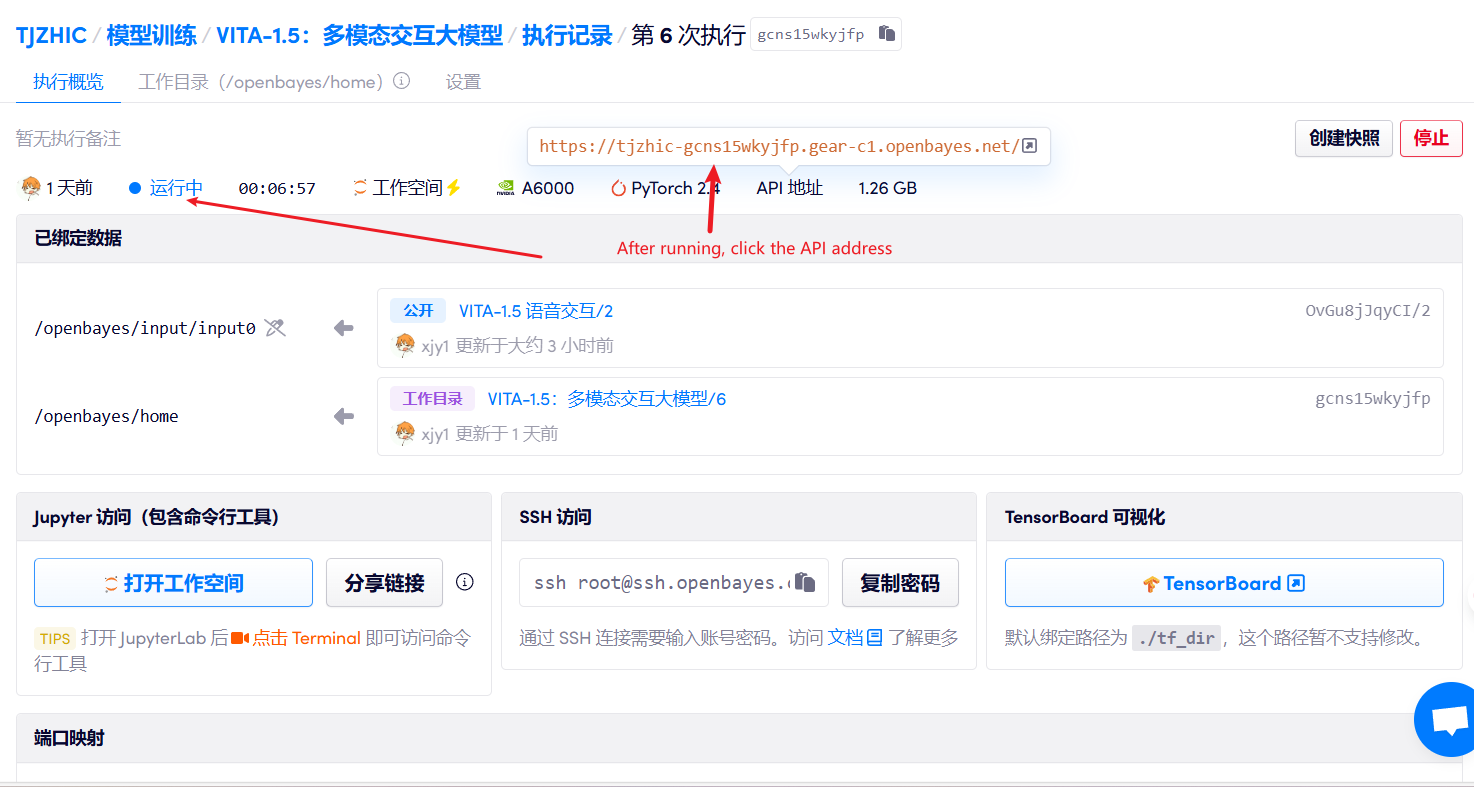
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
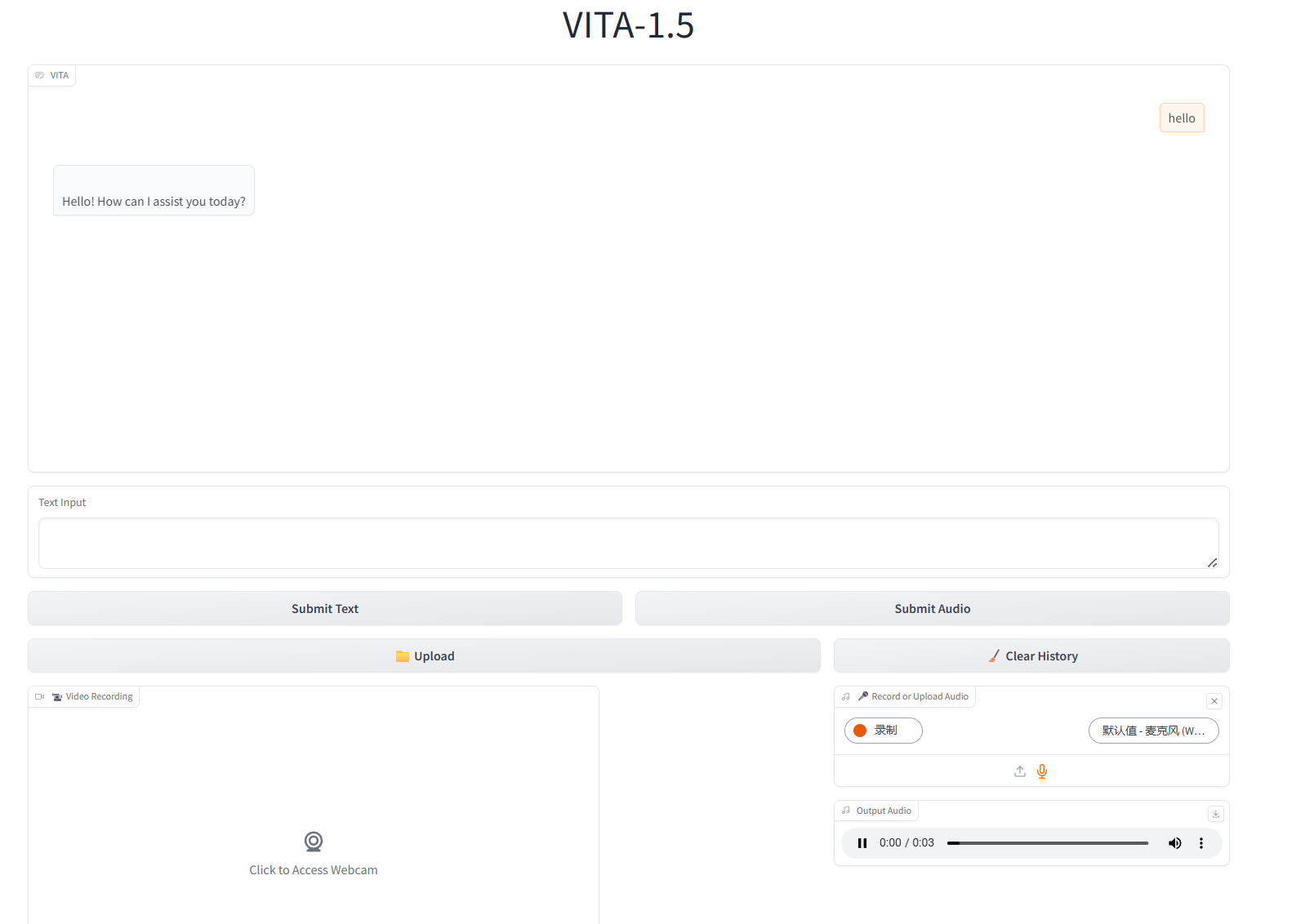
