Qwen3 ist die neueste Generation großer Sprachmodelle in der Qwen-Reihe und bietet umfassende dichte Modelle und MoE-Modelle (Mixed of Experts). Basierend auf umfangreicher Trainingserfahrung hat Qwen3 bahnbrechende Fortschritte in den Bereichen Argumentation, Befolgen von Anweisungen, Agentenfähigkeiten und Mehrsprachenunterstützung erzielt. Die Anwendungsszenarien von Qwen3 sind sehr vielfältig. Es unterstützt die Verarbeitung von Text, Bildern, Audio und Video und kann die Anforderungen der multimodalen Inhaltserstellung und modalübergreifender Aufgaben erfüllen. In Anwendungen auf Unternehmensebene ermöglichen die Agentenfunktionen und die Mehrsprachenunterstützung von Qwen3 die Bewältigung komplexer Aufgaben wie medizinischer Diagnosen, der Analyse juristischer Dokumente und der Automatisierung des Kundendienstes. Darüber hinaus eignen sich kleine Modelle wie Qwen3-0.6B für den Einsatz auf Endgeräten wie Mobiltelefonen, was die Anwendungsszenarien weiter erweitert.
Die neueste Version Qwen3 verfügt über folgende Funktionen:
Dichte und gemischte Expertenmodelle in voller Größe: 0,6B, 1,7B, 4B, 8B, 14B, 32B und 30B-A3B, 235B-A22B
Unterstützt nahtloses Umschalten zwischen Denkmodus (für komplexe logische Schlussfolgerungen, Mathematik und Codierung) und Nicht-Denkmodus (für effiziente allgemeine Gespräche) und gewährleistet so optimale Leistung in verschiedenen Szenarien.
Deutlich verbesserte Denkfähigkeiten, die das vorherige QwQ (im Denkmodus) und Qwen2.5-Befehlsmodell (im Nicht-Denkmodus) in Mathematik, Codegenerierung und logischem Denken mit gesundem Menschenverstand übertreffen.
Überlegene Übereinstimmung mit menschlichen Vorlieben, hervorragende Leistung beim kreativen Schreiben, Rollenspielen, mehrstufigen Gesprächen und Befolgen von Befehlen, wodurch ein natürlicheres, ansprechenderes und intensiveres Gesprächserlebnis entsteht.
Verfügt über hervorragende Fähigkeiten für intelligente Agenten, kann externe Tools sowohl im Denk- als auch im Nicht-Denkmodus präzise integrieren und ist führend bei Open-Source-Modellen für komplexe agentenbasierte Aufgaben.
Es unterstützt mehr als 100 Sprachen und Dialekte und verfügt über leistungsstarke Funktionen zum Verstehen, Argumentieren, Befolgen und Generieren mehrerer Sprachen.
