In-Context Edit (ICEdit) ist ein hocheffizientes, anweisungsbasiertes Bildbearbeitungsframework, das am 29. April 2025 von der Zhejiang-Universität und der Harvard-Universität veröffentlicht wurde. Im Vergleich zu bisherigen Methoden benötigt ICEdit lediglich 11³T trainierbare Parameter (200 Millionen) und 0,11³T Trainingsdaten (50.000). Es zeichnet sich durch eine hohe Generalisierungsfähigkeit aus und eignet sich für vielfältige Bearbeitungsaufgaben. Im Vergleich zu kommerziellen Modellen wie Gemini und GPT-40 ist es quelloffener, kostengünstiger, schneller und bietet eine hohe Leistungsfähigkeit. Entsprechende Forschungsarbeiten sind verfügbar. In-Context-Bearbeitung: Aktivieren der lehrreichen Bildbearbeitung mit In-Context-Generierung im Large Scale Diffusion Transformer .
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Wenn Sie die offiziell genannten 9 Sekunden zur Bilderzeugung erreichen möchten, benötigen Sie eine Grafikkarte mit höherer Ausstattung. Dieses Projekt unterstützt derzeit nur Textbeschreibungen in englischer Sprache.
In diesem Projekt verwendete Modelle:
normal-lora
FLUX.1-Fill-dev
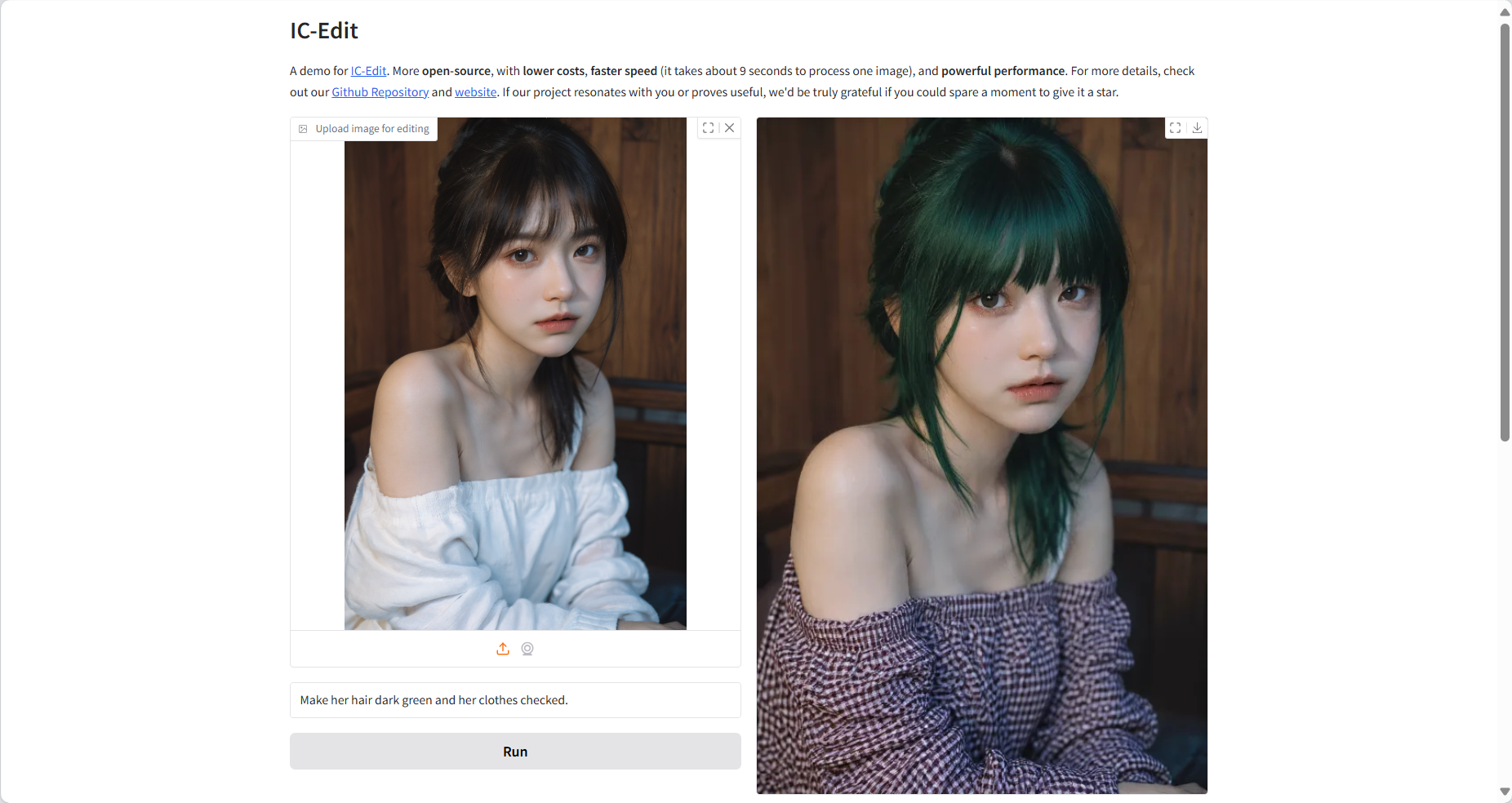
2. Projektbeispiele
Vergleich mit anderen Geschäftsmodellen
3. Bedienungsschritte
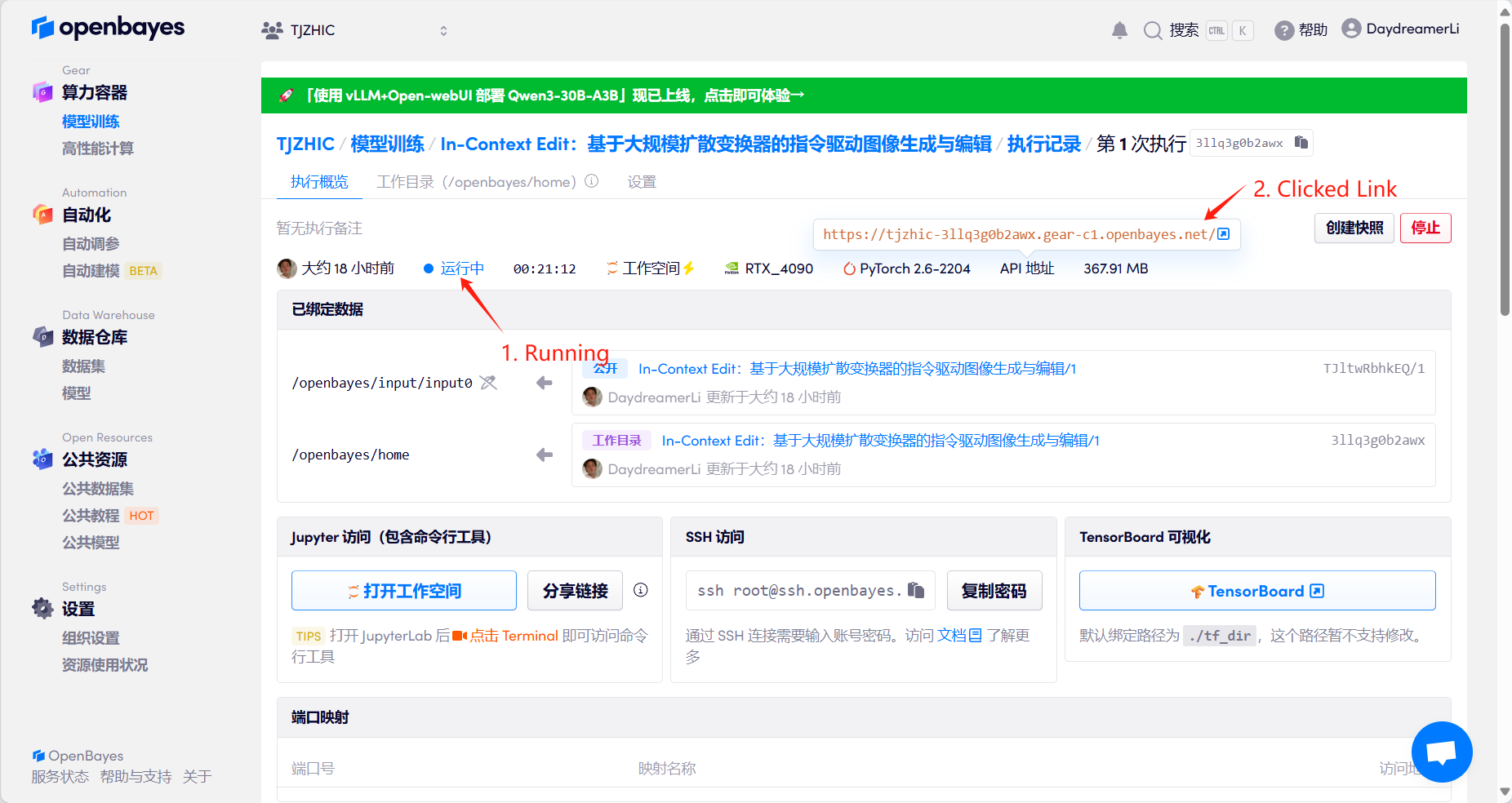
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
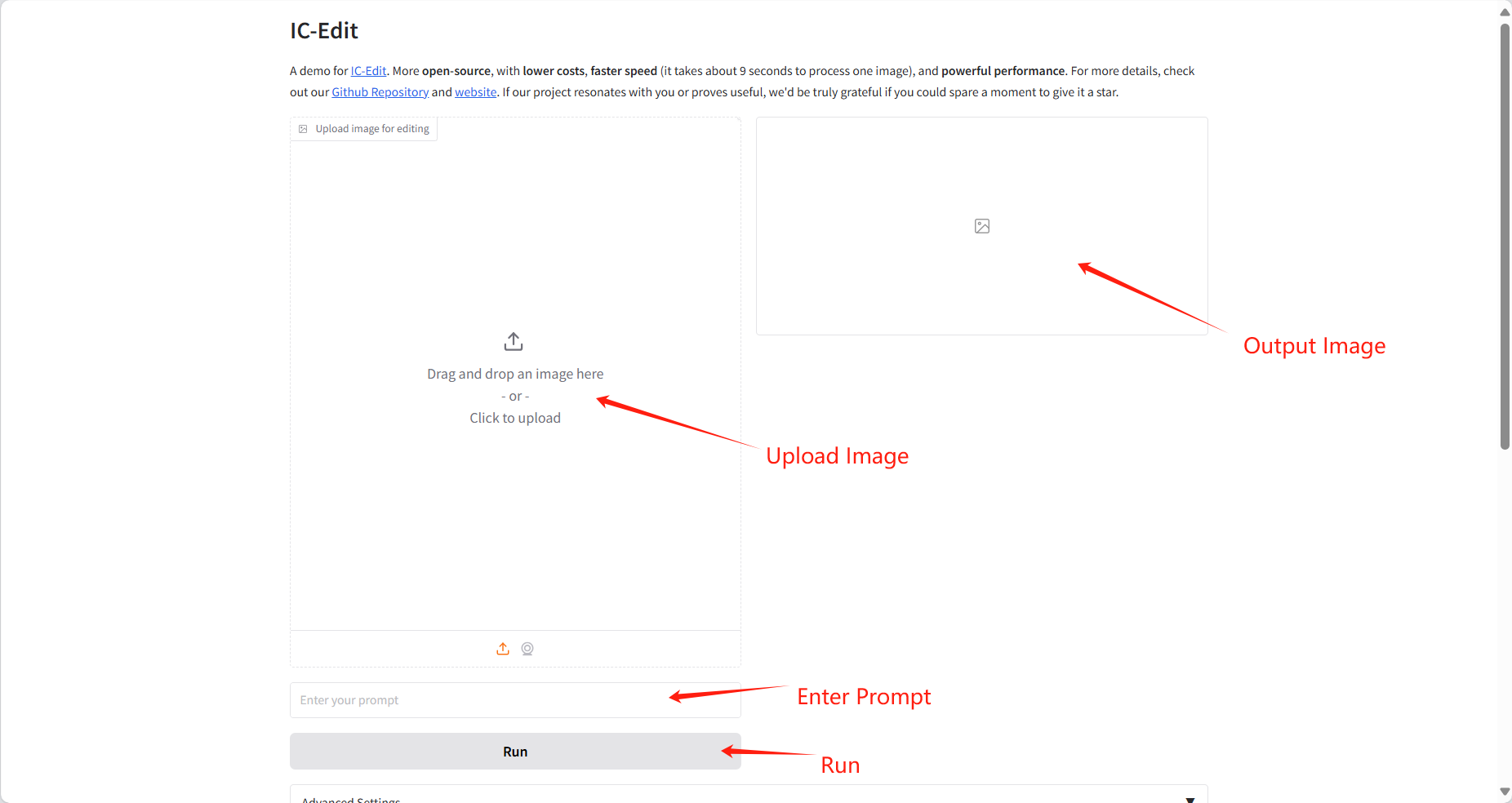