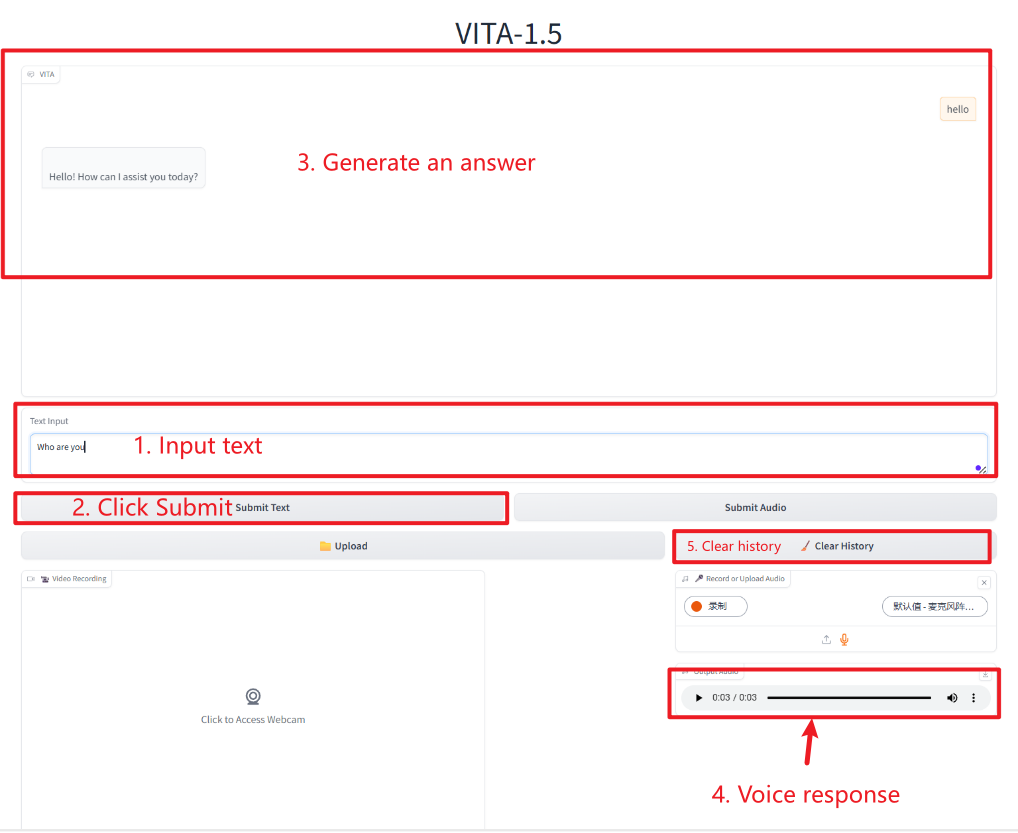
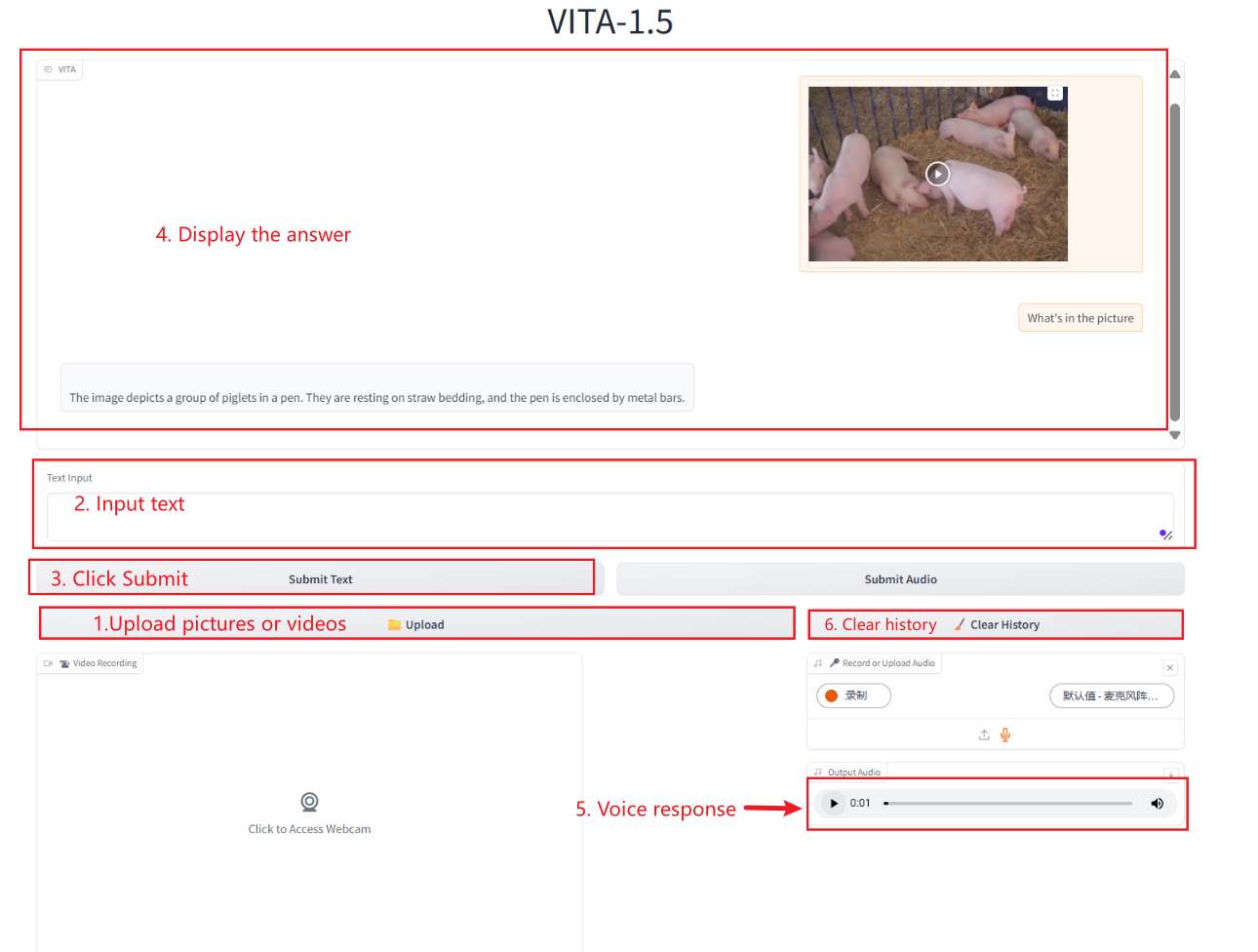