2. Bedienungsschritte
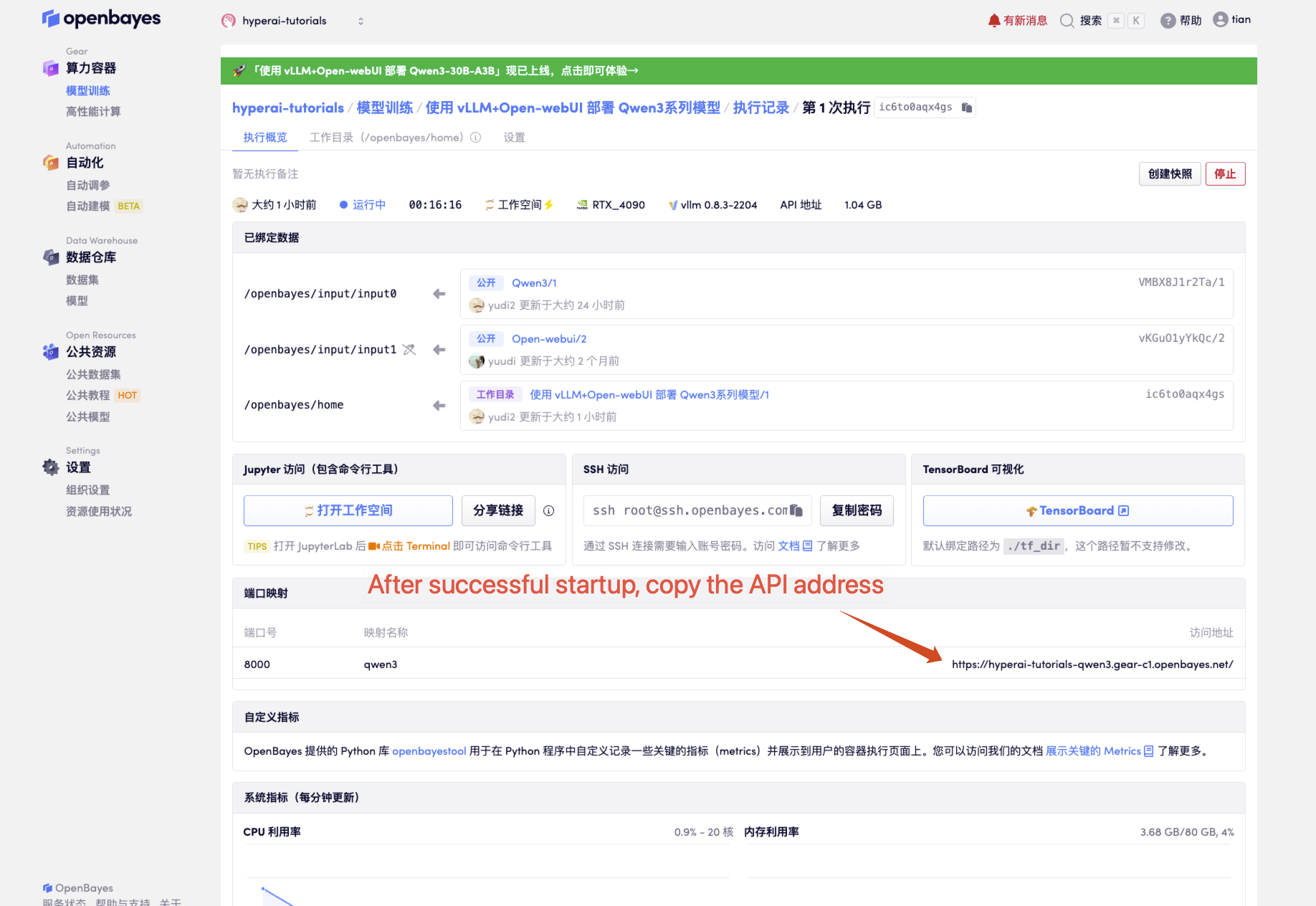
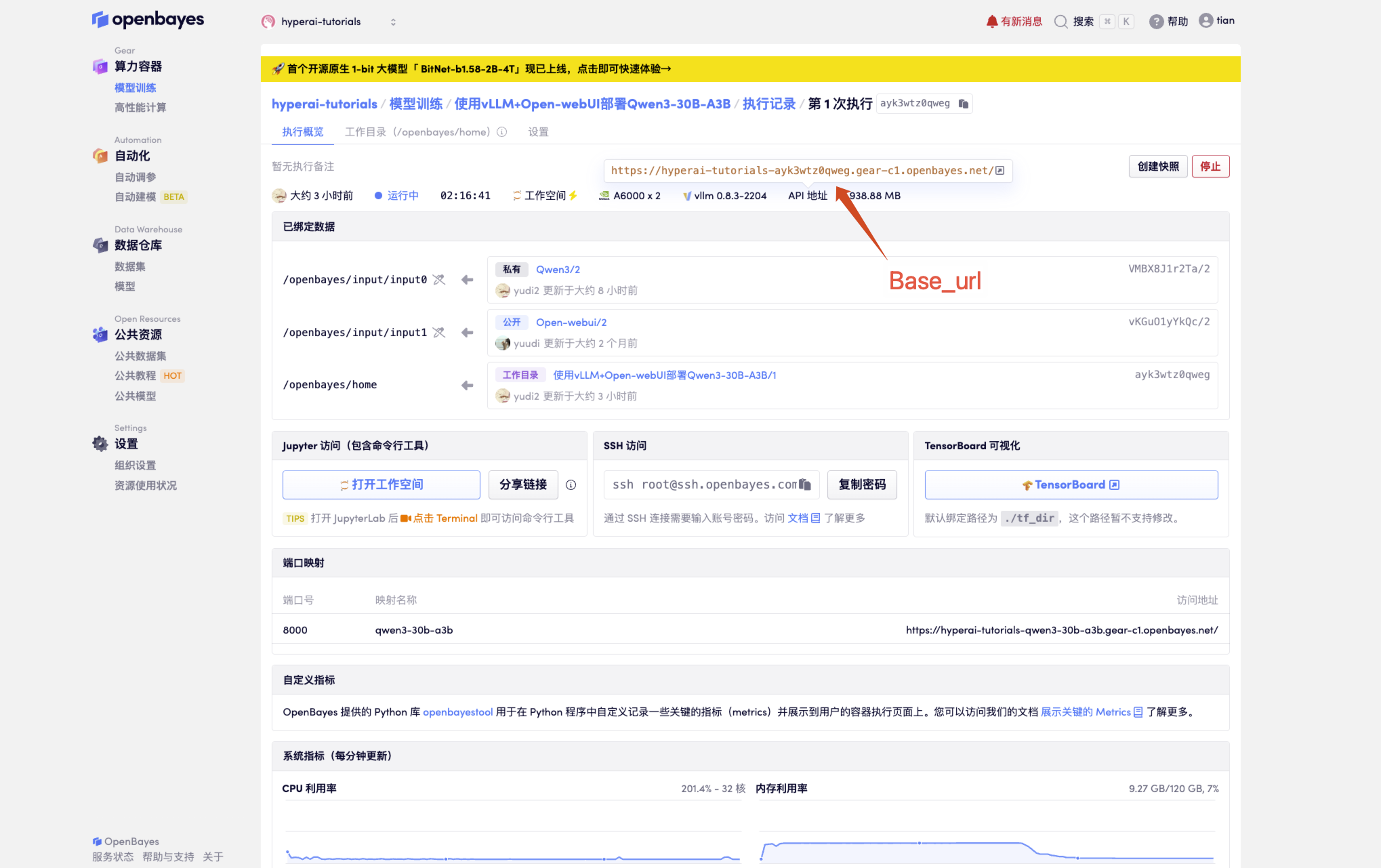
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
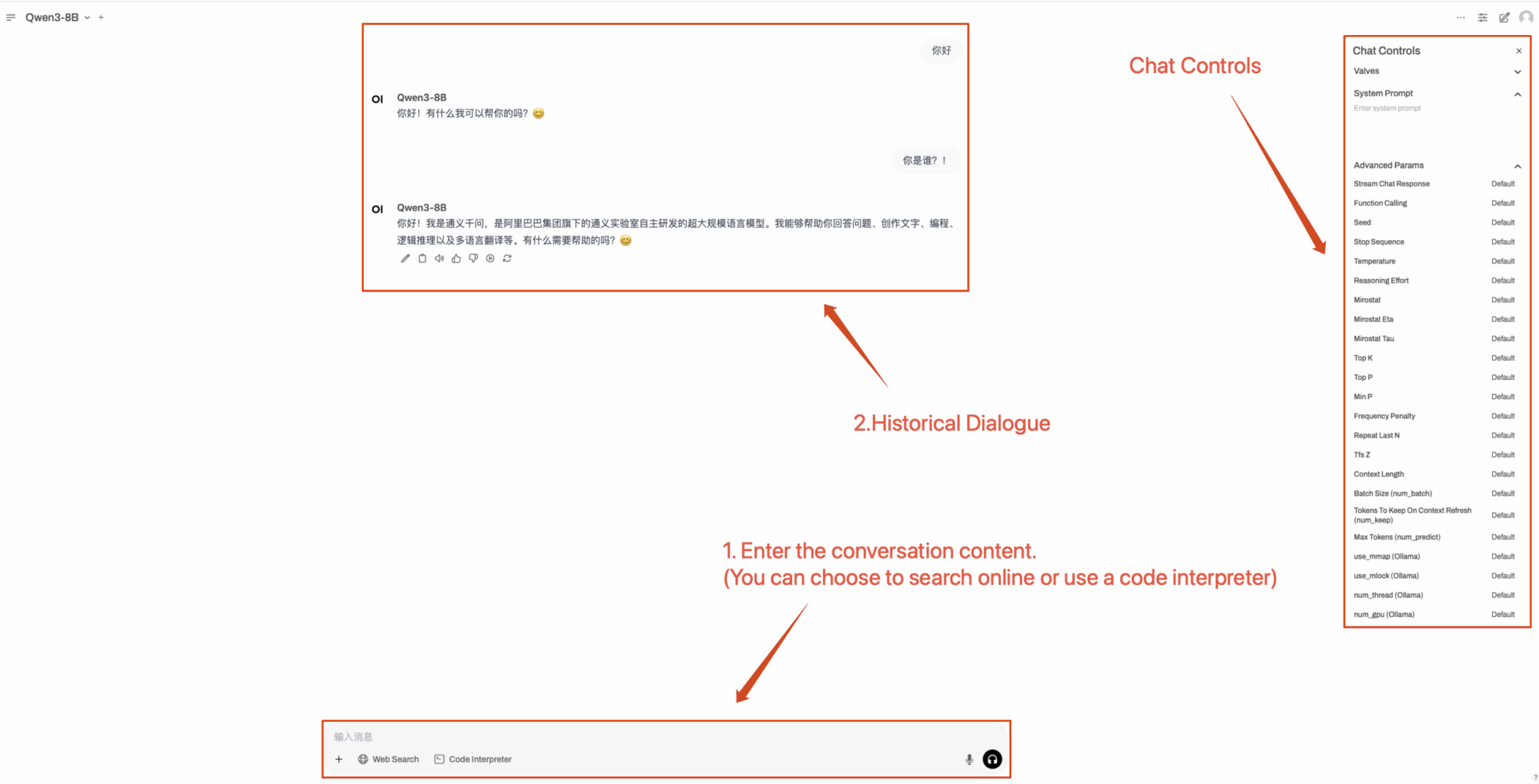
