Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne A6000-Karte.
Kimi-Audio-7B-Instruct ist ein Open-Source-Audio-Grundlagenmodell, das vom KimiTeam am 28. April 2025 veröffentlicht wurde. Das Modell kann verschiedene Audioverarbeitungsaufgaben in einem einzigen, einheitlichen Framework bewältigen. Zugehörige Forschungsarbeiten umfassen… Technischer Bericht von Kimi-Audio Zu den Hauptfunktionen gehören:
Allgemeine Funktionen: Bewältigt eine Vielzahl von Aufgaben wie automatische Spracherkennung (ASR), Beantwortung von Audiofragen (AQA), automatische Audiountertitelung (AAC), Sprachemotionserkennung (SER), Klassifizierung von Tonereignissen/-szenen (SEC/ASC) und End-to-End-Sprachdialog.
Branchenführende Leistung: Erreicht SOTA-Level in mehreren Audio-Benchmarks.
Umfangreiches Vortraining: Vortraining mit über 13 Millionen Stunden verschiedener Audiodaten (Sprache, Musik, Ton) und Textdaten, um leistungsstarkes Audio-Argumentation und Sprachverständnis zu ermöglichen.
Innovative Architektur: Durch die Verwendung eines hybriden Audioeingangs (kontinuierlicher akustischer Vektor + diskrete semantische Tags) und eines LLM-Kerns mit parallelen Verarbeitungsfunktionen können Text- und Audio-Tags gleichzeitig generiert werden.
Effiziente Inferenz: Chunked-Streaming-Demultiplexer mit Stream-Matching für Audiogenerierung mit geringer Latenz.
