Command Palette
Search for a command to run...
Qwen2.5-Omni Eröffnet Alle Arten Des Lesens, Hörens, Sprechens Und Schreibens
1. Einführung in das Tutorial
Qwen2.5-Omni ist das neueste durchgängige multimodale Flaggschiffmodell, das vom Alibaba Tongyi Qianwen-Team am 27. März 2025 veröffentlicht wurde. Es ist für eine umfassende multimodale Wahrnehmung konzipiert und verarbeitet nahtlos verschiedene Eingaben, darunter Text, Bilder, Audio und Video, und unterstützt gleichzeitig die Streaming-Textgenerierung und die Ausgabe per natürlicher Sprachsynthese.
Hauptmerkmale
- Rundum innovative Architektur: Es verwendet eine neuartige Thinker-Talker-Architektur, ein durchgängiges multimodales Modell, das das modalübergreifende Verständnis von Text/Bild/Audio/Video unterstützt und gleichzeitig Text- und natürliche Sprachantworten im Streaming-Verfahren generiert. Das Forschungsteam schlug eine neue Positionscodierungstechnologie namens TMRoPE (Time-aligned Multimodal RoPE) vor, die durch Zeitachsenausrichtung eine präzise Synchronisierung von Video- und Audioeingängen erreicht.
- Audio- und Videointeraktion in Echtzeit: Die Architektur ist auf die Unterstützung einer vollständigen Echtzeitinteraktion ausgelegt und unterstützt eine stückweise Eingabe und eine sofortige Ausgabe.