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Anwendung
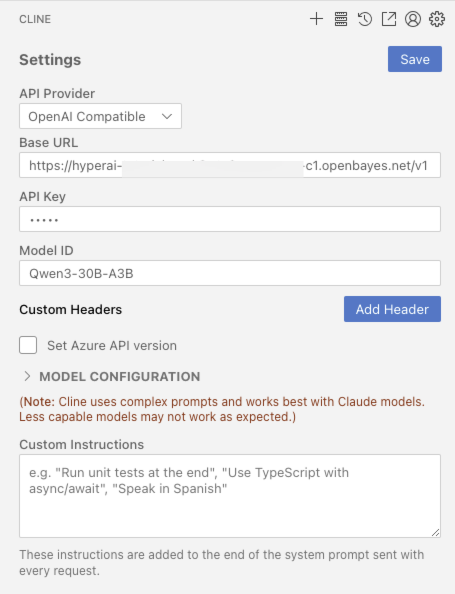
3. OpenAI API-Aufrufhandbuch
Nachfolgend finden Sie eine optimierte Beschreibung der API-Aufrufmethode mit einer klareren Struktur und zusätzlichen praktischen Details:
/input0/Qwen3-4B → Ersetzen Sie durch Ihren Zielmodellpfad (z. B. Qwen3-1.7B).