2. Nutzen Sie die Demonstration
❗️Wichtige Anwendungstipps:
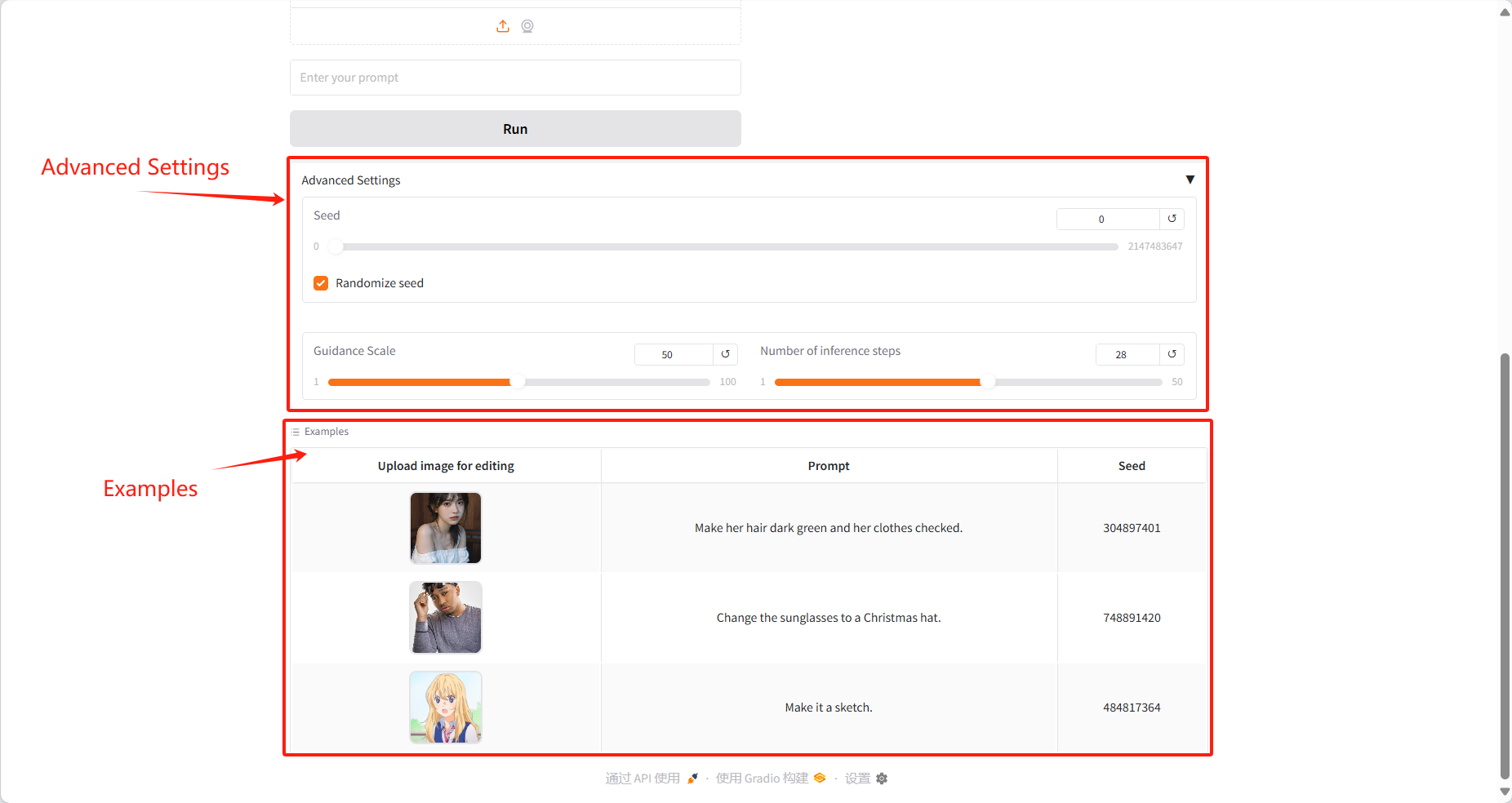
Orientierungsskala: Es wird verwendet, um zu steuern, inwieweit bedingte Eingaben (wie Text oder Bilder) in generativen Modellen die generierten Ergebnisse beeinflussen. Höhere Richtwerte führen dazu, dass die generierten Ergebnisse besser mit den Eingabebedingungen übereinstimmen, während niedrigere Werte mehr Zufälligkeit beibehalten.