- Natürliche und flüssige Spracherzeugung: Übertrifft viele bestehende Streaming- und Nicht-Streaming-Alternativen in Bezug auf Natürlichkeit und Stabilität der Sprachgenerierung.
- Omnimodaler Leistungsvorteil: Zeigt im Vergleich zu unimodalen Modellen ähnlicher Größe eine überlegene Leistung. Der Qwen2.5-Omni übertrifft den ähnlich großen Qwen2-Audio in seinen Audiofunktionen und ist mit dem Qwen2.5-VL-7B vergleichbar.
- Hervorragende End-to-End-Fähigkeit zur Befolgung von Sprachbefehlen: Qwen2.5-Omni zeigt bei der End-to-End-Verfolgung von Sprachbefehlen vergleichbare Ergebnisse wie die Verarbeitung von Texteingaben und zeichnet sich bei Benchmarks wie dem MMLU-Allgemeinwissensverständnis und der mathematischen Argumentation von GSM8K aus.
Dieses Tutorial verwendet Qwen2.5-Omni als Demonstration und die Rechenressourcen sind A6000.
Unterstützte Funktionen:
- Multimodaler Online-Dialog
- Multimodale Offline-Konversation
2. Bedienungsschritte
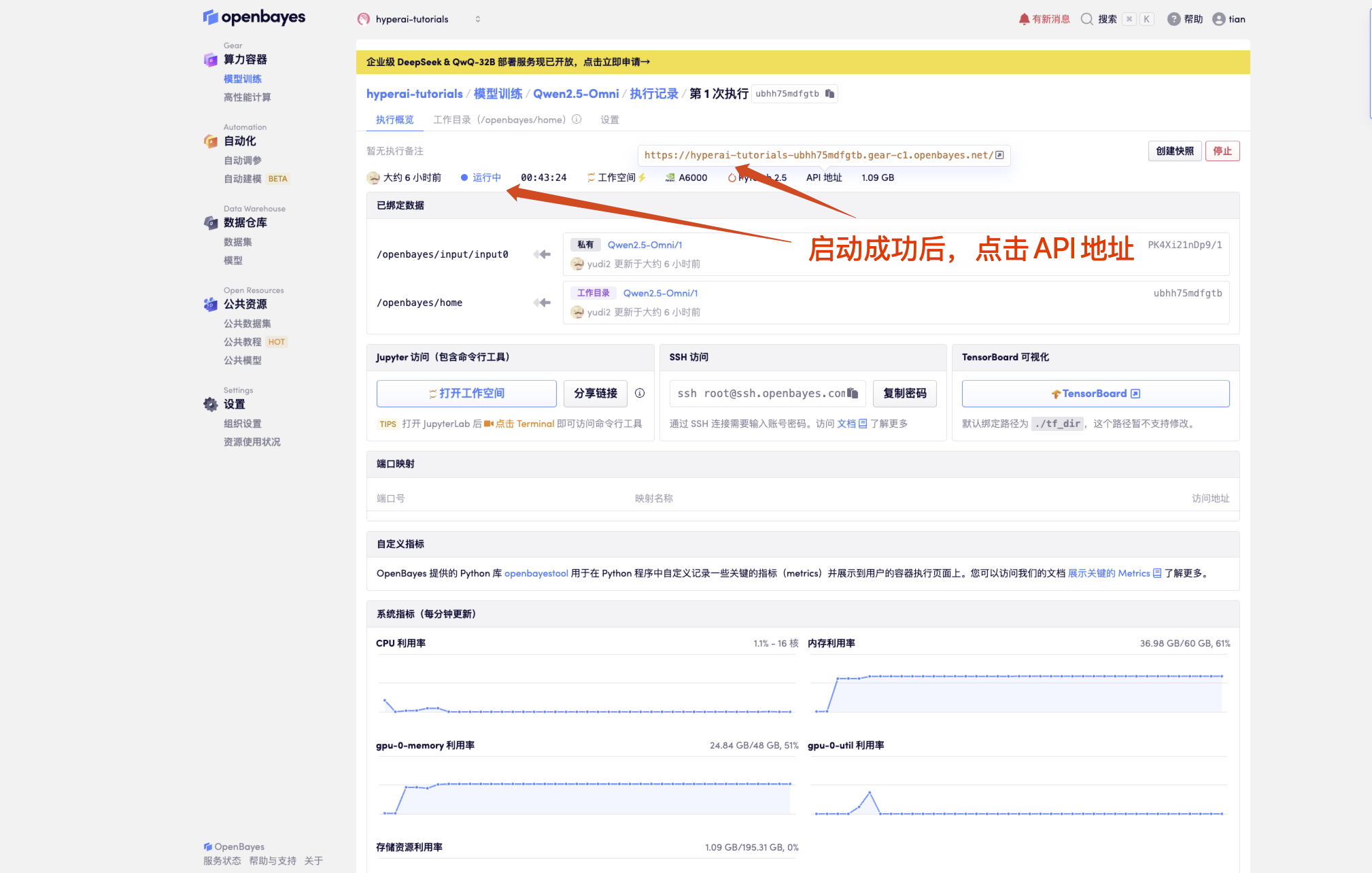
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Wenn das Eingabefeld orange ist, bedeutet dies, dass das Modell reagiert.