--served-model-name → Wechseln Sie zum entsprechenden Modellnamen (z. B. Qwen3-1.7B).
Sobald Sie fertig sind, ist Ihr neues Modell einsatzbereit! 🚀
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Qwen3 ist die neueste Generation großer Sprachmodelle in der Qwen-Reihe und bietet umfassende dichte Modelle und MoE-Modelle (Mixed of Experts). Basierend auf umfangreicher Trainingserfahrung hat Qwen3 bahnbrechende Fortschritte in den Bereichen Argumentation, Befolgen von Anweisungen, Agentenfähigkeiten und Mehrsprachenunterstützung erzielt. Die Anwendungsszenarien von Qwen3 sind sehr vielfältig. Es unterstützt die Verarbeitung von Text, Bildern, Audio und Video und kann die Anforderungen der multimodalen Inhaltserstellung und modalübergreifender Aufgaben erfüllen. In Anwendungen auf Unternehmensebene ermöglichen die Agentenfunktionen und die Mehrsprachenunterstützung von Qwen3 die Bewältigung komplexer Aufgaben wie medizinischer Diagnosen, der Analyse juristischer Dokumente und der Automatisierung des Kundendienstes. Darüber hinaus eignen sich kleine Modelle wie Qwen3-0.6B für den Einsatz auf Endgeräten wie Mobiltelefonen, was die Anwendungsszenarien weiter erweitert.
Die neueste Version Qwen3 verfügt über folgende Funktionen:
Dichte und gemischte Expertenmodelle in voller Größe: 0,6B, 1,7B, 4B, 8B, 14B, 32B und 30B-A3B, 235B-A22B
Unterstützt nahtloses Umschalten zwischen Denkmodus (für komplexe logische Schlussfolgerungen, Mathematik und Codierung) und Nicht-Denkmodus (für effiziente allgemeine Gespräche) und gewährleistet so optimale Leistung in verschiedenen Szenarien.
Deutlich verbesserte Denkfähigkeiten, die das vorherige QwQ (im Denkmodus) und Qwen2.5-Befehlsmodell (im Nicht-Denkmodus) in Mathematik, Codegenerierung und logischem Denken mit gesundem Menschenverstand übertreffen.
Überlegene Übereinstimmung mit menschlichen Vorlieben, hervorragende Leistung beim kreativen Schreiben, Rollenspielen, mehrstufigen Gesprächen und Befolgen von Befehlen, wodurch ein natürlicheres, ansprechenderes und intensiveres Gesprächserlebnis entsteht.
Verfügt über hervorragende Fähigkeiten für intelligente Agenten, kann externe Tools sowohl im Denk- als auch im Nicht-Denkmodus präzise integrieren und ist führend bei Open-Source-Modellen für komplexe agentenbasierte Aufgaben.
Es unterstützt mehr als 100 Sprachen und Dialekte und verfügt über leistungsstarke Funktionen zum Verstehen, Argumentieren, Befolgen und Generieren mehrerer Sprachen.
2. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Anwendung
3. OpenAI API-Aufrufhandbuch
Nachfolgend finden Sie eine optimierte Beschreibung der API-Aufrufmethode mit einer klareren Struktur und zusätzlichen praktischen Details:
/input0/Qwen3-4B → Ersetzen Sie durch Ihren Zielmodellpfad (z. B. Qwen3-1.7B).
--served-model-name → Wechseln Sie zum entsprechenden Modellnamen (z. B. Qwen3-1.7B).
Sobald Sie fertig sind, ist Ihr neues Modell einsatzbereit! 🚀
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.