Anzahl der Inferenzschritte: Stellt die Anzahl der Iterationen des Modells oder die Anzahl der Schritte im Inferenzprozess dar und stellt die Anzahl der Optimierungsschritte dar, die das Modell zum Generieren des Ergebnisses verwendet. Eine höhere Anzahl von Schritten führt im Allgemeinen zu genaueren Ergebnissen, kann aber die Rechenzeit verlängern.
Samen: Zufallszahlen-Seed, der zur Steuerung der Zufälligkeit des Generierungsprozesses verwendet wird. Derselbe Seed-Wert kann dieselben Ergebnisse erzeugen (vorausgesetzt, dass die anderen Parameter gleich sind), was für die Reproduktion von Ergebnissen sehr wichtig ist.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{zhang2025ICEdit,
title={In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer},
author={Zechuan Zhang and Ji Xie and Yu Lu and Zongxin Yang and Yi Yang},
year={2025},
eprint={2504.20690},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.20690},
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
In-Context Edit (ICEdit) ist ein hocheffizientes, anweisungsbasiertes Bildbearbeitungsframework, das am 29. April 2025 von der Zhejiang-Universität und der Harvard-Universität veröffentlicht wurde. Im Vergleich zu bisherigen Methoden benötigt ICEdit lediglich 11³T trainierbare Parameter (200 Millionen) und 0,11³T Trainingsdaten (50.000). Es zeichnet sich durch eine hohe Generalisierungsfähigkeit aus und eignet sich für vielfältige Bearbeitungsaufgaben. Im Vergleich zu kommerziellen Modellen wie Gemini und GPT-40 ist es quelloffener, kostengünstiger, schneller und bietet eine hohe Leistungsfähigkeit. Entsprechende Forschungsarbeiten sind verfügbar. In-Context-Bearbeitung: Aktivieren der lehrreichen Bildbearbeitung mit In-Context-Generierung im Large Scale Diffusion Transformer .
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource. Wenn Sie die offiziell genannten 9 Sekunden zur Bilderzeugung erreichen möchten, benötigen Sie eine Grafikkarte mit höherer Ausstattung. Dieses Projekt unterstützt derzeit nur Textbeschreibungen in englischer Sprache.
In diesem Projekt verwendete Modelle:
normal-lora
FLUX.1-Fill-dev
2. Projektbeispiele
Vergleich mit anderen Geschäftsmodellen
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Nutzen Sie die Demonstration
❗️Wichtige Anwendungstipps:
Orientierungsskala: Es wird verwendet, um zu steuern, inwieweit bedingte Eingaben (wie Text oder Bilder) in generativen Modellen die generierten Ergebnisse beeinflussen. Höhere Richtwerte führen dazu, dass die generierten Ergebnisse besser mit den Eingabebedingungen übereinstimmen, während niedrigere Werte mehr Zufälligkeit beibehalten.
Anzahl der Inferenzschritte: Stellt die Anzahl der Iterationen des Modells oder die Anzahl der Schritte im Inferenzprozess dar und stellt die Anzahl der Optimierungsschritte dar, die das Modell zum Generieren des Ergebnisses verwendet. Eine höhere Anzahl von Schritten führt im Allgemeinen zu genaueren Ergebnissen, kann aber die Rechenzeit verlängern.
Samen: Zufallszahlen-Seed, der zur Steuerung der Zufälligkeit des Generierungsprozesses verwendet wird. Derselbe Seed-Wert kann dieselben Ergebnisse erzeugen (vorausgesetzt, dass die anderen Parameter gleich sind), was für die Reproduktion von Ergebnissen sehr wichtig ist.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Dank an den Github-Benutzer SuperYang Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{zhang2025ICEdit,
title={In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer},
author={Zechuan Zhang and Ji Xie and Yu Lu and Zongxin Yang and Yi Yang},
year={2025},
eprint={2504.20690},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.20690},
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.