Dieses Tutorial verwendet Ressourcen für eine einzelne RTX 4090-Karte.
👉 Dieses Projekt bietet ein Modell für:
MegaTTS 3: Ein TTS-System mit einem innovativen, spärlich ausgerichteten, geführten „Latent Diffuse Transformer“-Algorithmus, der modernste Zero-Shot-TTS-Sprachqualität erreicht und eine hochflexible Steuerung der Akzentstärke unterstützt. Die Eingangsklangfarbe kann geklont und zur Generierung spezifischer Audioinhalte je nach Bedarf verwendet werden.
2. Bedienungsschritte
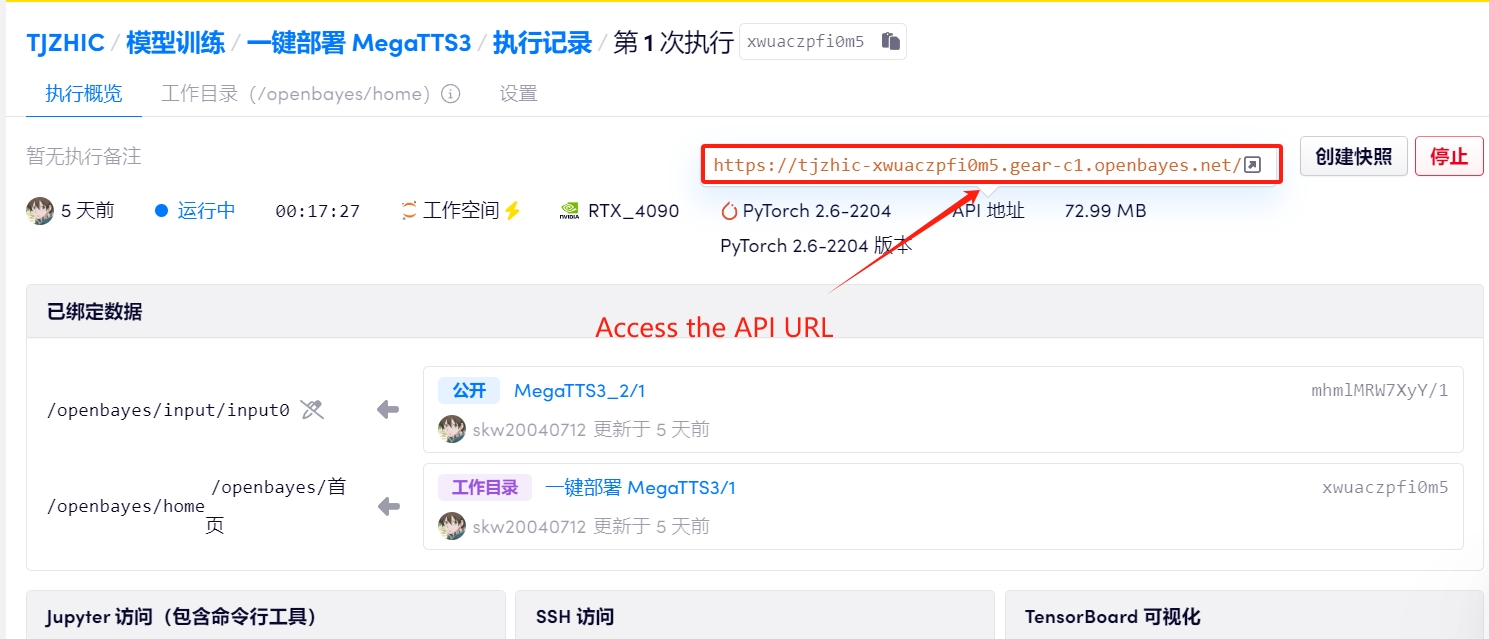
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
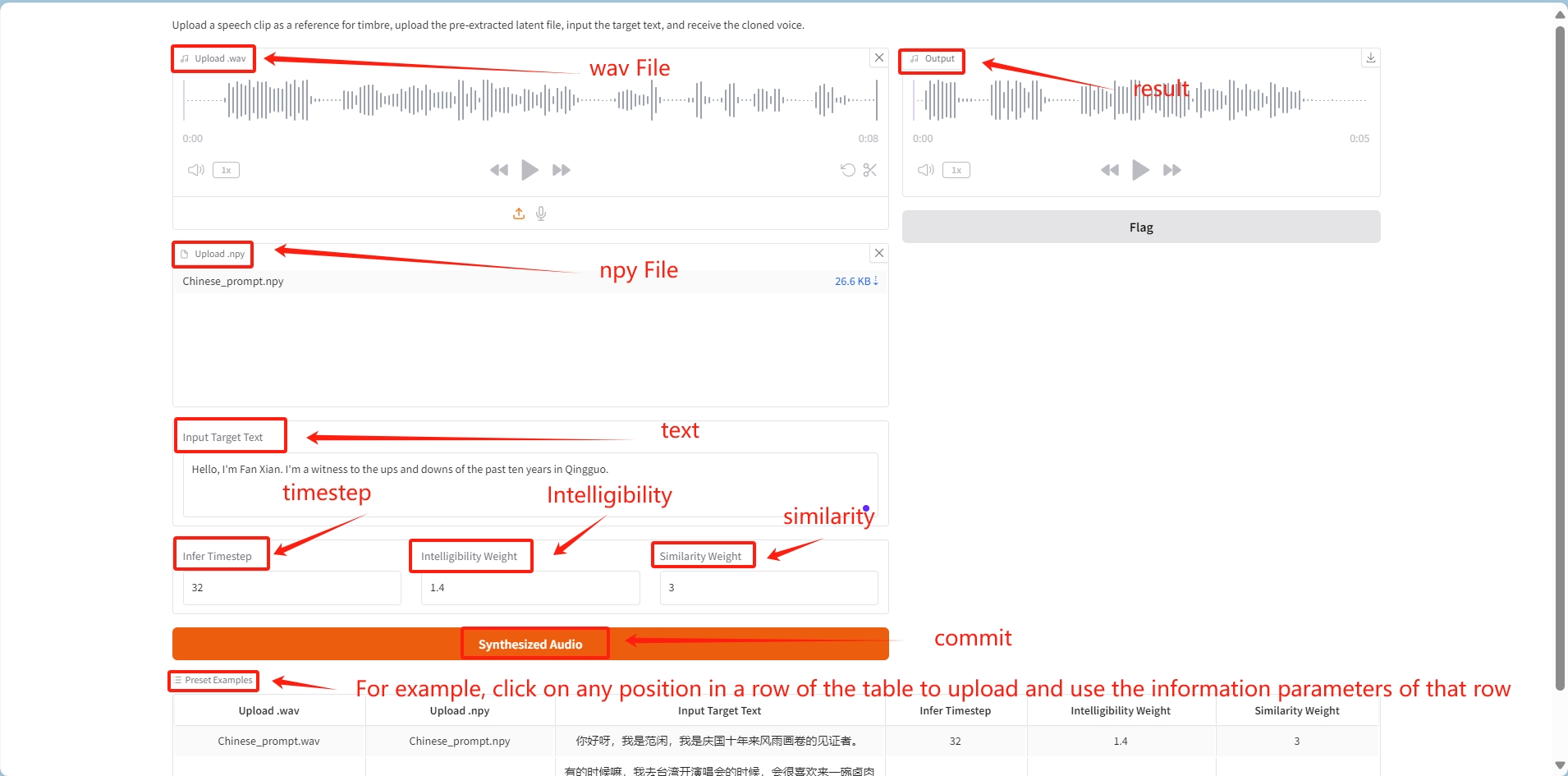
2. Sobald Sie die Webseite betreten, können Sie MegaTTS 3 verwenden
Anwendung
① Laden Sie die WAV-Audiodatei und die entsprechende generierte NPY-Datei separat hoch.
2 Geben Sie den angegebenen Text in input_text ein.
3. Nach dem Senden wird die Klangfarbe in der Audiodatei geklont, um den Ton zu generieren, der dem Text im Eingabetext entspricht.