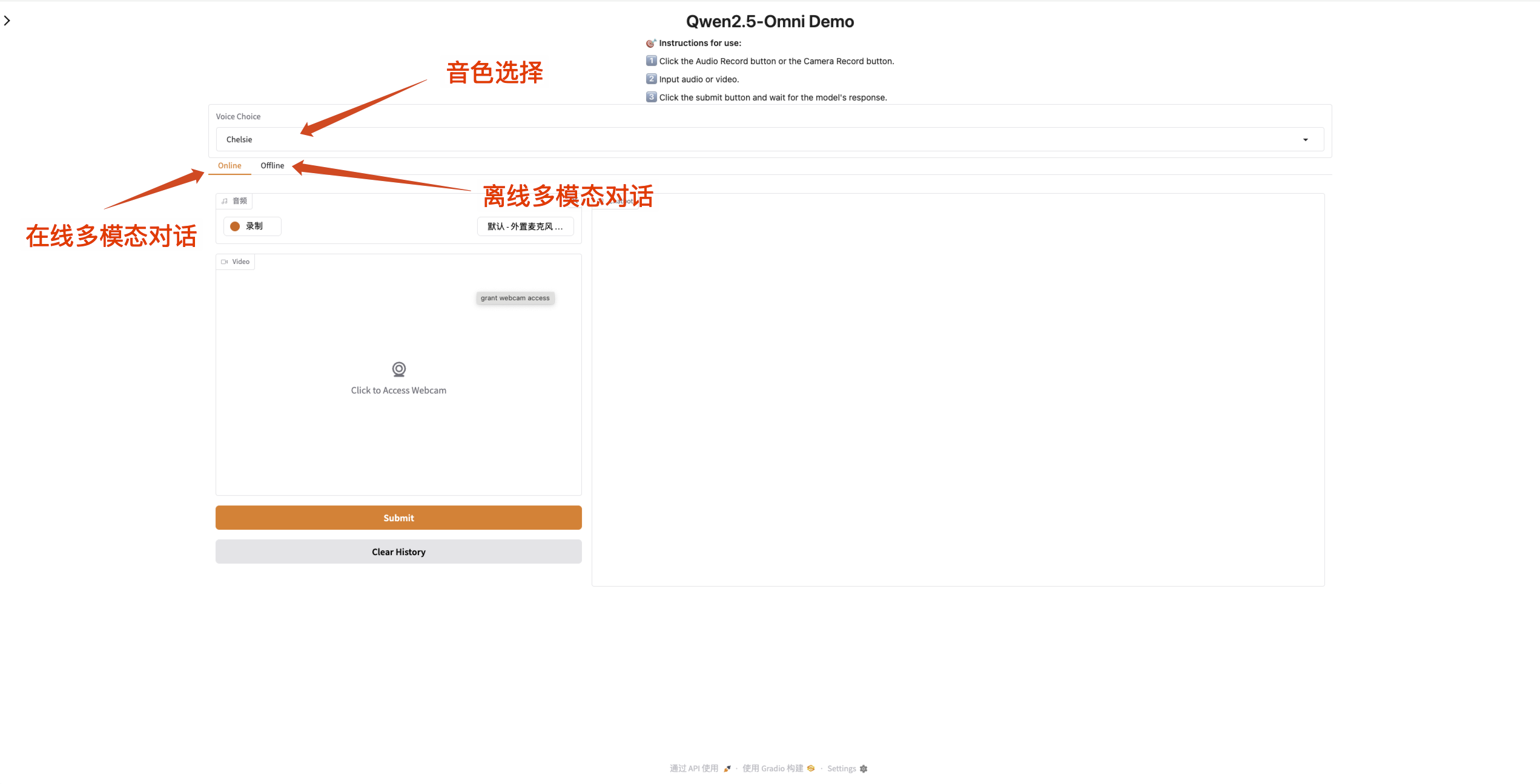
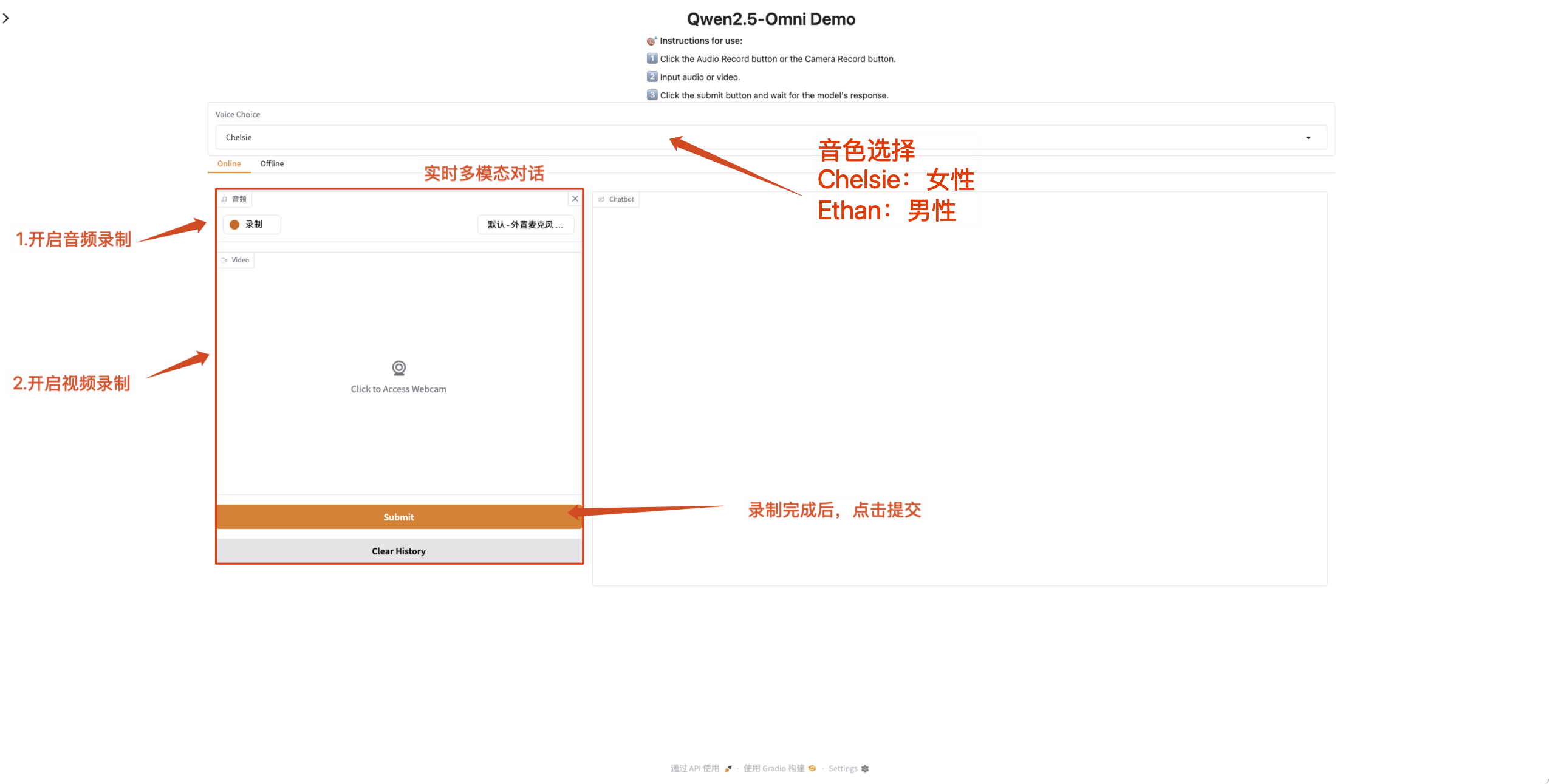
Qwen2.5-Omni unterstützt das Ändern des Tons der Audioausgabe. Der Prüfpunkt „Qwen/Qwen2.5-Omni-7B“ unterstützt die folgenden zwei Soundtypen:
| Tonart | Geschlecht | beschreiben |
|---|---|---|
| Chelsie | weiblich | Süß, sanft, hell, weich |
| Ethan | männlich | Sonnenschein, Vitalität, Leichtigkeit, Verbundenheit |
- Multimodaler Online-Dialog
Aktivieren Sie die Mikrofon- und Kameraberechtigungen auf der Webseite, damit Sie nach Abschluss der Aufnahme Echtzeitgespräche mit Qwen2.5-Omni führen können.