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
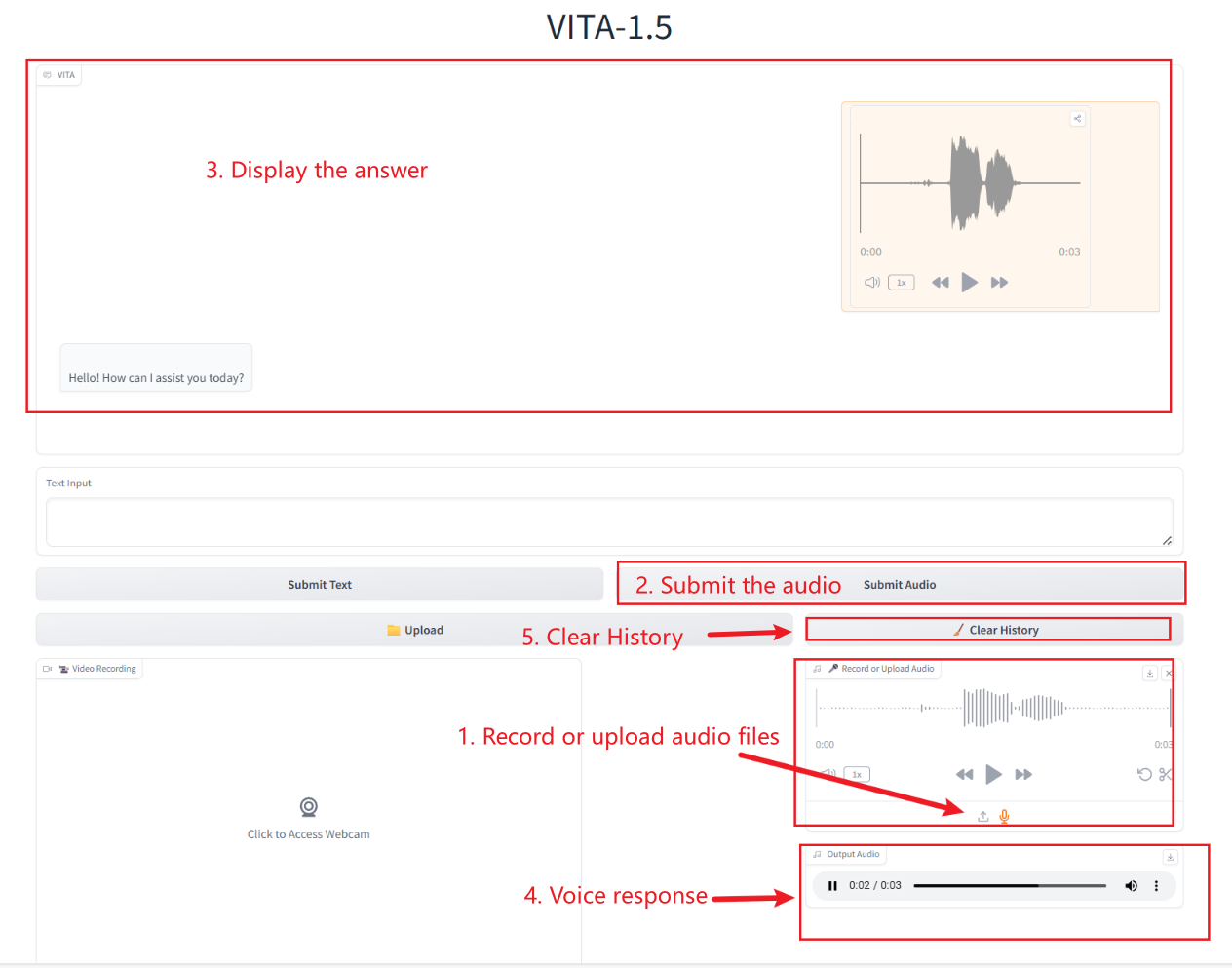
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Anwendung
Dieses Lehrbuch enthält mehrere KI-Interaktionsmethoden: Text, Audio, Video und Bilder.