Open Source: Geben Sie Code- und Modell-Checkpoints für das Vortraining und die Feinabstimmung der Anweisungen frei und veröffentlichen Sie ein umfassendes Evaluierungs-Toolkit, um die Forschung und Entwicklung der Community zu fördern.
2. Bedienungsschritte
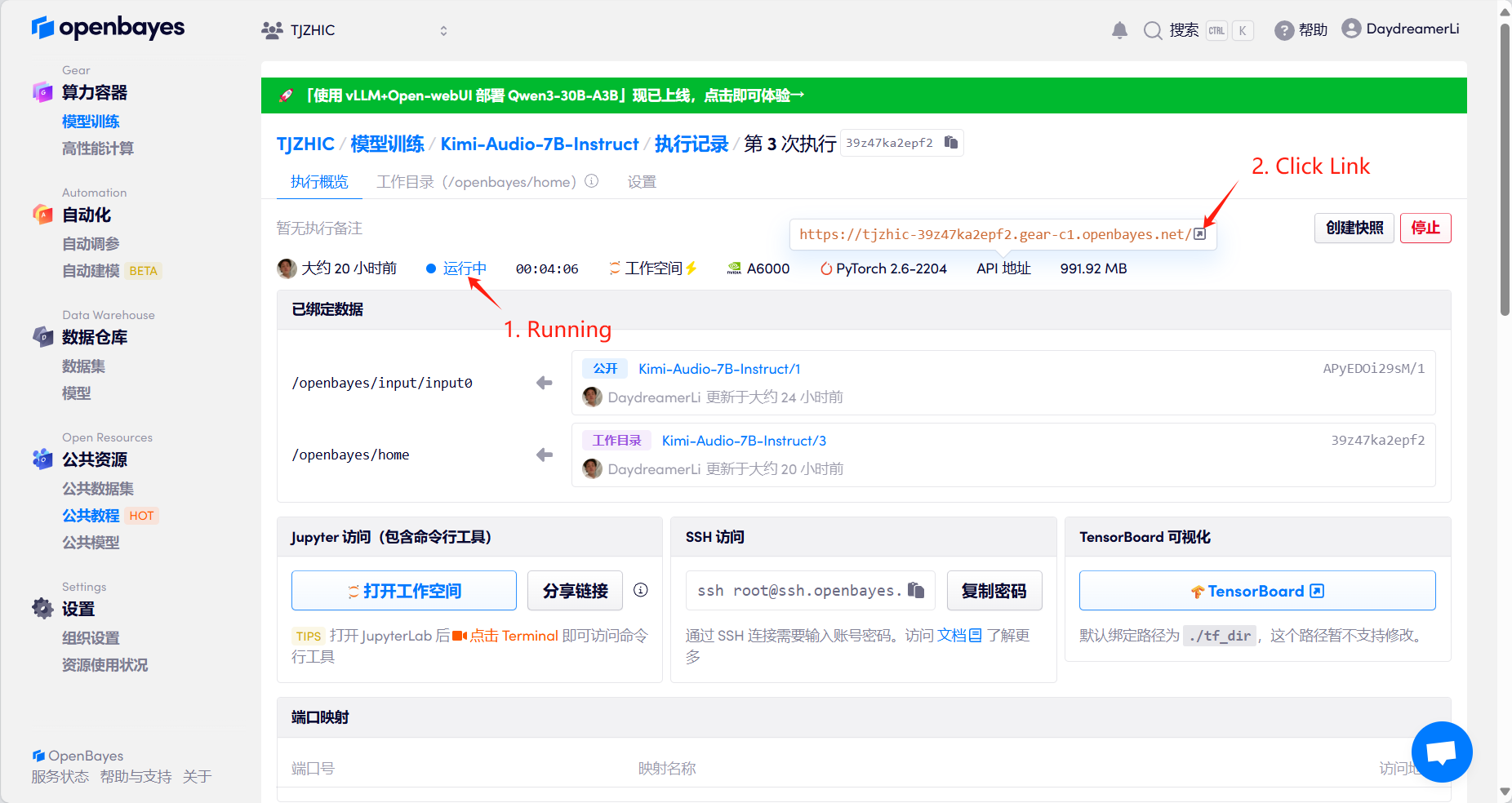
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 3–5 Minuten und aktualisieren Sie die Seite.
2. Anwendungsbeispiele
Nutzungsrichtlinien
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
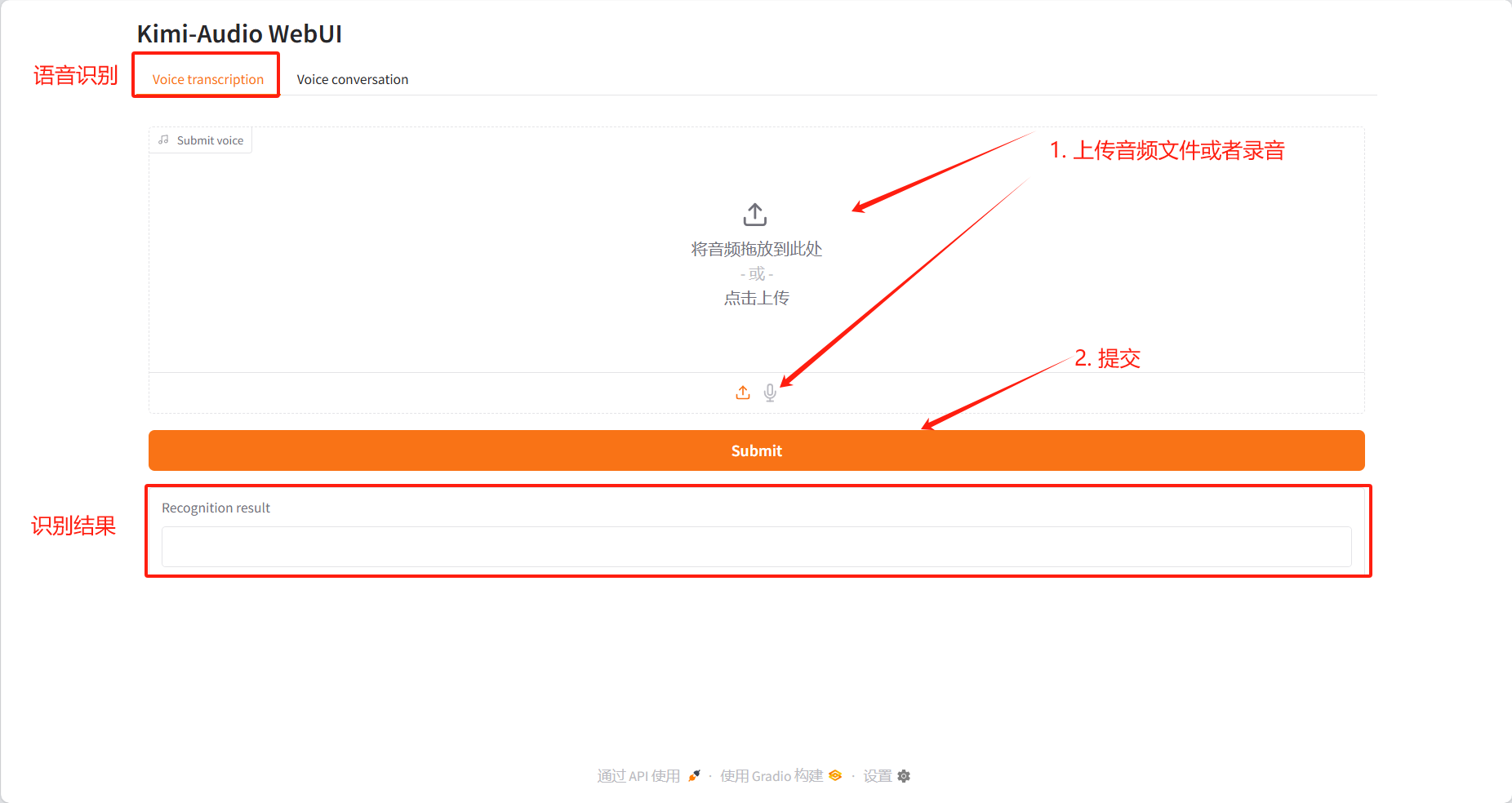
Dieses Tutorial bietet zwei Modultests: Sprachtranskription und Sprachkonversation.
Die Funktionen der einzelnen Module sind wie folgt:
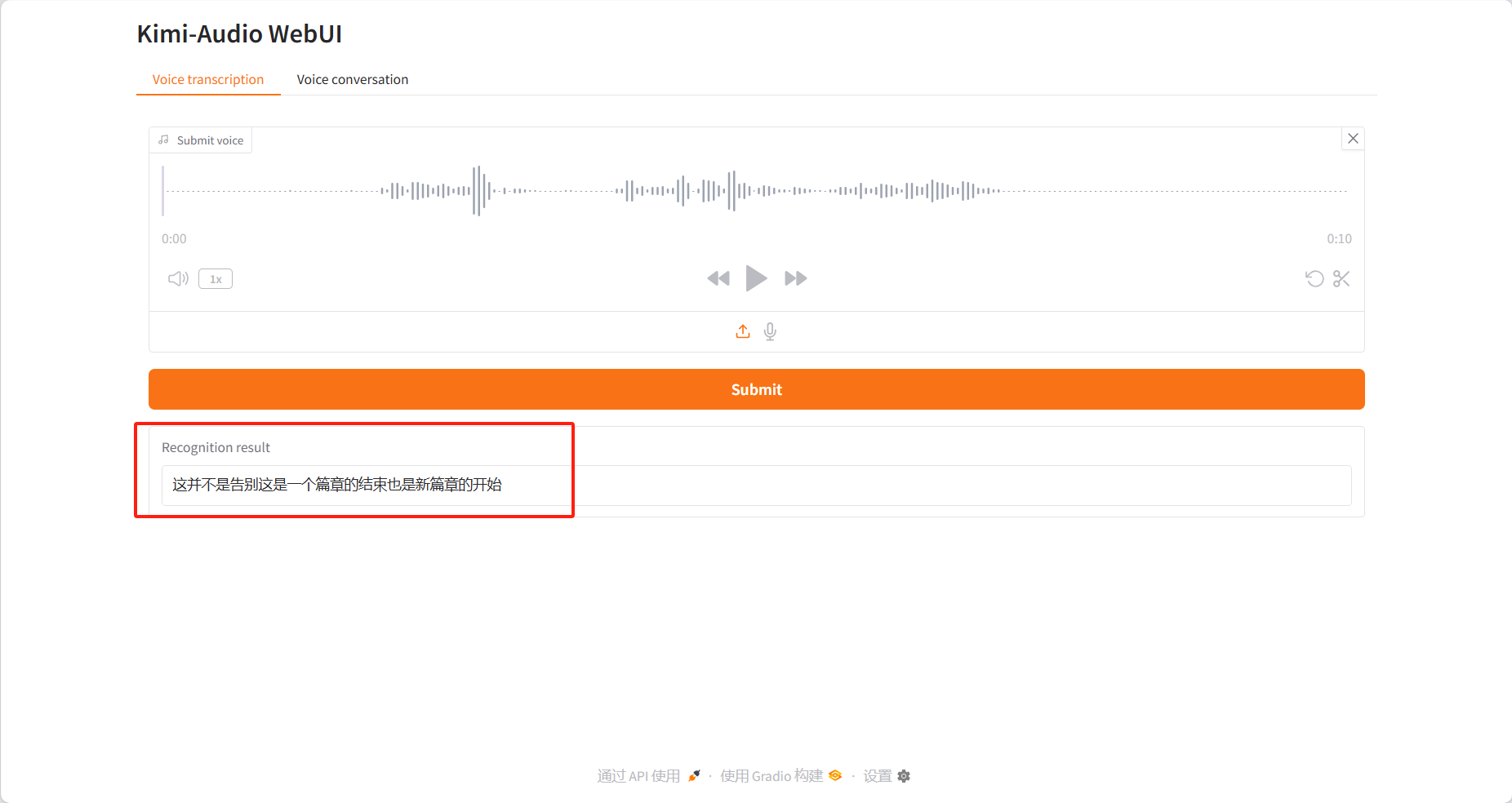
Sprachtranskription
Identifikationsergebnisse
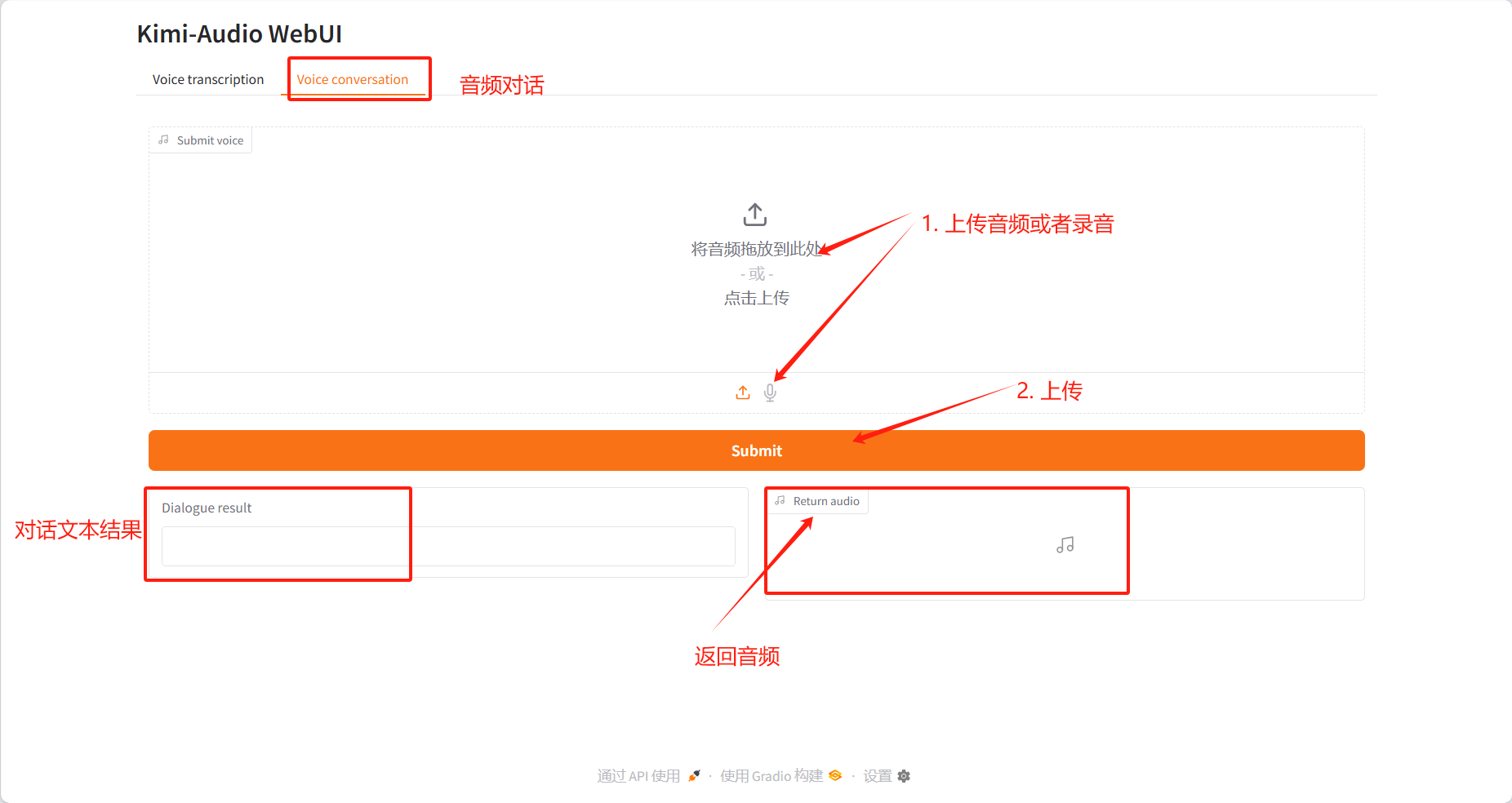
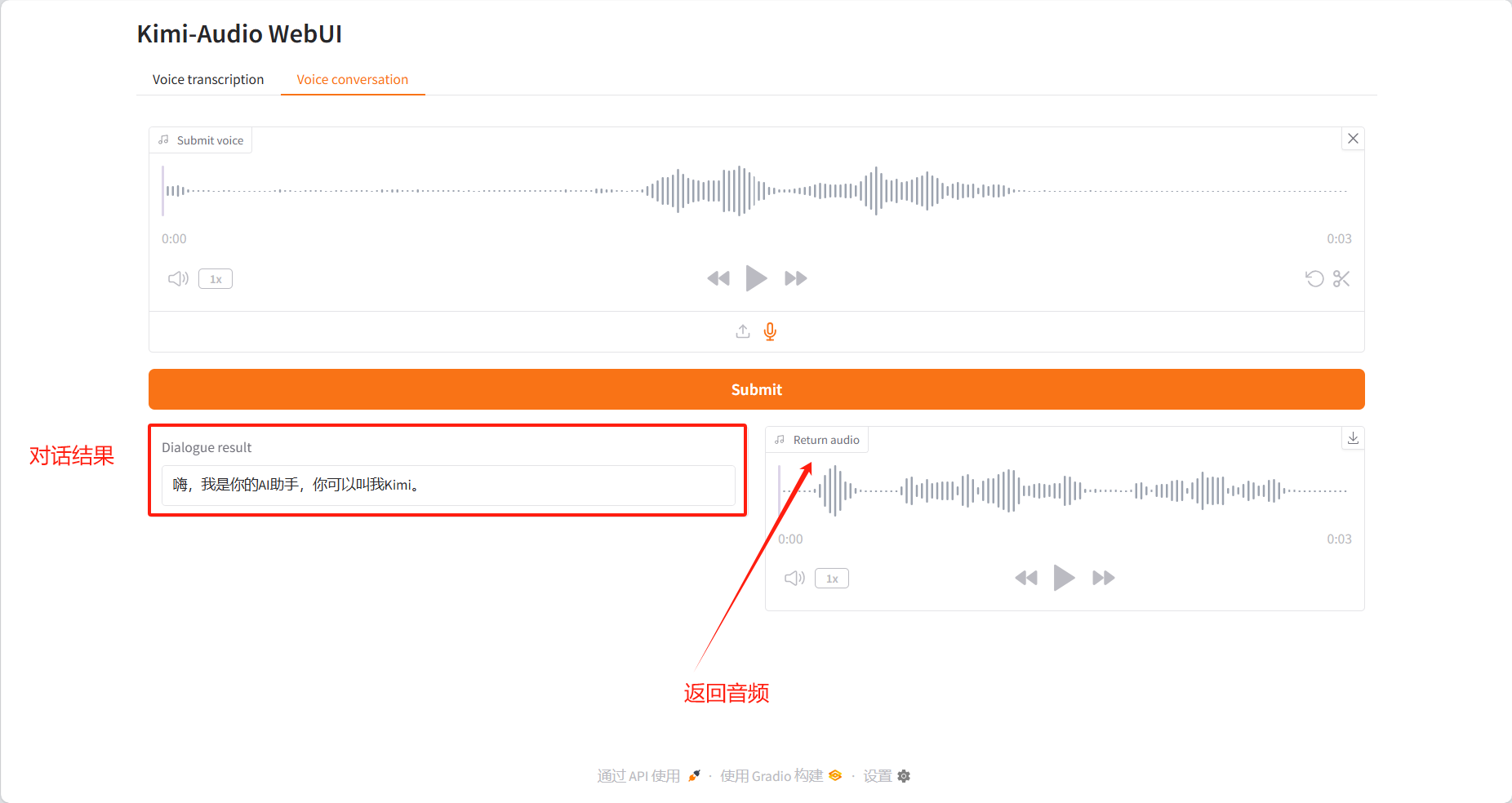