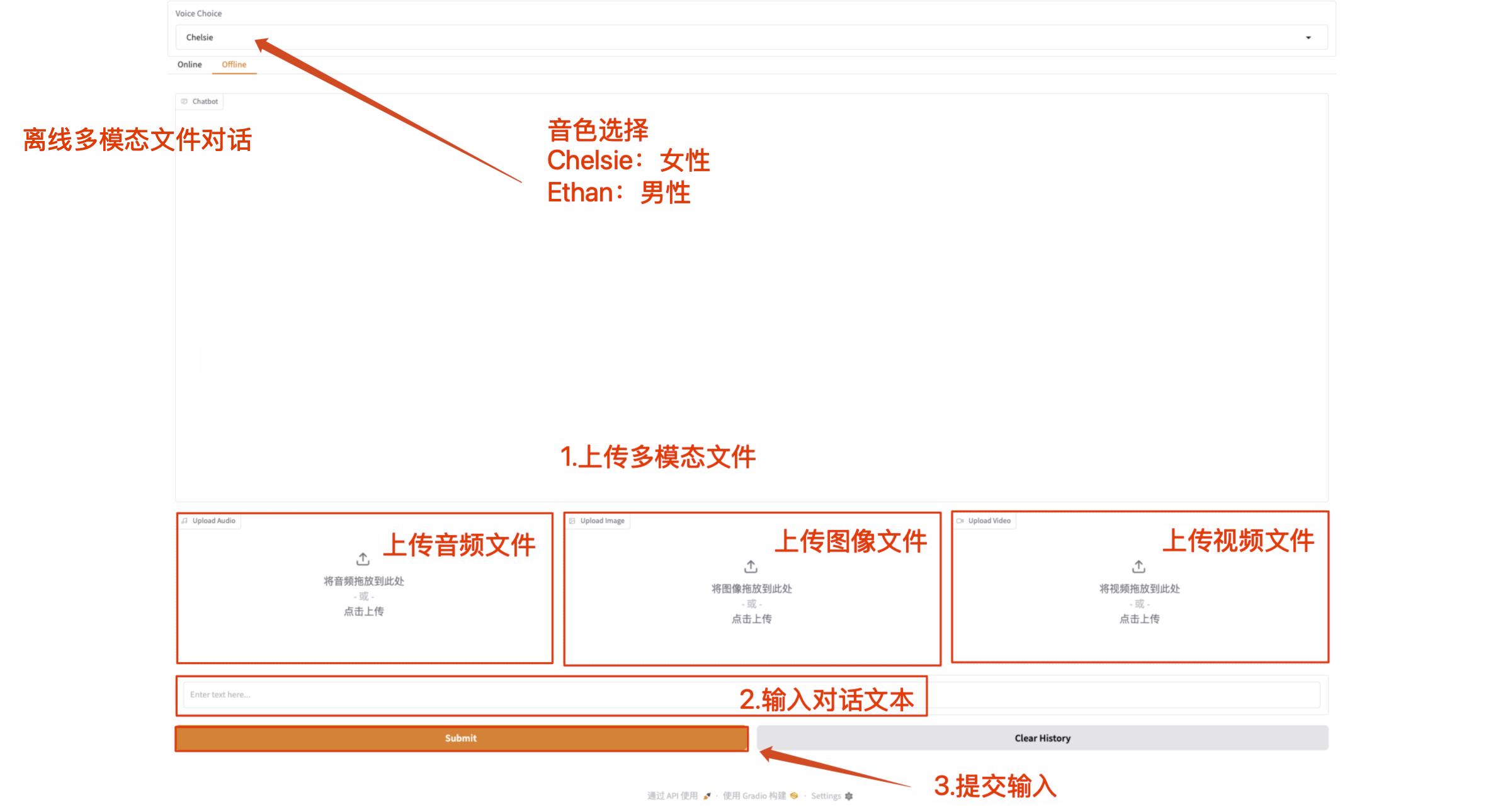
- Multimodale Offline-Konversation
Laden Sie multimodale Dateien direkt hoch und kommunizieren Sie mit Qwen2.5-Omni mit Textinhalten.
Hinweis: Die Videodatei muss Ton haben. Wenn kein Ton zu hören ist, wird eine Fehlermeldung angezeigt.
Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓ 
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.