Textinteraktion
Audio-Interaktion
Bild-/Video-Interaktion
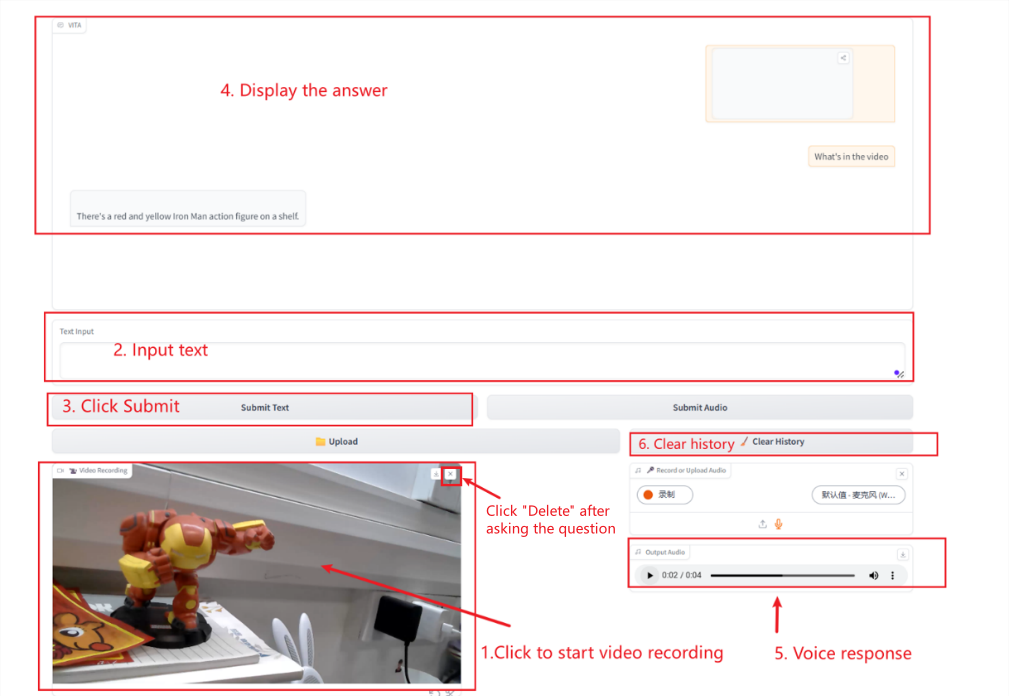
Video-Interaktion
Notiz:
Bei der Videoaufzeichnung mit einer Kamera muss das Video unmittelbar nach Abschluss der Frage gelöscht werden.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Dieses Tutorial verwendet eine A6000 mit einer einzelnen Karte als Ressource. Derzeit unterstützt die KI-Interaktion nur Chinesisch und Englisch.
2. Projektbeispiele
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Anwendung
Dieses Lehrbuch enthält mehrere KI-Interaktionsmethoden: Text, Audio, Video und Bilder.
Textinteraktion
Audio-Interaktion
Bild-/Video-Interaktion
Video-Interaktion
Notiz:
Bei der Videoaufzeichnung mit einer Kamera muss das Video unmittelbar nach Abschluss der Frage gelöscht werden.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.