Sprachkonversation
Dialogergebnisse
3. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Die in diesem Tutorial verwendeten Rechenressourcen sind eine einzelne A6000-Karte.
Kimi-Audio-7B-Instruct ist ein Open-Source-Audio-Grundlagenmodell, das vom KimiTeam am 28. April 2025 veröffentlicht wurde. Das Modell kann verschiedene Audioverarbeitungsaufgaben in einem einzigen, einheitlichen Framework bewältigen. Zugehörige Forschungsarbeiten umfassen… Technischer Bericht von Kimi-Audio Zu den Hauptfunktionen gehören:
Allgemeine Funktionen: Bewältigt eine Vielzahl von Aufgaben wie automatische Spracherkennung (ASR), Beantwortung von Audiofragen (AQA), automatische Audiountertitelung (AAC), Sprachemotionserkennung (SER), Klassifizierung von Tonereignissen/-szenen (SEC/ASC) und End-to-End-Sprachdialog.
Branchenführende Leistung: Erreicht SOTA-Level in mehreren Audio-Benchmarks.
Umfangreiches Vortraining: Vortraining mit über 13 Millionen Stunden verschiedener Audiodaten (Sprache, Musik, Ton) und Textdaten, um leistungsstarkes Audio-Argumentation und Sprachverständnis zu ermöglichen.
Innovative Architektur: Durch die Verwendung eines hybriden Audioeingangs (kontinuierlicher akustischer Vektor + diskrete semantische Tags) und eines LLM-Kerns mit parallelen Verarbeitungsfunktionen können Text- und Audio-Tags gleichzeitig generiert werden.
Effiziente Inferenz: Chunked-Streaming-Demultiplexer mit Stream-Matching für Audiogenerierung mit geringer Latenz.
Open Source: Geben Sie Code- und Modell-Checkpoints für das Vortraining und die Feinabstimmung der Anweisungen frei und veröffentlichen Sie ein umfassendes Evaluierungs-Toolkit, um die Forschung und Entwicklung der Community zu fördern.
2. Bedienungsschritte
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 3–5 Minuten und aktualisieren Sie die Seite.
2. Anwendungsbeispiele
Nutzungsrichtlinien
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Dieses Tutorial bietet zwei Modultests: Sprachtranskription und Sprachkonversation.
Die Funktionen der einzelnen Module sind wie folgt:
Sprachtranskription
Identifikationsergebnisse
Sprachkonversation
Dialogergebnisse
3. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.