❗️Parameterbeschreibung:
Zeitschritt ableiten: Beeinflusst den Zeitschritt, in dem das Modell Töne generiert, und steuert normalerweise die Anzahl der Zeitschritte im Generierungsprozess. Ein kleinerer Zeitschritt kann den Klang weicher machen, da das Modell über mehr Zeitschritte verfügt, um die Klangmerkmale zu verfeinern.
Verständlichkeitsgewichtung: Passt die Klarheit und Verständlichkeit des Tons an. Eine höhere Gewichtung macht den Ton klarer und eignet sich für Szenen, in denen Informationen präzise übermittelt werden müssen, dabei aber etwas Natürlichkeit verloren gehen kann.
Ähnlichkeitsgewicht: Steuert, wie ähnlich der generierte Ton dem Originalton ist. Eine höhere Gewichtung bringt den Klang näher an den Originalklang und eignet sich für Szenarien, in denen die Zielstimme originalgetreu wiedergegeben werden muss.
Beispieldatei abrufen
Zur Website https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlrgibt es drei Unterordner (librispeech_testclean_40, official_test_case, user_batch_1-3), die alle derzeit verfügbaren Klangfarben enthalten. Nachdem Sie den Ordner aufgerufen haben, hören Sie sich die WAV- und die NPY-Datei an und laden Sie sie herunter.
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer kjasdk Für die Erstellung dieses Tutorials lauten die Projektreferenzinformationen wie folgt:
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Dieses Tutorial verwendet Ressourcen für eine einzelne RTX 4090-Karte.
👉 Dieses Projekt bietet ein Modell für:
MegaTTS 3: Ein TTS-System mit einem innovativen, spärlich ausgerichteten, geführten „Latent Diffuse Transformer“-Algorithmus, der modernste Zero-Shot-TTS-Sprachqualität erreicht und eine hochflexible Steuerung der Akzentstärke unterstützt. Die Eingangsklangfarbe kann geklont und zur Generierung spezifischer Audioinhalte je nach Bedarf verwendet werden.
2. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Sobald Sie die Webseite betreten, können Sie MegaTTS 3 verwenden
Anwendung
① Laden Sie die WAV-Audiodatei und die entsprechende generierte NPY-Datei separat hoch.
2 Geben Sie den angegebenen Text in input_text ein.
3. Nach dem Senden wird die Klangfarbe in der Audiodatei geklont, um den Ton zu generieren, der dem Text im Eingabetext entspricht.
❗️Parameterbeschreibung:
Zeitschritt ableiten: Beeinflusst den Zeitschritt, in dem das Modell Töne generiert, und steuert normalerweise die Anzahl der Zeitschritte im Generierungsprozess. Ein kleinerer Zeitschritt kann den Klang weicher machen, da das Modell über mehr Zeitschritte verfügt, um die Klangmerkmale zu verfeinern.
Verständlichkeitsgewichtung: Passt die Klarheit und Verständlichkeit des Tons an. Eine höhere Gewichtung macht den Ton klarer und eignet sich für Szenen, in denen Informationen präzise übermittelt werden müssen, dabei aber etwas Natürlichkeit verloren gehen kann.
Ähnlichkeitsgewicht: Steuert, wie ähnlich der generierte Ton dem Originalton ist. Eine höhere Gewichtung bringt den Klang näher an den Originalklang und eignet sich für Szenarien, in denen die Zielstimme originalgetreu wiedergegeben werden muss.
Beispieldatei abrufen
Zur Website https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlrgibt es drei Unterordner (librispeech_testclean_40, official_test_case, user_batch_1-3), die alle derzeit verfügbaren Klangfarben enthalten. Nachdem Sie den Ordner aufgerufen haben, hören Sie sich die WAV- und die NPY-Datei an und laden Sie sie herunter.
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer kjasdk Für die Erstellung dieses Tutorials lauten die Projektreferenzinformationen wie folgt:
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.